 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent-VStream: Event-Driven Real-Time Understanding for Long Video Streams
Jan 22, 2026Real-time understanding of long video streams remains challenging for multimodal large language models (VLMs) due to redundant frame processing and rapid forgetting of past context. Existing streaming systems rely on fixed-interval decoding or cache pruning, which either produce repetitive outputs or discard crucial temporal information. We introduce Event-VStream, an event-aware framework that represents continuous video as a sequence of discrete, semantically coherent events. Our system detects meaningful state transitions by integrating motion, semantic, and predictive cues, and triggers language generation only at those boundaries. Each event embedding is consolidated into a persistent memory bank, enabling long-horizon reasoning while maintaining low latency. Across OVOBench-Realtime, and long-form Ego4D evaluations, Event-VStream achieves competitive performance. It improves over a VideoLLM-Online-8B baseline by +10.4 points on OVOBench-Realtime, achieves performance close to Flash-VStream-7B despite using only a general-purpose LLaMA-3-8B text backbone, and maintains around 70% GPT-5 win rate on 2-hour Ego4D streams.
SDiT: Semantic Region-Adaptive for Diffusion Transformers
Jan 18, 2026Diffusion Transformers (DiTs) achieve state-of-the-art performance in text-to-image synthesis but remain computationally expensive due to the iterative nature of denoising and the quadratic cost of global attention. In this work, we observe that denoising dynamics are spatially non-uniform-background regions converge rapidly while edges and textured areas evolve much more actively. Building on this insight, we propose SDiT, a Semantic Region-Adaptive Diffusion Transformer that allocates computation according to regional complexity. SDiT introduces a training-free framework combining (1) semantic-aware clustering via fast Quickshift-based segmentation, (2) complexity-driven regional scheduling to selectively update informative areas, and (3) boundary-aware refinement to maintain spatial coherence. Without any model retraining or architectural modification, SDiT achieves up to 3.0x acceleration while preserving nearly identical perceptual and semantic quality to full-attention inference.
GFormer: Accelerating Large Language Models with Optimized Transformers on Gaudi Processors
Dec 19, 2024



