 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Geometrically-Grounded 3D Visual Representations for View-Generalizable Robotic Manipulation
Jan 30, 2026Real-world robotic manipulation demands visuomotor policies capable of robust spatial scene understanding and strong generalization across diverse camera viewpoints. While recent advances in 3D-aware visual representations have shown promise, they still suffer from several key limitations, including reliance on multi-view observations during inference which is impractical in single-view restricted scenarios, incomplete scene modeling that fails to capture holistic and fine-grained geometric structures essential for precise manipulation, and lack of effective policy training strategies to retain and exploit the acquired 3D knowledge. To address these challenges, we present MethodName, a unified representation-policy learning framework for view-generalizable robotic manipulation. MethodName introduces a single-view 3D pretraining paradigm that leverages point cloud reconstruction and feed-forward gaussian splatting under multi-view supervision to learn holistic geometric representations. During policy learning, MethodName performs multi-step distillation to preserve the pretrained geometric understanding and effectively transfer it to manipulation skills. We conduct experiments on 12 RLBench tasks, where our approach outperforms the previous state-of-the-art method by 12.7% in average success rate. Further evaluation on six representative tasks demonstrates strong zero-shot view generalization, with success rate drops of only 22.0% and 29.7% under moderate and large viewpoint shifts respectively, whereas the state-of-the-art method suffers larger decreases of 41.6% and 51.5%.
Numina-Lean-Agent: An Open and General Agentic Reasoning System for Formal Mathematics
Jan 20, 2026Agentic systems have recently become the dominant paradigm for formal theorem proving, achieving strong performance by coordinating multiple models and tools. However, existing approaches often rely on task-specific pipelines and trained formal provers, limiting their flexibility and reproducibility. In this paper, we propose the paradigm that directly uses a general coding agent as a formal math reasoner. This paradigm is motivated by (1) A general coding agent provides a natural interface for diverse reasoning tasks beyond proving, (2) Performance can be improved by simply replacing the underlying base model, without training, and (3) MCP enables flexible extension and autonomous calling of specialized tools, avoiding complex design. Based on this paradigm, we introduce Numina-Lean-Agent, which combines Claude Code with Numina-Lean-MCP to enable autonomous interaction with Lean, retrieval of relevant theorems, informal proving and auxiliary reasoning tools. Using Claude Opus 4.5 as the base model, Numina-Lean-Agent solves all problems in Putnam 2025 (12 / 12), matching the best closed-source system. Beyond benchmark evaluation, we further demonstrate its generality by interacting with mathematicians to successfully formalize the Brascamp-Lieb theorem. We release Numina-Lean-Agent and all solutions at https://github.com/project-numina/numina-lean-agent.
Point What You Mean: Visually Grounded Instruction Policy
Dec 22, 2025
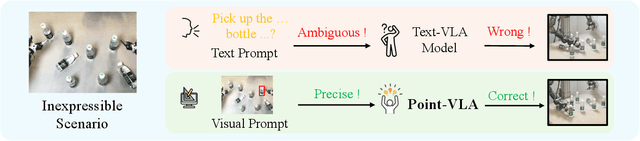
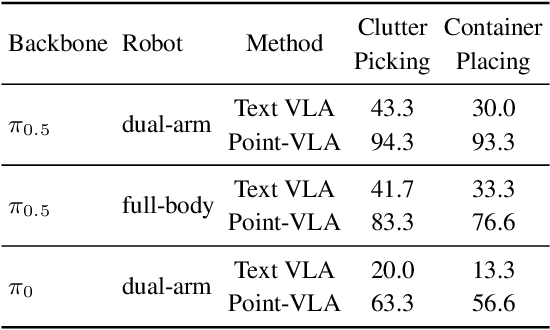
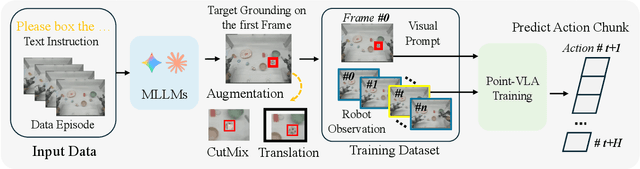
Vision-Language-Action (VLA) models align vision and language with embodied control, but their object referring ability remains limited when relying solely on text prompt, especially in cluttered or out-of-distribution (OOD) scenes. In this study, we introduce the Point-VLA, a plug-and-play policy that augments language instructions with explicit visual cues (e.g., bounding boxes) to resolve referential ambiguity and enable precise object-level grounding. To efficiently scale visually grounded datasets, we further develop an automatic data annotation pipeline requiring minimal human effort. We evaluate Point-VLA on diverse real-world referring tasks and observe consistently stronger performance than text-only instruction VLAs, particularly in cluttered or unseen-object scenarios, with robust generalization. These results demonstrate that Point-VLA effectively resolves object referring ambiguity through pixel-level visual grounding, achieving more generalizable embodied control.
