 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Communication in Deep Learning Recommendation Model Training with Dual-Level Adaptive Lossy Compression
Jul 05, 2024DLRM is a state-of-the-art recommendation system model that has gained widespread adoption across various industry applications. The large size of DLRM models, however, necessitates the use of multiple devices/GPUs for efficient training. A significant bottleneck in this process is the time-consuming all-to-all communication required to collect embedding data from all devices. To mitigate this, we introduce a method that employs error-bounded lossy compression to reduce the communication data size and accelerate DLRM training. We develop a novel error-bounded lossy compression algorithm, informed by an in-depth analysis of embedding data features, to achieve high compression ratios. Moreover, we introduce a dual-level adaptive strategy for error-bound adjustment, spanning both table-wise and iteration-wise aspects, to balance the compression benefits with the potential impacts on accuracy. We further optimize our compressor for PyTorch tensors on GPUs, minimizing compression overhead. Evaluation shows that our method achieves a 1.38$\times$ training speedup with a minimal accuracy impact.
HEAT: A Highly Efficient and Affordable Training System for Collaborative Filtering Based Recommendation on CPUs
May 03, 2023



Collaborative filtering (CF) has been proven to be one of the most effective techniques for recommendation. Among all CF approaches, SimpleX is the state-of-the-art method that adopts a novel loss function and a proper number of negative samples. However, there is no work that optimizes SimpleX on multi-core CPUs, leading to limited performance. To this end, we perform an in-depth profiling and analysis of existing SimpleX implementations and identify their performance bottlenecks including (1) irregular memory accesses, (2) unnecessary memory copies, and (3) redundant computations. To address these issues, we propose an efficient CF training system (called HEAT) that fully enables the multi-level caching and multi-threading capabilities of modern CPUs. Specifically, the optimization of HEAT is threefold: (1) It tiles the embedding matrix to increase data locality and reduce cache misses (thus reduces read latency); (2) It optimizes stochastic gradient descent (SGD) with sampling by parallelizing vector products instead of matrix-matrix multiplications, in particular the similarity computation therein, to avoid memory copies for matrix data preparation; and (3) It aggressively reuses intermediate results from the forward phase in the backward phase to alleviate redundant computation. Evaluation on five widely used datasets with both x86- and ARM-architecture processors shows that HEAT achieves up to 45.2X speedup over existing CPU solution and 4.5X speedup and 7.9X cost reduction in Cloud over existing GPU solution with NVIDIA V100 GPU.
SOLAR: A Highly Optimized Data Loading Framework for Distributed Training of CNN-based Scientific Surrogates
Nov 04, 2022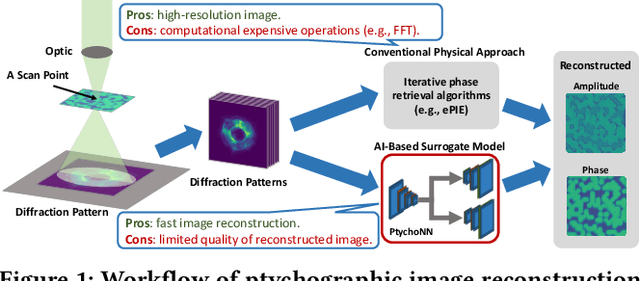
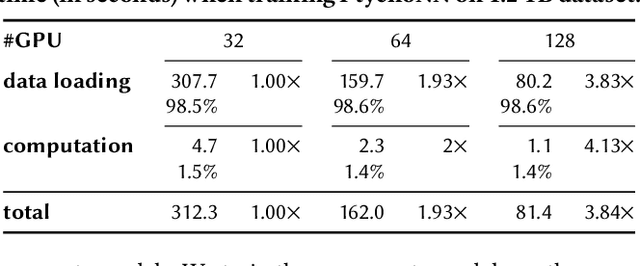
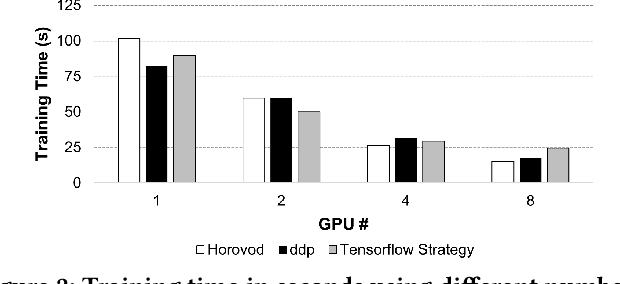

CNN-based surrogates have become prevalent in scientific applications to replace conventional time-consuming physical approaches. Although these surrogates can yield satisfactory results with significantly lower computation costs over small training datasets, our benchmarking results show that data-loading overhead becomes the major performance bottleneck when training surrogates with large datasets. In practice, surrogates are usually trained with high-resolution scientific data, which can easily reach the terabyte scale. Several state-of-the-art data loaders are proposed to improve the loading throughput in general CNN training; however, they are sub-optimal when applied to the surrogate training. In this work, we propose SOLAR, a surrogate data loader, that can ultimately increase loading throughput during the training. It leverages our three key observations during the benchmarking and contains three novel designs. Specifically, SOLAR first generates a pre-determined shuffled index list and accordingly optimizes the global access order and the buffer eviction scheme to maximize the data reuse and the buffer hit rate. It then proposes a tradeoff between lightweight computational imbalance and heavyweight loading workload imbalance to speed up the overall training. It finally optimizes its data access pattern with HDF5 to achieve a better parallel I/O throughput. Our evaluation with three scientific surrogates and 32 GPUs illustrates that SOLAR can achieve up to 24.4X speedup over PyTorch Data Loader and 3.52X speedup over state-of-the-art data loaders.
