 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Logical and Physical Layout Representations via Heterogeneous Graphs for Circuit Congestion Prediction
Mar 10, 2026As Very Large Scale Integration (VLSI) designs continue to scale in size and complexity, layout verification has become a central challenge in modern Electronic Design Automation (EDA) workflows. In practice, congestion can only be accurately identified after detailed routing, making traditional verification both time-consuming and costly. Learning-based approaches have therefore been explored to enable early-stage congestion prediction and reduce routing iterations. However, although prior methods incorporate both netlist connectivity and layout features, they often model the two in a loosely coupled manner and primarily produce numerical congestion estimates. We propose VeriHGN, a verification framework built on an enhanced heterogeneous graph that unifies circuit components and spatial grids into a single relational representation, enabling more faithful modeling of the interaction between logical intent and physical realization. Experiments on industrial benchmarks, including ISPD2015, CircuitNet-N14, and CircuitNet-N28, demonstrate consistent improvements over state-of-the-art methods in prediction accuracy and correlation metrics.
Anatomy of Agentic Memory: Taxonomy and Empirical Analysis of Evaluation and System Limitations
Feb 22, 2026Agentic memory systems enable large language model (LLM) agents to maintain state across long interactions, supporting long-horizon reasoning and personalization beyond fixed context windows. Despite rapid architectural development, the empirical foundations of these systems remain fragile: existing benchmarks are often underscaled, evaluation metrics are misaligned with semantic utility, performance varies significantly across backbone models, and system-level costs are frequently overlooked. This survey presents a structured analysis of agentic memory from both architectural and system perspectives. We first introduce a concise taxonomy of MAG systems based on four memory structures. Then, we analyze key pain points limiting current systems, including benchmark saturation effects, metric validity and judge sensitivity, backbone-dependent accuracy, and the latency and throughput overhead introduced by memory maintenance. By connecting the memory structure to empirical limitations, this survey clarifies why current agentic memory systems often underperform their theoretical promise and outlines directions for more reliable evaluation and scalable system design.
Hippocampus: An Efficient and Scalable Memory Module for Agentic AI
Feb 14, 2026Agentic AI require persistent memory to store user-specific histories beyond the limited context window of LLMs. Existing memory systems use dense vector databases or knowledge-graph traversal (or hybrid), incurring high retrieval latency and poor storage scalability. We introduce Hippocampus, an agentic memory management system that uses compact binary signatures for semantic search and lossless token-ID streams for exact content reconstruction. Its core is a Dynamic Wavelet Matrix (DWM) that compresses and co-indexes both streams to support ultra-fast search in the compressed domain, thus avoiding costly dense-vector or graph computations. This design scales linearly with memory size, making it suitable for long-horizon agentic deployments. Empirically, our evaluation shows that Hippocampus reduces end-to-end retrieval latency by up to 31$\times$ and cuts per-query token footprint by up to 14$\times$, while maintaining accuracy on both LoCoMo and LongMemEval benchmarks.
CoSA: Compressed Sensing-Based Adaptation of Large Language Models
Feb 05, 2026Parameter-Efficient Fine-Tuning (PEFT) has emerged as a practical paradigm for adapting large language models (LLMs) without updating all parameters. Most existing approaches, such as LoRA and PiSSA, rely on low-rank decompositions of weight updates. However, the low-rank assumption may restrict expressivity, particularly in task-specific adaptation scenarios where singular values are distributed relatively uniformly. To address this limitation, we propose CoSA (Compressed Sensing-Based Adaptation), a new PEFT method extended from compressed sensing theory. Instead of constraining weight updates to a low-rank subspace, CoSA expresses them through fixed random projection matrices and a compact learnable core. We provide a formal theoretical analysis of CoSA as a synthesis process, proving that weight updates can be compactly encoded into a low-dimensional space and mapped back through random projections. Extensive experimental results show that CoSA provides a principled perspective for efficient and expressive multi-scale model adaptation. Specifically, we evaluate CoSA on 10 diverse tasks, including natural language understanding and generation, employing 5 models of different scales from RoBERTa, Llama, and Qwen families. Across these settings, CoSA consistently matches or outperforms state-of-the-art PEFT methods.
