 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScrutinize What We Ignore: Reining Task Representation Shift In Context-Based Offline Meta Reinforcement Learning
May 20, 2024



Offline meta reinforcement learning (OMRL) has emerged as a promising approach for interaction avoidance and strong generalization performance by leveraging pre-collected data and meta-learning techniques. Previous context-based approaches predominantly rely on the intuition that maximizing the mutual information between the task and the task representation ($I(Z;M)$) can lead to performance improvements. Despite achieving attractive results, the theoretical justification of performance improvement for such intuition has been lacking. Motivated by the return discrepancy scheme in the model-based RL field, we find that maximizing $I(Z;M)$ can be interpreted as consistently raising the lower bound of the expected return for a given policy conditioning on the optimal task representation. However, this optimization process ignores the task representation shift between two consecutive updates, which may lead to performance improvement collapse. To address this problem, we turn to use the framework of performance difference bound to consider the impacts of task representation shift explicitly. We demonstrate that by reining the task representation shift, it is possible to achieve monotonic performance improvements, thereby showcasing the advantage against previous approaches. To make it practical, we design an easy yet highly effective algorithm RETRO (\underline{RE}ining \underline{T}ask \underline{R}epresentation shift in context-based \underline{O}ffline meta reinforcement learning) with only adding one line of code compared to the backbone. Empirical results validate its state-of-the-art (SOTA) asymptotic performance, training stability and training-time consumption on MuJoCo and MetaWorld benchmarks.
H-GCN: A Graph Convolutional Network Accelerator on Versal ACAP Architecture
Jun 28, 2022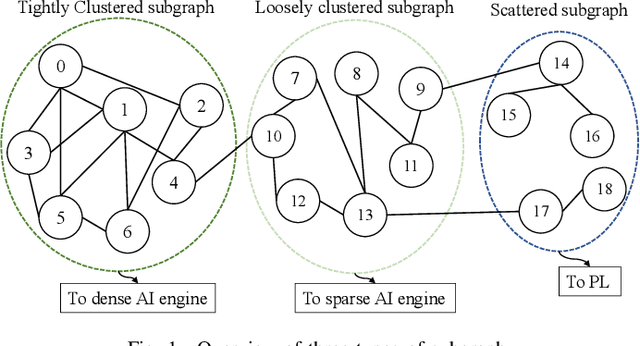
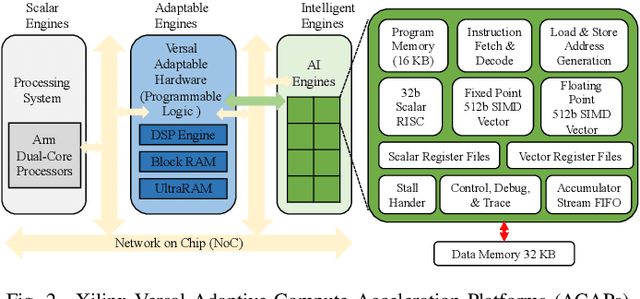
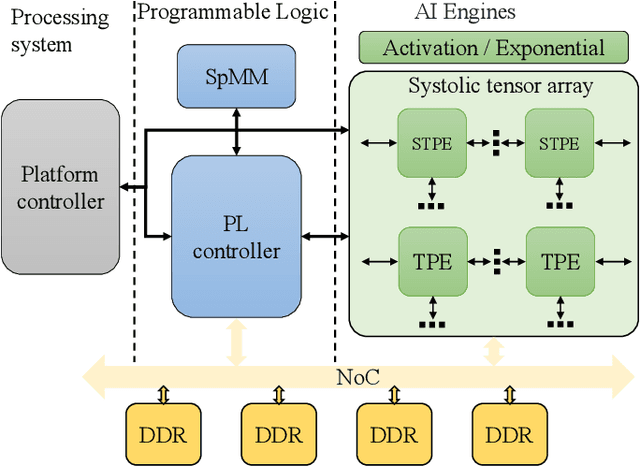
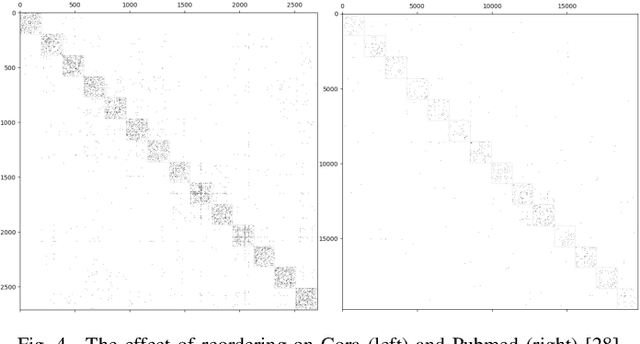
