 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent-VStream: Event-Driven Real-Time Understanding for Long Video Streams
Jan 22, 2026Real-time understanding of long video streams remains challenging for multimodal large language models (VLMs) due to redundant frame processing and rapid forgetting of past context. Existing streaming systems rely on fixed-interval decoding or cache pruning, which either produce repetitive outputs or discard crucial temporal information. We introduce Event-VStream, an event-aware framework that represents continuous video as a sequence of discrete, semantically coherent events. Our system detects meaningful state transitions by integrating motion, semantic, and predictive cues, and triggers language generation only at those boundaries. Each event embedding is consolidated into a persistent memory bank, enabling long-horizon reasoning while maintaining low latency. Across OVOBench-Realtime, and long-form Ego4D evaluations, Event-VStream achieves competitive performance. It improves over a VideoLLM-Online-8B baseline by +10.4 points on OVOBench-Realtime, achieves performance close to Flash-VStream-7B despite using only a general-purpose LLaMA-3-8B text backbone, and maintains around 70% GPT-5 win rate on 2-hour Ego4D streams.
PackKV: Reducing KV Cache Memory Footprint through LLM-Aware Lossy Compression
Dec 30, 2025Transformer-based large language models (LLMs) have demonstrated remarkable potential across a wide range of practical applications. However, long-context inference remains a significant challenge due to the substantial memory requirements of the key-value (KV) cache, which can scale to several gigabytes as sequence length and batch size increase. In this paper, we present \textbf{PackKV}, a generic and efficient KV cache management framework optimized for long-context generation. %, which synergistically supports both latency-critical and throughput-critical inference scenarios. PackKV introduces novel lossy compression techniques specifically tailored to the characteristics of KV cache data, featuring a careful co-design of compression algorithms and system architecture. Our approach is compatible with the dynamically growing nature of the KV cache while preserving high computational efficiency. Experimental results show that, under the same and minimum accuracy drop as state-of-the-art quantization methods, PackKV achieves, on average, \textbf{153.2}\% higher memory reduction rate for the K cache and \textbf{179.6}\% for the V cache. Furthermore, PackKV delivers extremely high execution throughput, effectively eliminating decompression overhead and accelerating the matrix-vector multiplication operation. Specifically, PackKV achieves an average throughput improvement of \textbf{75.7}\% for K and \textbf{171.7}\% for V across A100 and RTX Pro 6000 GPUs, compared to cuBLAS matrix-vector multiplication kernels, while demanding less GPU memory bandwidth. Code available on https://github.com/BoJiang03/PackKV
Enhancing Lossy Compression Through Cross-Field Information for Scientific Applications
Sep 26, 2024



Lossy compression is one of the most effective methods for reducing the size of scientific data containing multiple data fields. It reduces information density through prediction or transformation techniques to compress the data. Previous approaches use local information from a single target field when predicting target data points, limiting their potential to achieve higher compression ratios. In this paper, we identified significant cross-field correlations within scientific datasets. We propose a novel hybrid prediction model that utilizes CNN to extract cross-field information and combine it with existing local field information. Our solution enhances the prediction accuracy of lossy compressors, leading to improved compression ratios without compromising data quality. We evaluate our solution on three scientific datasets, demonstrating its ability to improve compression ratios by up to 25% under specific error bounds. Additionally, our solution preserves more data details and reduces artifacts compared to baseline approaches.
NeurLZ: On Enhancing Lossy Compression Performance based on Error-Controlled Neural Learning for Scientific Data
Sep 10, 2024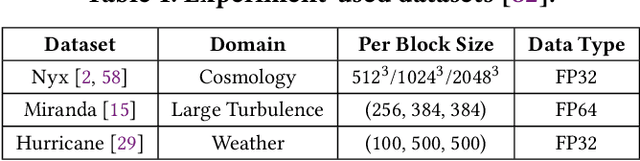



Large-scale scientific simulations generate massive datasets that pose significant challenges for storage and I/O. While traditional lossy compression techniques can improve performance, balancing compression ratio, data quality, and throughput remains difficult. To address this, we propose NeurLZ, a novel cross-field learning-based and error-controlled compression framework for scientific data. By integrating skipping DNN models, cross-field learning, and error control, our framework aims to substantially enhance lossy compression performance. Our contributions are three-fold: (1) We design a lightweight skipping model to provide high-fidelity detail retention, further improving prediction accuracy. (2) We adopt a cross-field learning approach to significantly improve data prediction accuracy, resulting in a substantially improved compression ratio. (3) We develop an error control approach to provide strict error bounds according to user requirements. We evaluated NeurLZ on several real-world HPC application datasets, including Nyx (cosmological simulation), Miranda (large turbulence simulation), and Hurricane (weather simulation). Experiments demonstrate that our framework achieves up to a 90% relative reduction in bit rate under the same data distortion, compared to the best existing approach.