MAGMA: A Multi-Graph based Agentic Memory Architecture for AI Agents
Jan 06, 2026Memory-Augmented Generation (MAG) extends Large Language Models with external memory to support long-context reasoning, but existing approaches largely rely on semantic similarity over monolithic memory stores, entangling temporal, causal, and entity information. This design limits interpretability and alignment between query intent and retrieved evidence, leading to suboptimal reasoning accuracy. In this paper, we propose MAGMA, a multi-graph agentic memory architecture that represents each memory item across orthogonal semantic, temporal, causal, and entity graphs. MAGMA formulates retrieval as policy-guided traversal over these relational views, enabling query-adaptive selection and structured context construction. By decoupling memory representation from retrieval logic, MAGMA provides transparent reasoning paths and fine-grained control over retrieval. Experiments on LoCoMo and LongMemEval demonstrate that MAGMA consistently outperforms state-of-the-art agentic memory systems in long-horizon reasoning tasks.
Analyzing 16,193 LLM Papers for Fun and Profits
Apr 15, 2025Large Language Models (LLMs) are reshaping the landscape of computer science research, driving significant shifts in research priorities across diverse conferences and fields. This study provides a comprehensive analysis of the publication trend of LLM-related papers in 77 top-tier computer science conferences over the past six years (2019-2024). We approach this analysis from four distinct perspectives: (1) We investigate how LLM research is driving topic shifts within major conferences. (2) We adopt a topic modeling approach to identify various areas of LLM-related topic growth and reveal the topics of concern at different conferences. (3) We explore distinct contribution patterns of academic and industrial institutions. (4) We study the influence of national origins on LLM development trajectories. Synthesizing the findings from these diverse analytical angles, we derive ten key insights that illuminate the dynamics and evolution of the LLM research ecosystem.
AdaCM$^2$: On Understanding Extremely Long-Term Video with Adaptive Cross-Modality Memory Reduction
Nov 19, 2024The advancements in large language models (LLMs) have propelled the improvement of video understanding tasks by incorporating LLMs with visual models. However, most existing LLM-based models (e.g., VideoLLaMA, VideoChat) are constrained to processing short-duration videos. Recent attempts to understand long-term videos by extracting and compressing visual features into a fixed memory size. Nevertheless, those methods leverage only visual modality to merge video tokens and overlook the correlation between visual and textual queries, leading to difficulties in effectively handling complex question-answering tasks. To address the challenges of long videos and complex prompts, we propose AdaCM$^2$, which, for the first time, introduces an adaptive cross-modality memory reduction approach to video-text alignment in an auto-regressive manner on video streams. Our extensive experiments on various video understanding tasks, such as video captioning, video question answering, and video classification, demonstrate that AdaCM$^2$ achieves state-of-the-art performance across multiple datasets while significantly reducing memory usage. Notably, it achieves a 4.5% improvement across multiple tasks in the LVU dataset with a GPU memory consumption reduction of up to 65%.
YOSO: You-Only-Sample-Once via Compressed Sensing for Graph Neural Network Training
Nov 08, 2024

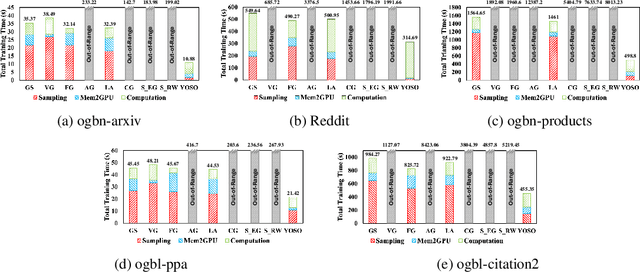

Graph neural networks (GNNs) have become essential tools for analyzing non-Euclidean data across various domains. During training stage, sampling plays an important role in reducing latency by limiting the number of nodes processed, particularly in large-scale applications. However, as the demand for better prediction performance grows, existing sampling algorithms become increasingly complex, leading to significant overhead. To mitigate this, we propose YOSO (You-Only-Sample-Once), an algorithm designed to achieve efficient training while preserving prediction accuracy. YOSO introduces a compressed sensing (CS)-based sampling and reconstruction framework, where nodes are sampled once at input layer, followed by a lossless reconstruction at the output layer per epoch. By integrating the reconstruction process with the loss function of specific learning tasks, YOSO not only avoids costly computations in traditional compressed sensing (CS) methods, such as orthonormal basis calculations, but also ensures high-probability accuracy retention which equivalent to full node participation. Experimental results on node classification and link prediction demonstrate the effectiveness and efficiency of YOSO, reducing GNN training by an average of 75\% compared to state-of-the-art methods, while maintaining accuracy on par with top-performing baselines.