Heterogeneous hardware like Gaudi processor has been developed to enhance computations, especially matrix operations for Transformer-based large language models (LLMs) for generative AI tasks. However, our analysis indicates that Transformers are not fully optimized on such emerging hardware, primarily due to inadequate optimizations in non-matrix computational kernels like Softmax and in heterogeneous resource utilization, particularly when processing long sequences. To address these issues, we propose an integrated approach (called GFormer) that merges sparse and linear attention mechanisms. GFormer aims to maximize the computational capabilities of the Gaudi processor's Matrix Multiplication Engine (MME) and Tensor Processing Cores (TPC) without compromising model quality. GFormer includes a windowed self-attention kernel and an efficient outer product kernel for causal linear attention, aiming to optimize LLM inference on Gaudi processors. Evaluation shows that GFormer significantly improves efficiency and model performance across various tasks on the Gaudi processor and outperforms state-of-the-art GPUs.
AdaCM$^2$: On Understanding Extremely Long-Term Video with Adaptive Cross-Modality Memory Reduction
Nov 19, 2024The advancements in large language models (LLMs) have propelled the improvement of video understanding tasks by incorporating LLMs with visual models. However, most existing LLM-based models (e.g., VideoLLaMA, VideoChat) are constrained to processing short-duration videos. Recent attempts to understand long-term videos by extracting and compressing visual features into a fixed memory size. Nevertheless, those methods leverage only visual modality to merge video tokens and overlook the correlation between visual and textual queries, leading to difficulties in effectively handling complex question-answering tasks. To address the challenges of long videos and complex prompts, we propose AdaCM$^2$, which, for the first time, introduces an adaptive cross-modality memory reduction approach to video-text alignment in an auto-regressive manner on video streams. Our extensive experiments on various video understanding tasks, such as video captioning, video question answering, and video classification, demonstrate that AdaCM$^2$ achieves state-of-the-art performance across multiple datasets while significantly reducing memory usage. Notably, it achieves a 4.5% improvement across multiple tasks in the LVU dataset with a GPU memory consumption reduction of up to 65%.
SDP4Bit: Toward 4-bit Communication Quantization in Sharded Data Parallelism for LLM Training
Oct 20, 2024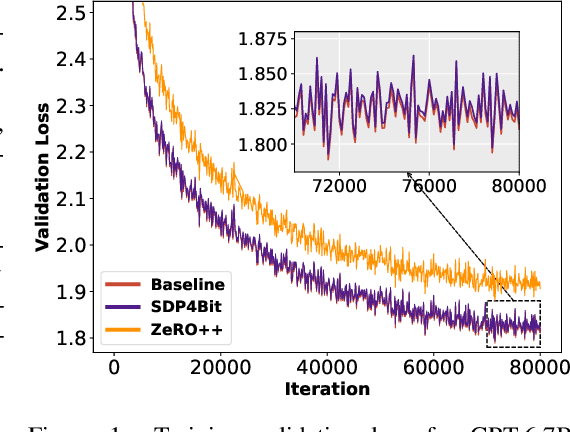
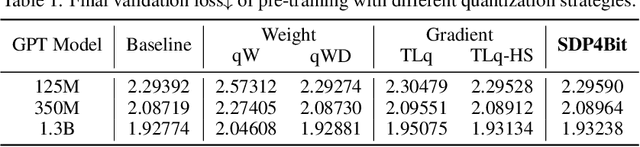
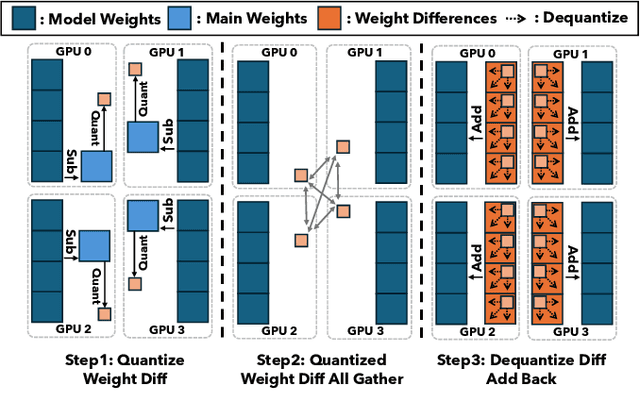
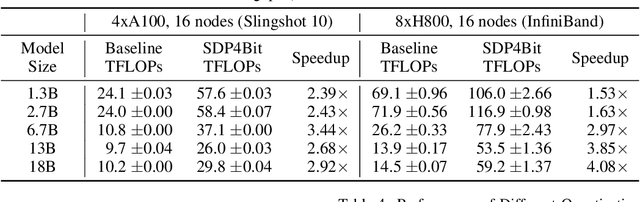
Recent years have witnessed a clear trend towards language models with an ever-increasing number of parameters, as well as the growing training overhead and memory usage. Distributed training, particularly through Sharded Data Parallelism (ShardedDP) which partitions optimizer states among workers, has emerged as a crucial technique to mitigate training time and memory usage. Yet, a major challenge in the scalability of ShardedDP is the intensive communication of weights and gradients. While compression techniques can alleviate this issue, they often result in worse accuracy. Driven by this limitation, we propose SDP4Bit (Toward 4Bit Communication Quantization in Sharded Data Parallelism for LLM Training), which effectively reduces the communication of weights and gradients to nearly 4 bits via two novel techniques: quantization on weight differences, and two-level gradient smooth quantization. Furthermore, SDP4Bit presents an algorithm-system co-design with runtime optimization to minimize the computation overhead of compression. In addition to the theoretical guarantees of convergence, we empirically evaluate the accuracy of SDP4Bit on the pre-training of GPT models with up to 6.7 billion parameters, and the results demonstrate a negligible impact on training loss. Furthermore, speed experiments show that SDP4Bit achieves up to 4.08$\times$ speedup in end-to-end throughput on a scale of 128 GPUs.
DeepSpeed4Science Initiative: Enabling Large-Scale Scientific Discovery through Sophisticated AI System Technologies
Oct 11, 2023