H-GCN: A Graph Convolutional Network Accelerator on Versal ACAP Architecture
Jun 28, 2022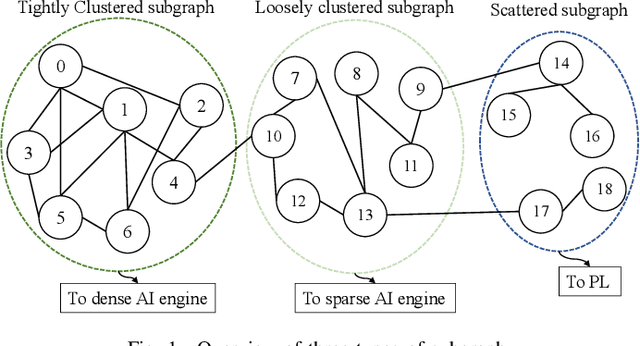
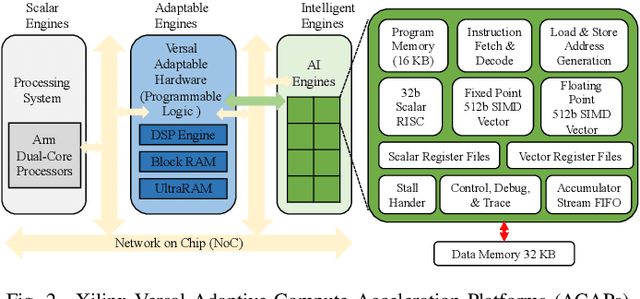
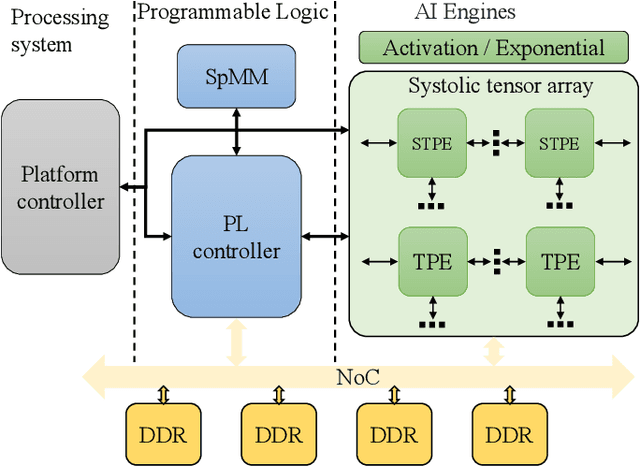
Graph Neural Networks (GNNs) have drawn tremendous attention due to their unique capability to extend Machine Learning (ML) approaches to applications broadly-defined as having unstructured data, especially graphs. Compared with other Machine Learning (ML) modalities, the acceleration of Graph Neural Networks (GNNs) is more challenging due to the irregularity and heterogeneity derived from graph typologies. Existing efforts, however, have focused mainly on handling graphs' irregularity and have not studied their heterogeneity. To this end we propose H-GCN, a PL (Programmable Logic) and AIE (AI Engine) based hybrid accelerator that leverages the emerging heterogeneity of Xilinx Versal Adaptive Compute Acceleration Platforms (ACAPs) to achieve high-performance GNN inference. In particular, H-GCN partitions each graph into three subgraphs based on its inherent heterogeneity, and processes them using PL and AIE, respectively. To further improve performance, we explore the sparsity support of AIE and develop an efficient density-aware method to automatically map tiles of sparse matrix-matrix multiplication (SpMM) onto the systolic tensor array. Compared with state-of-the-art GCN accelerators, H-GCN achieves, on average, speedups of 1.1~2.3X.