BSC: Block-based Stochastic Computing to Enable Accurate and Efficient TinyML
Nov 12, 2021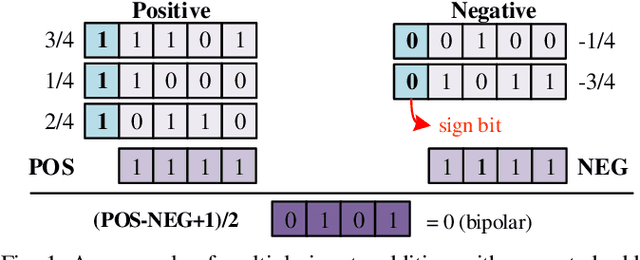
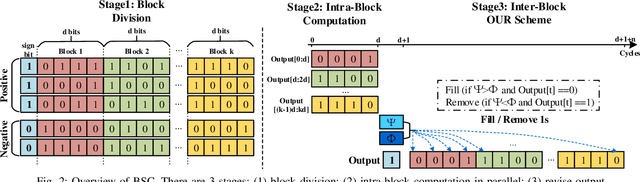
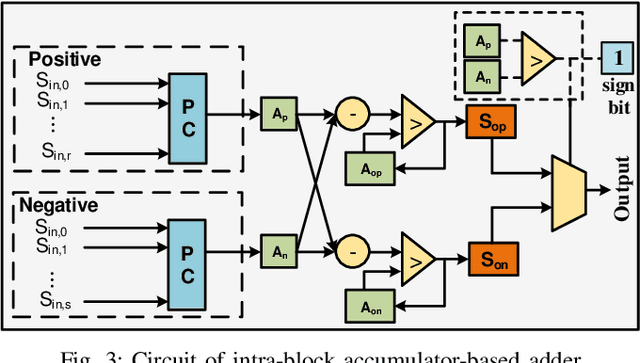
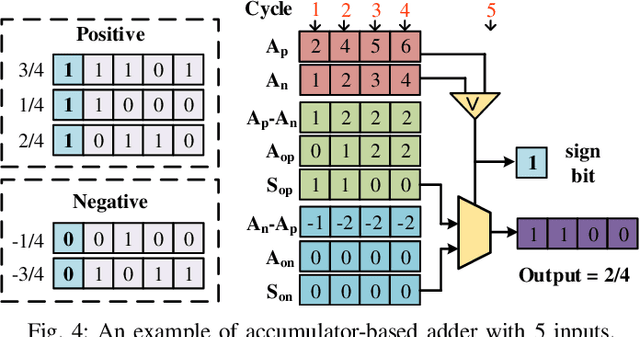
Along with the progress of AI democratization, machine learning (ML) has been successfully applied to edge applications, such as smart phones and automated driving. Nowadays, more applications require ML on tiny devices with extremely limited resources, like implantable cardioverter defibrillator (ICD), which is known as TinyML. Unlike ML on the edge, TinyML with a limited energy supply has higher demands on low-power execution. Stochastic computing (SC) using bitstreams for data representation is promising for TinyML since it can perform the fundamental ML operations using simple logical gates, instead of the complicated binary adder and multiplier. However, SC commonly suffers from low accuracy for ML tasks due to low data precision and inaccuracy of arithmetic units. Increasing the length of the bitstream in the existing works can mitigate the precision issue but incur higher latency. In this work, we propose a novel SC architecture, namely Block-based Stochastic Computing (BSC). BSC divides inputs into blocks, such that the latency can be reduced by exploiting high data parallelism. Moreover, optimized arithmetic units and output revision (OUR) scheme are proposed to improve accuracy. On top of it, a global optimization approach is devised to determine the number of blocks, which can make a better latency-power trade-off. Experimental results show that BSC can outperform the existing designs in achieving over 10% higher accuracy on ML tasks and over 6 times power reduction.