Revisiting Multi-User Downlink in IEEE 802.11ax: A Designers Guide to MU-MIMO
Jun 09, 2024Downlink (DL) Multi-User (MU) Multiple Input Multiple Output (MU-MIMO) is a key technology that allows multiple concurrent data transmissions from an Access Point (AP) to a selected sub-set of clients for higher network efficiency in IEEE 802.11ax. However, DL MU-MIMO feature is typically turned off as the default setting in AP vendors' products, that is, turning on the DL MU-MIMO may not help increase the network efficiency, which is counter-intuitive. In this article, we provide a sufficiently deep understanding of the interplay between the various underlying factors, i.e., CSI overhead and spatial correlation, which result in negative results when turning on the DL MU-MIMO. Furthermore, we provide a fundamental guideline as a function of operational scenarios to address the fundamental question "when the DL MU-MIMO should be turned on/off".
GWLZ: A Group-wise Learning-based Lossy Compression Framework for Scientific Data
Apr 20, 2024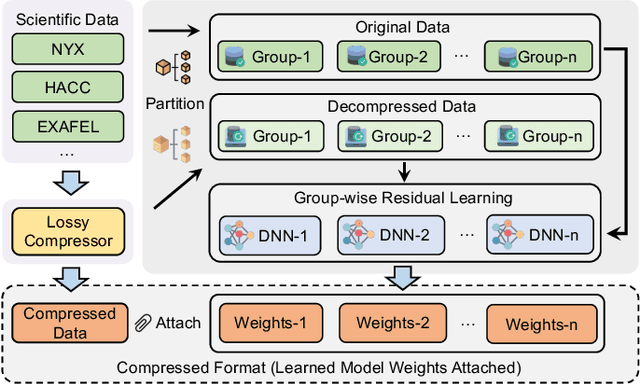

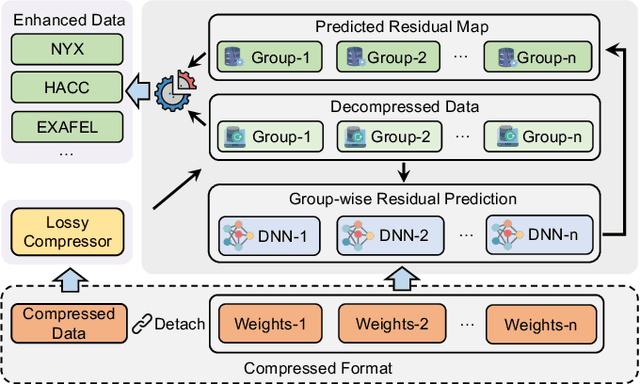
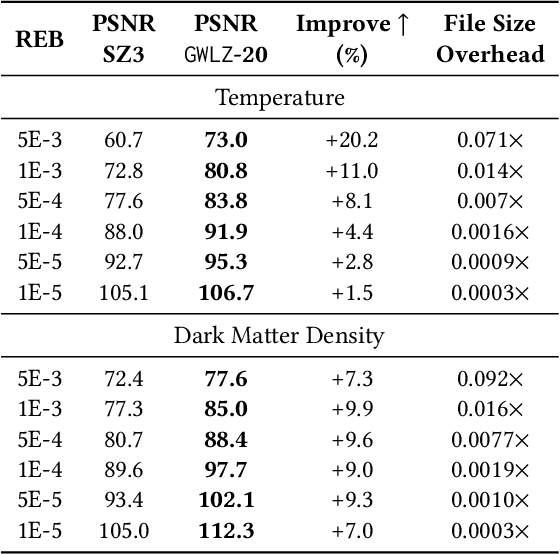
The rapid expansion of computational capabilities and the ever-growing scale of modern HPC systems present formidable challenges in managing exascale scientific data. Faced with such vast datasets, traditional lossless compression techniques prove insufficient in reducing data size to a manageable level while preserving all information intact. In response, researchers have turned to error-bounded lossy compression methods, which offer a balance between data size reduction and information retention. However, despite their utility, these compressors employing conventional techniques struggle with limited reconstruction quality. To address this issue, we draw inspiration from recent advancements in deep learning and propose GWLZ, a novel group-wise learning-based lossy compression framework with multiple lightweight learnable enhancer models. Leveraging a group of neural networks, GWLZ significantly enhances the decompressed data reconstruction quality with negligible impact on the compression efficiency. Experimental results on different fields from the Nyx dataset demonstrate remarkable improvements by GWLZ, achieving up to 20% quality enhancements with negligible overhead as low as 0.0003x.