An Efficient End-to-End Deep Learning Training Framework via Fine-Grained Pattern-Based Pruning
Nov 20, 2020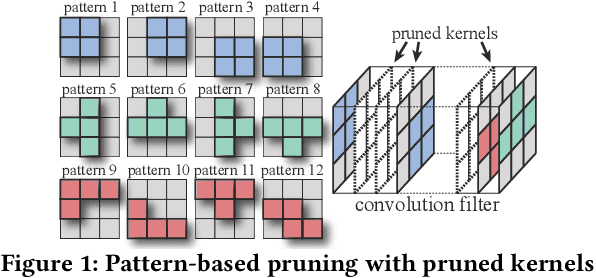
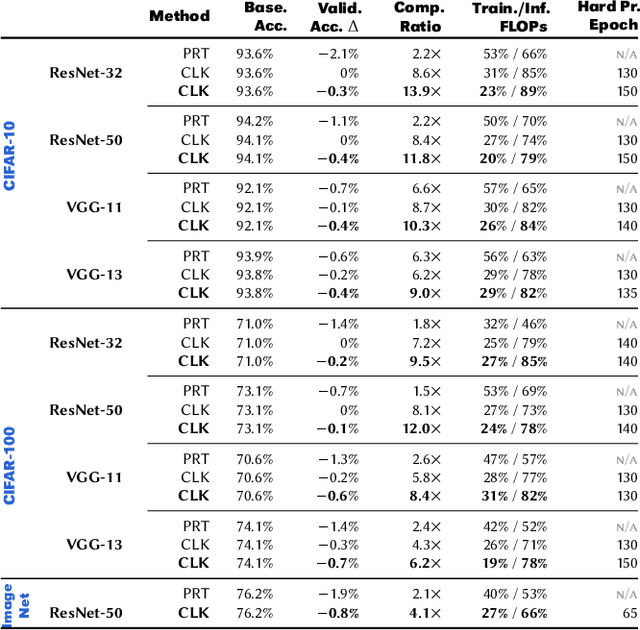
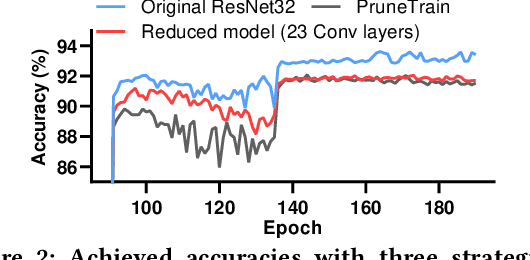
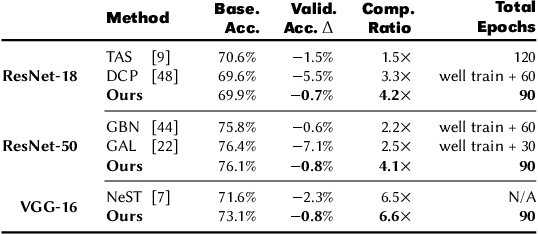
Convolutional neural networks (CNNs) are becoming increasingly deeper, wider, and non-linear because of the growing demand on prediction accuracy and analysis quality. The wide and deep CNNs, however, require a large amount of computing resources and processing time. Many previous works have studied model pruning to improve inference performance, but little work has been done for effectively reducing training cost. In this paper, we propose ClickTrain: an efficient and accurate end-to-end training and pruning framework for CNNs. Different from the existing pruning-during-training work, ClickTrain provides higher model accuracy and compression ratio via fine-grained architecture-preserving pruning. By leveraging pattern-based pruning with our proposed novel accurate weight importance estimation, dynamic pattern generation and selection, and compiler-assisted computation optimizations, ClickTrain generates highly accurate and fast pruned CNN models for direct deployment without any time overhead, compared with the baseline training. ClickTrain also reduces the end-to-end time cost of the state-of-the-art pruning-after-training methods by up to about 67% with comparable accuracy and compression ratio. Moreover, compared with the state-of-the-art pruning-during-training approach, ClickTrain reduces the accuracy drop by up to 2.1% and improves the compression ratio by up to 2.2X on the tested datasets, under similar limited training time.