Learning from Mistakes: Loss-Aware Memory Enhanced Continual Learning for LiDAR Place Recognition
Nov 19, 2025



LiDAR place recognition plays a crucial role in SLAM, robot navigation, and autonomous driving. However, existing LiDAR place recognition methods often struggle to adapt to new environments without forgetting previously learned knowledge, a challenge widely known as catastrophic forgetting. To address this issue, we propose KDF+, a novel continual learning framework for LiDAR place recognition that extends the KDF paradigm with a loss-aware sampling strategy and a rehearsal enhancement mechanism. The proposed sampling strategy estimates the learning difficulty of each sample via its loss value and selects samples for replay according to their estimated difficulty. Harder samples, which tend to encode more discriminative information, are sampled with higher probability while maintaining distributional coverage across the dataset. In addition, the rehearsal enhancement mechanism encourages memory samples to be further refined during new-task training by slightly reducing their loss relative to previous tasks, thereby reinforcing long-term knowledge retention. Extensive experiments across multiple benchmarks demonstrate that KDF+ consistently outperforms existing continual learning methods and can be seamlessly integrated into state-of-the-art continual learning for LiDAR place recognition frameworks to yield significant and stable performance gains. The code will be available at https://github.com/repo/KDF-plus.
Ranking-aware Continual Learning for LiDAR Place Recognition
May 12, 2025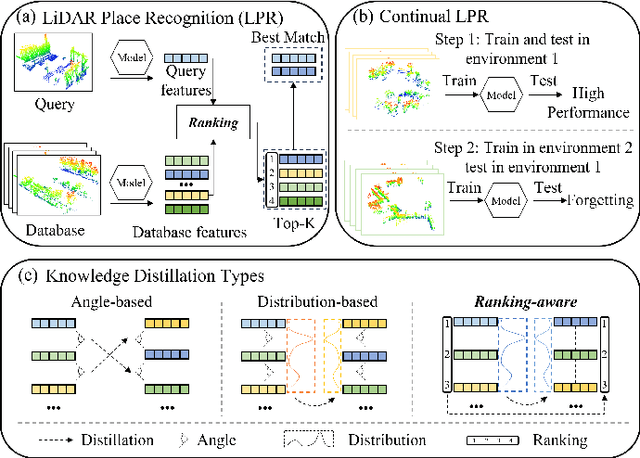
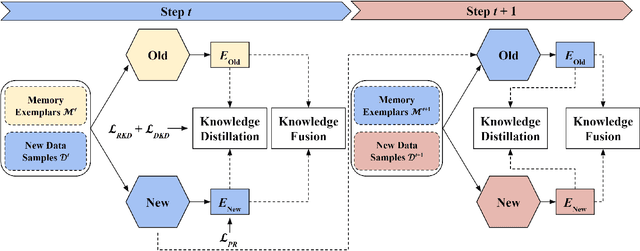
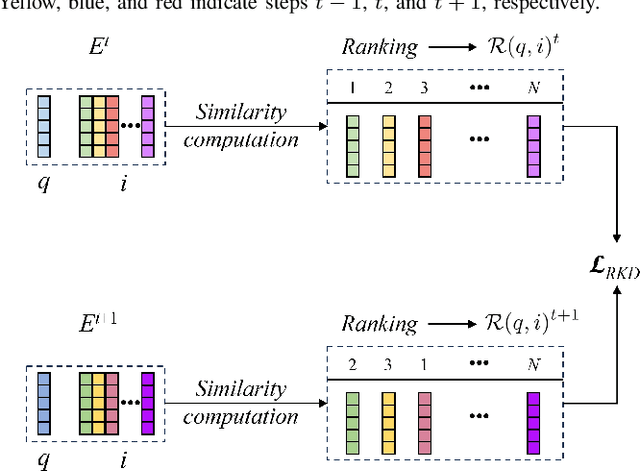
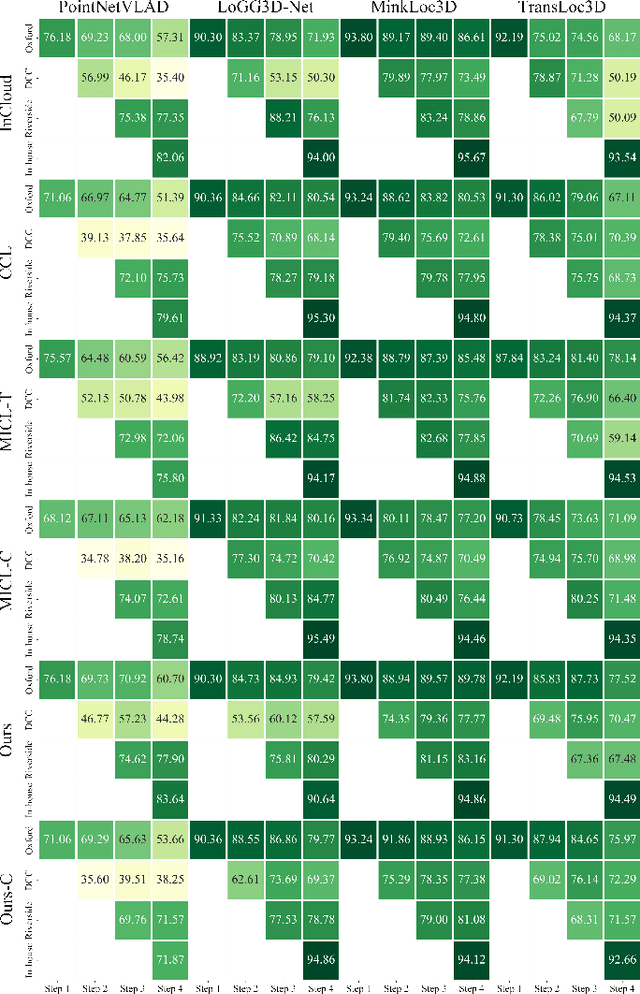
Place recognition plays a significant role in SLAM, robot navigation, and autonomous driving applications. Benefiting from deep learning, the performance of LiDAR place recognition (LPR) has been greatly improved. However, many existing learning-based LPR methods suffer from catastrophic forgetting, which severely harms the performance of LPR on previously trained places after training on a new environment. In this paper, we introduce a continual learning framework for LPR via Knowledge Distillation and Fusion (KDF) to alleviate forgetting. Inspired by the ranking process of place recognition