SRN-SZ: Deep Leaning-Based Scientific Error-bounded Lossy Compression with Super-resolution Neural Networks
Sep 07, 2023



The fast growth of computational power and scales of modern super-computing systems have raised great challenges for the management of exascale scientific data. To maintain the usability of scientific data, error-bound lossy compression is proposed and developed as an essential technique for the size reduction of scientific data with constrained data distortion. Among the diverse datasets generated by various scientific simulations, certain datasets cannot be effectively compressed by existing error-bounded lossy compressors with traditional techniques. The recent success of Artificial Intelligence has inspired several researchers to integrate neural networks into error-bounded lossy compressors. However, those works still suffer from limited compression ratios and/or extremely low efficiencies. To address those issues and improve the compression on the hard-to-compress datasets, in this paper, we propose SRN-SZ, which is a deep learning-based scientific error-bounded lossy compressor leveraging the hierarchical data grid expansion paradigm implemented by super-resolution neural networks. SRN-SZ applies the most advanced super-resolution network HAT for its compression, which is free of time-costing per-data training. In experiments compared with various state-of-the-art compressors, SRN-SZ achieves up to 75% compression ratio improvements under the same error bound and up to 80% compression ratio improvements under the same PSNR than the second-best compressor.
Mutual Interference Mitigation for MIMO-FMCW Automotive Radar
Apr 06, 2023



This paper considers mutual interference mitigation among automotive radars using frequency-modulated continuous wave (FMCW) signal and multiple-input multiple-output (MIMO) virtual arrays. For the first time, we derive a general interference signal model that fully accounts for not only the time-frequency incoherence, e.g., different FMCW configuration parameters and time offsets, but also the slow-time code MIMO incoherence and array configuration differences between the victim and interfering radars. Along with a standard MIMO-FMCW object signal model, we turn the interference mitigation into a spatial-domain object detection under incoherent MIMO-FMCW interference described by the explicit interference signal model, and propose a constant false alarm rate (CFAR) detector. More specifically, the proposed detector exploits the structural property of the derived interference model at both \emph{transmit} and \emph{receive} steering vector space. We also derive analytical closed-form expressions for probabilities of detection and false alarm. Performance evaluation using both synthetic-level and phased array system-level simulation confirms the effectiveness of our proposed detector over selected baseline methods.
SOLAR: A Highly Optimized Data Loading Framework for Distributed Training of CNN-based Scientific Surrogates
Nov 04, 2022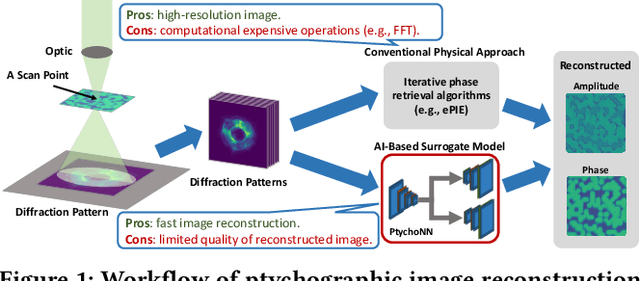
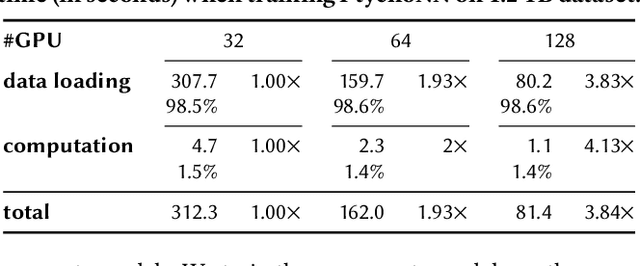