DeepSZ: A Novel Framework to Compress Deep Neural Networks by Using Error-Bounded Lossy Compression
Jan 26, 2019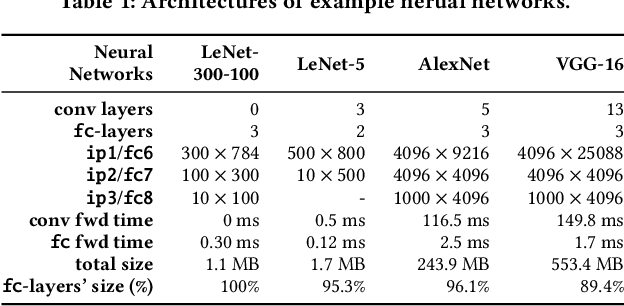
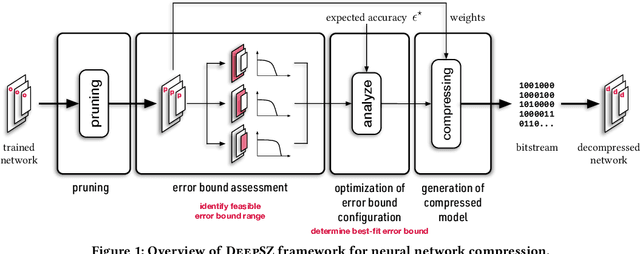
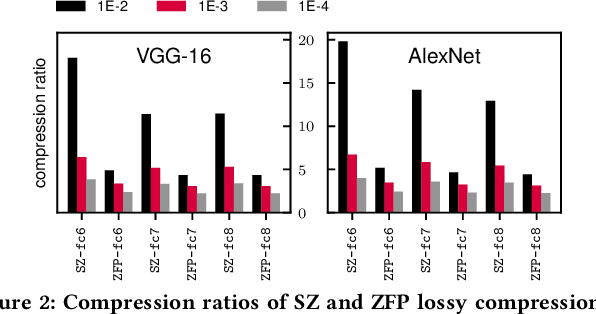
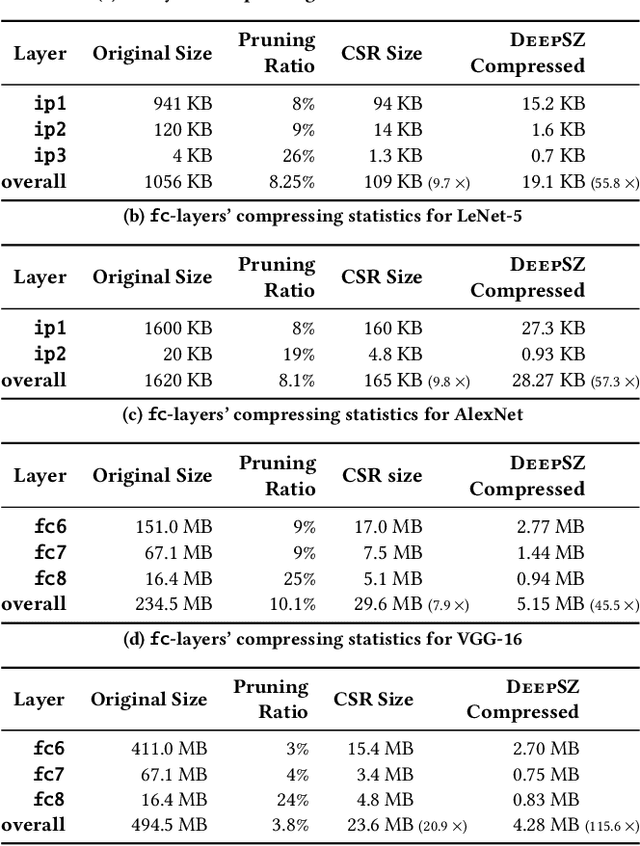
DNNs have been quickly and broadly exploited to improve the data analysis quality in many complex science and engineering applications. Today's DNNs are becoming deeper and wider because of increasing demand on the analysis quality and more and more complex applications to resolve. The wide and deep DNNs, however, require large amounts of resources, significantly restricting their utilization on resource-constrained systems. Although some network simplification methods have been proposed to address this issue, they suffer from either low compression ratios or high compression errors, which may introduce a costly retraining process for the target accuracy. In this paper, we propose DeepSZ: an accuracy-loss bounded neural network compression framework, which involves four key steps: network pruning, error bound assessment, optimization for error bound configuration, and compressed model generation, featuring a high compression ratio and low encoding time. The contribution is three-fold. (1) We develop an adaptive approach to select the feasible error bounds for each layer. (2) We build a model to estimate the overall loss of accuracy based on the accuracy degradation caused by individual decompressed layers. (3) We develop an efficient optimization algorithm to determine the best-fit configuration of error bounds in order to maximize the compression ratio under the user-set accuracy constraint. Experiments show that DeepSZ can compress AlexNet and VGG-16 on the ImageNet by a compression ratio of 46X and 116X, respectively, and compress LeNet-300-100 and LeNet-5 on the MNIST by a compression ratio of 57X and 56X, respectively, with only up to 0.3% loss of accuracy. Compared with other state-of-the-art methods, DeepSZ can improve the compression ratio by up to 1.43X, the DNN encoding performance by up to 4.0X (with four Nvidia Tesla V100 GPUs), and the decoding performance by up to 6.2X.