retrieval, we present a ranking-aware knowledge distillation loss that encourages the network to preserve the high-level place recognition knowledge. We also introduce a knowledge fusion module to integrate the knowledge of old and new models for LiDAR place recognition. Our extensive experiments demonstrate that KDF can be applied to different networks to overcome catastrophic forgetting, surpassing the state-of-the-art methods in terms of mean Recall@1 and forgetting score.
KineDex: Learning Tactile-Informed Visuomotor Policies via Kinesthetic Teaching for Dexterous Manipulation
May 04, 2025
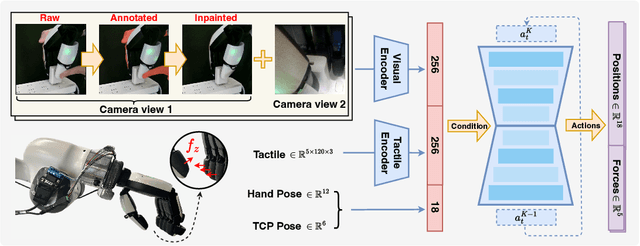


Collecting demonstrations enriched with fine-grained tactile information is critical for dexterous manipulation, particularly in contact-rich tasks that require precise force control and physical interaction. While prior works primarily focus on teleoperation or video-based retargeting, they often suffer from kinematic mismatches and the absence of real-time tactile feedback, hindering the acquisition of high-fidelity tactile data. To mitigate this issue, we propose KineDex, a hand-over-hand kinesthetic teaching paradigm in which the operator's motion is directly transferred to the dexterous hand, enabling the collection of physically grounded demonstrations enriched with accurate tactile feedback. To resolve occlusions from human hand, we apply inpainting technique to preprocess the visual observations. Based on these demonstrations, we then train a visuomotor policy using tactile-augmented inputs and implement force control during deployment for precise contact-rich manipulation. We evaluate KineDex on a suite of challenging contact-rich manipulation tasks, including particularly difficult scenarios such as squeezing toothpaste onto a toothbrush, which require precise multi-finger coordination and stable force regulation. Across these tasks, KineDex achieves an average success rate of 74.4%, representing a 57.7% improvement over the variant without force control. Comparative experiments with teleoperation and user studies further validate the advantages of KineDex in data collection efficiency and operability. Specifically, KineDex collects data over twice as fast as teleoperation across two tasks of varying difficulty, while maintaining a near-100% success rate, compared to under 50% for teleoperation.