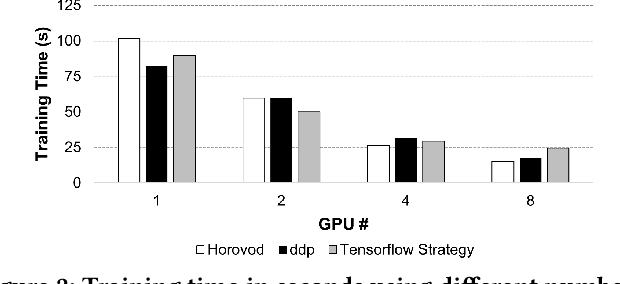

CNN-based surrogates have become prevalent in scientific applications to replace conventional time-consuming physical approaches. Although these surrogates can yield satisfactory results with significantly lower computation costs over small training datasets, our benchmarking results show that data-loading overhead becomes the major performance bottleneck when training surrogates with large datasets. In practice, surrogates are usually trained with high-resolution scientific data, which can easily reach the terabyte scale. Several state-of-the-art data loaders are proposed to improve the loading throughput in general CNN training; however, they are sub-optimal when applied to the surrogate training. In this work, we propose SOLAR, a surrogate data loader, that can ultimately increase loading throughput during the training. It leverages our three key observations during the benchmarking and contains three novel designs. Specifically, SOLAR first generates a pre-determined shuffled index list and accordingly optimizes the global access order and the buffer eviction scheme to maximize the data reuse and the buffer hit rate. It then proposes a tradeoff between lightweight computational imbalance and heavyweight loading workload imbalance to speed up the overall training. It finally optimizes its data access pattern with HDF5 to achieve a better parallel I/O throughput. Our evaluation with three scientific surrogates and 32 GPUs illustrates that SOLAR can achieve up to 24.4X speedup over PyTorch Data Loader and 3.52X speedup over state-of-the-art data loaders.
Efficient PHY Layer Abstraction under Imperfect Channel Estimation
May 24, 2022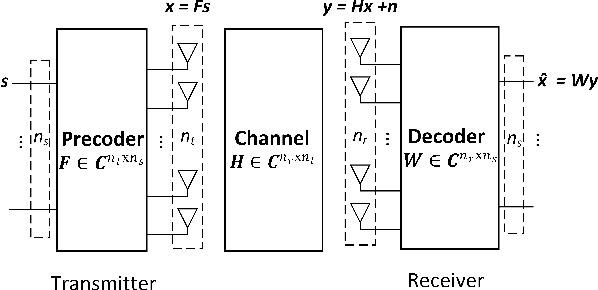
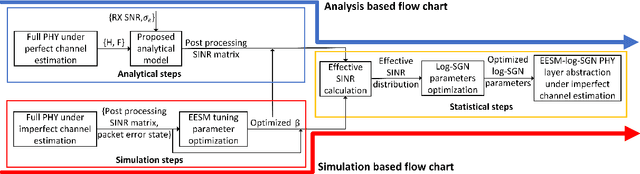
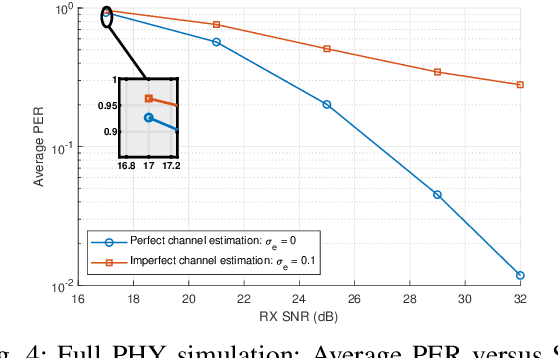
As network simulator has been suffering from the large computational complexity in the physical (PHY) layer, a PHY layer abstraction model that efficiently and accurately characterizes the PHY layer performance from the system level simulations is well-needed. However, most existing work investigate the PHY layer abstraction under an assumption of perfect channel estimation, as a result, such a model may become unreliable if there exists channel estimation error in a real communication system. This work improves an efficient PHY layer method, EESM-log-SGN PHY layer abstraction, by considering the presence of channel estimation error. We develop two methods for implementing the EESM-log-SGN PHY abstraction under imperfect channel estimation. Meanwhile, we present the derivation of effective Signal-to-Interference-plus-Noise-Ratio (SINR) for minimum mean squared error (MMSE) receivers impacted by the channel estimation error. Via full PHY simulations, we verify that the effective SINR is not impacted by the channel estimation error under multiple-input and single-output (MISO)/single-input and single-output (SISO) configuration. Finally, the developed methods are validated under different orthogonal frequency division multiplexing (OFDM) scenarios.