Graph Neural Networks (GNNs) have drawn tremendous attention due to their unique capability to extend Machine Learning (ML) approaches to applications broadly-defined as having unstructured data, especially graphs. Compared with other Machine Learning (ML) modalities, the acceleration of Graph Neural Networks (GNNs) is more challenging due to the irregularity and heterogeneity derived from graph typologies. Existing efforts, however, have focused mainly on handling graphs' irregularity and have not studied their heterogeneity. To this end we propose H-GCN, a PL (Programmable Logic) and AIE (AI Engine) based hybrid accelerator that leverages the emerging heterogeneity of Xilinx Versal Adaptive Compute Acceleration Platforms (ACAPs) to achieve high-performance GNN inference. In particular, H-GCN partitions each graph into three subgraphs based on its inherent heterogeneity, and processes them using PL and AIE, respectively. To further improve performance, we explore the sparsity support of AIE and develop an efficient density-aware method to automatically map tiles of sparse matrix-matrix multiplication (SpMM) onto the systolic tensor array. Compared with state-of-the-art GCN accelerators, H-GCN achieves, on average, speedups of 1.1~2.3X.
Shop The Look: Building a Large Scale Visual Shopping System at Pinterest
Jun 18, 2020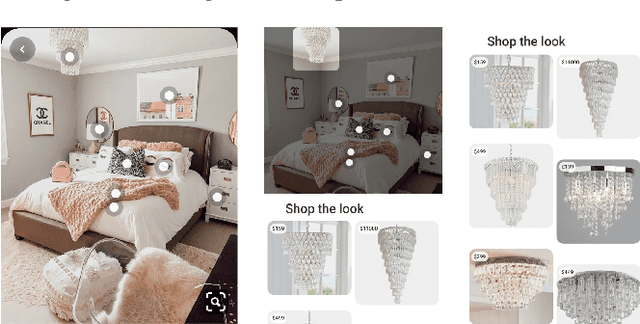

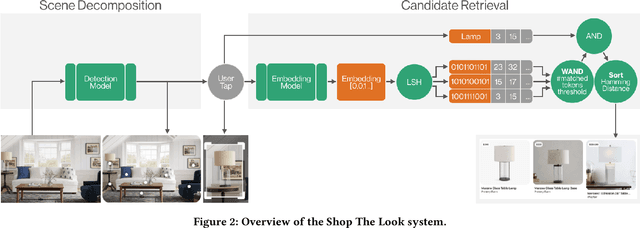
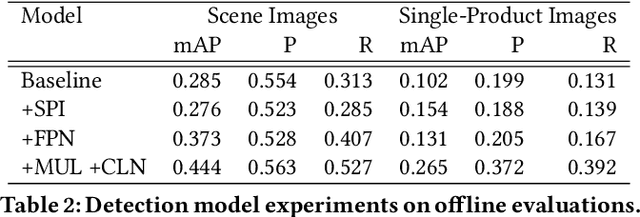
As online content becomes ever more visual, the demand for searching by visual queries grows correspondingly stronger. Shop The Look is an online shopping discovery service at Pinterest, leveraging visual search to enable users to find and buy products within an image. In this work, we provide a holistic view of how we built Shop The Look, a shopping oriented visual search system, along with lessons learned from addressing shopping needs. We discuss topics including core technology across object detection and visual embeddings, serving infrastructure for realtime inference, and data labeling methodology for training/evaluation data collection and human evaluation. The user-facing impacts of our system design choices are measured through offline evaluations, human relevance judgements, and online A/B experiments. The collective improvements amount to cumulative relative gains of over 160% in end-to-end human relevance judgements and over 80% in engagement. Shop The Look is deployed in production at Pinterest.