In the upcoming decade, deep learning may revolutionize the natural sciences, enhancing our capacity to model and predict natural occurrences. This could herald a new era of scientific exploration, bringing significant advancements across sectors from drug development to renewable energy. To answer this call, we present DeepSpeed4Science initiative (deepspeed4science.ai) which aims to build unique capabilities through AI system technology innovations to help domain experts to unlock today's biggest science mysteries. By leveraging DeepSpeed's current technology pillars (training, inference and compression) as base technology enablers, DeepSpeed4Science will create a new set of AI system technologies tailored for accelerating scientific discoveries by addressing their unique complexity beyond the common technical approaches used for accelerating generic large language models (LLMs). In this paper, we showcase the early progress we made with DeepSpeed4Science in addressing two of the critical system challenges in structural biology research.
Benchmarking and In-depth Performance Study of Large Language Models on Habana Gaudi Processors
Sep 29, 2023

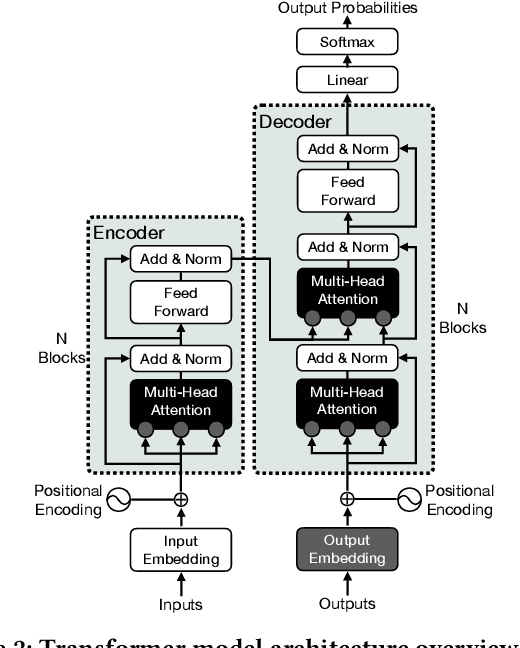

Transformer models have achieved remarkable success in various machine learning tasks but suffer from high computational complexity and resource requirements. The quadratic complexity of the self-attention mechanism further exacerbates these challenges when dealing with long sequences and large datasets. Specialized AI hardware accelerators, such as the Habana GAUDI architecture, offer a promising solution to tackle these issues. GAUDI features a Matrix Multiplication Engine (MME) and a cluster of fully programmable Tensor Processing Cores (TPC). This paper explores the untapped potential of using GAUDI processors to accelerate Transformer-based models, addressing key challenges in the process. Firstly, we provide a comprehensive performance comparison between the MME and TPC components, illuminating their relative strengths and weaknesses. Secondly, we explore strategies to optimize MME and TPC utilization, offering practical insights to enhance computational efficiency. Thirdly, we evaluate the performance of Transformers on GAUDI, particularly in handling long sequences and uncovering performance bottlenecks. Lastly, we evaluate the end-to-end performance of two Transformer-based large language models (LLM) on GAUDI. The contributions of this work encompass practical insights for practitioners and researchers alike. We delve into GAUDI's capabilities for Transformers through systematic profiling, analysis, and optimization exploration. Our study bridges a research gap and offers a roadmap for optimizing Transformer-based model training on the GAUDI architecture.
DeepSpeed Ulysses: System Optimizations for Enabling Training of Extreme Long Sequence Transformer Models
Sep 25, 2023