Convex Hull-based Algebraic Constraint for Visual Quadric SLAM
Mar 03, 2025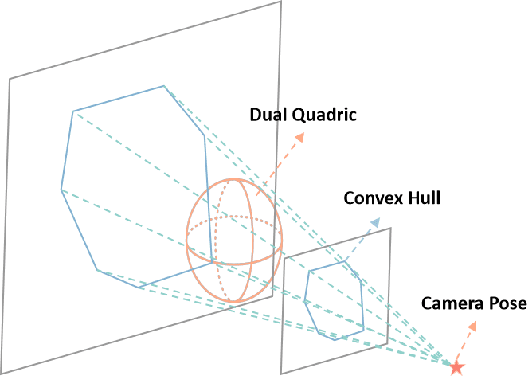

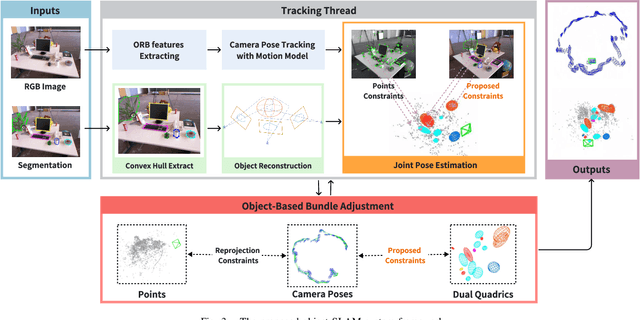

Using Quadrics as the object representation has the benefits of both generality and closed-form projection derivation between image and world spaces. Although numerous constraints have been proposed for dual quadric reconstruction, we found that many of them are imprecise and provide minimal improvements to localization.After scrutinizing the existing constraints, we introduce a concise yet more precise convex hull-based algebraic constraint for object landmarks, which is applied to object reconstruction, frontend pose estimation, and backend bundle adjustment.This constraint is designed to fully leverage precise semantic segmentation, effectively mitigating mismatches between complex-shaped object contours and dual quadrics.Experiments on public datasets demonstrate that our approach is applicable to both monocular and RGB-D SLAM and achieves improved object mapping and localization than existing quadric SLAM methods. The implementation of our method is available at https://github.com/tiev-tongji/convexhull-based-algebraic-constraint.
MVC-VPR: Mutual Learning of Viewpoint Classification and Visual Place Recognition
Dec 13, 2024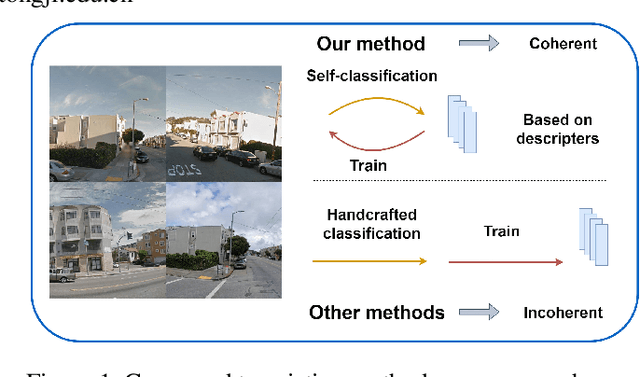
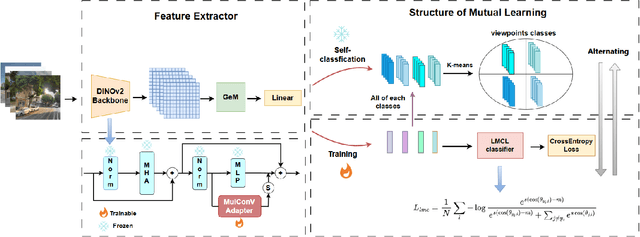
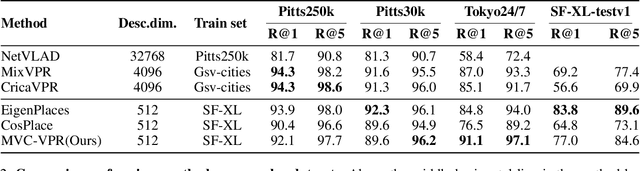
Visual Place Recognition (VPR) aims to robustly identify locations by leveraging image retrieval based on descriptors encoded from environmental images. However, drastic appearance changes of images captured from different viewpoints at the same location pose incoherent supervision signals for descriptor learning, which severely hinder the performance of VPR. Previous work proposes classifying images based on manually defined rules or ground truth labels for viewpoints, followed by descriptor training based on the classification results. However, not all datasets have ground truth labels of viewpoints and manually defined rules may be suboptimal, leading to degraded descriptor performance.To address these challenges, we introduce the mutual learning of viewpoint self-classification and VPR. Starting from coarse classification based on geographical coordinates, we progress to finer classification of viewpoints using simple clustering techniques. The dataset is partitioned in an unsupervised manner while simultaneously training a descriptor extractor for place recognition. Experimental results show that this approach almost perfectly partitions the dataset based on viewpoints, thus achieving mutually reinforcing effects. Our method even excels state-of-the-art (SOTA) methods that partition datasets using ground truth labels.
Scrutinize What We Ignore: Reining Task Representation Shift In Context-Based Offline Meta Reinforcement Learning
May 20, 2024



Offline meta reinforcement learning (OMRL) has emerged as a promising approach for interaction avoidance and strong generalization performance by leveraging pre-collected data and meta-learning techniques. Previous context-based approaches predominantly rely on the intuition that maximizing the mutual information between the task and the task representation ($I(Z;M)$) can lead to performance improvements. Despite achieving attractive results, the theoretical justification of performance improvement for such intuition has been lacking. Motivated by the return discrepancy scheme in the model-based RL field, we find that maximizing $I(Z;M)$ can be interpreted as consistently raising the lower bound of the expected return for a given policy conditioning on the optimal task representation. However, this optimization process ignores the task representation shift between two consecutive updates, which may lead to performance improvement collapse. To address this problem, we turn to use the framework of performance difference bound to consider the impacts of task representation shift explicitly. We demonstrate that by reining the task representation shift, it is possible to achieve monotonic performance improvements, thereby showcasing the advantage against previous approaches. To make it practical, we design an easy yet highly effective algorithm RETRO (\underline{RE}ining \underline{T}ask \underline{R}epresentation shift in context-based \underline{O}ffline meta reinforcement learning) with only adding one line of code compared to the backbone. Empirical results validate its state-of-the-art (SOTA) asymptotic performance, training stability and training-time consumption on MuJoCo and MetaWorld benchmarks.
POWQMIX: Weighted Value Factorization with Potentially Optimal Joint Actions Recognition for Cooperative Multi-Agent Reinforcement Learning
May 15, 2024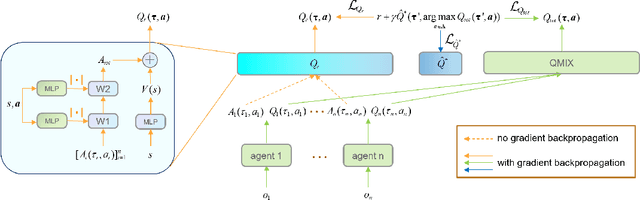
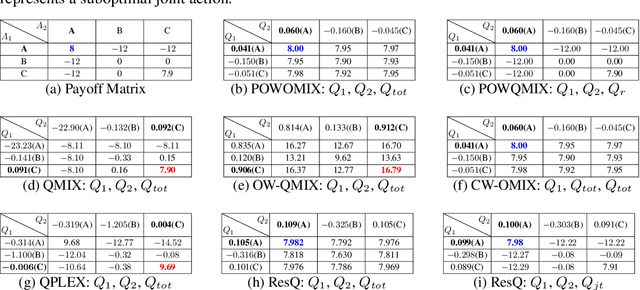
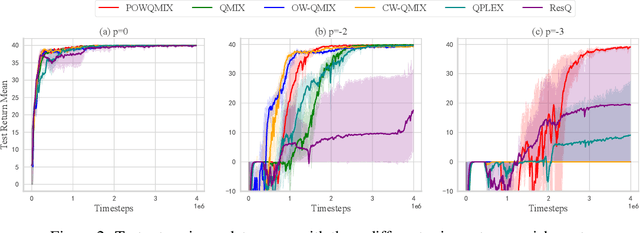
Value function factorization methods are commonly used in cooperative multi-agent reinforcement learning, with QMIX receiving significant attention. Many QMIX-based methods introduce monotonicity constraints between the joint action value and individual action values to achieve decentralized execution. However, such constraints limit the representation capacity of value factorization, restricting the joint action values it can represent and hindering the learning of the optimal policy. To address this challenge, we propose the Potentially Optimal joint actions Weighted QMIX (POWQMIX) algorithm, which recognizes the potentially optimal joint actions and assigns higher weights to the corresponding losses of these joint actions during training. We theoretically prove that with such a weighted training approach the optimal policy is guaranteed to be recovered. Experiments in matrix games, predator-prey, and StarCraft II Multi-Agent Challenge environments demonstrate that our algorithm outperforms the state-of-the-art value-based multi-agent reinforcement learning methods.