Computation in a typical Transformer-based large language model (LLM) can be characterized by batch size, hidden dimension, number of layers, and sequence length. Until now, system works for accelerating LLM training have focused on the first three dimensions: data parallelism for batch size, tensor parallelism for hidden size and pipeline parallelism for model depth or layers. These widely studied forms of parallelism are not targeted or optimized for long sequence Transformer models. Given practical application needs for long sequence LLM, renewed attentions are being drawn to sequence parallelism. However, existing works in sequence parallelism are constrained by memory-communication inefficiency, limiting their scalability to long sequence large models. In this work, we introduce DeepSpeed-Ulysses, a novel, portable and effective methodology for enabling highly efficient and scalable LLM training with extremely long sequence length. DeepSpeed-Ulysses at its core partitions input data along the sequence dimension and employs an efficient all-to-all collective communication for attention computation. Theoretical communication analysis shows that whereas other methods incur communication overhead as sequence length increases, DeepSpeed-Ulysses maintains constant communication volume when sequence length and compute devices are increased proportionally. Furthermore, experimental evaluations show that DeepSpeed-Ulysses trains 2.5X faster with 4X longer sequence length than the existing method SOTA baseline.
PapagAI:Automated Feedback for Reflective Essays
Jul 10, 2023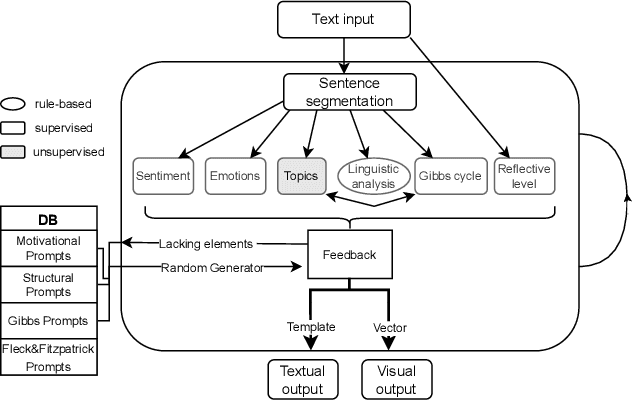



Written reflective practice is a regular exercise pre-service teachers perform during their higher education. Usually, their lecturers are expected to provide individual feedback, which can be a challenging task to perform on a regular basis. In this paper, we present the first open-source automated feedback tool based on didactic theory and implemented as a hybrid AI system. We describe the components and discuss the advantages and disadvantages of our system compared to the state-of-art generative large language models. The main objective of our work is to enable better learning outcomes for students and to complement the teaching activities of lecturers.
HEAT: A Highly Efficient and Affordable Training System for Collaborative Filtering Based Recommendation on CPUs
May 03, 2023



Collaborative filtering (CF) has been proven to be one of the most effective techniques for recommendation. Among all CF approaches, SimpleX is the state-of-the-art method that adopts a novel loss function and a proper number of negative samples. However, there is no work that optimizes SimpleX on multi-core CPUs, leading to limited performance. To this end, we perform an in-depth profiling and analysis of existing SimpleX implementations and identify their performance bottlenecks including (1) irregular memory accesses, (2) unnecessary memory copies, and (3) redundant computations. To address these issues, we propose an efficient CF training system (called HEAT) that fully enables the multi-level caching and multi-threading capabilities of modern CPUs. Specifically, the optimization of HEAT is threefold: (1) It tiles the embedding matrix to increase data locality and reduce cache misses (thus reduces read latency); (2) It optimizes stochastic gradient descent (SGD) with sampling by parallelizing vector products instead of matrix-matrix multiplications, in particular the similarity computation therein, to avoid memory copies for matrix data preparation; and (3) It aggressively reuses intermediate results from the forward phase in the backward phase to alleviate redundant computation. Evaluation on five widely used datasets with both x86- and ARM-architecture processors shows that HEAT achieves up to 45.2X speedup over existing CPU solution and 4.5X speedup and 7.9X cost reduction in Cloud over existing GPU solution with NVIDIA V100 GPU.