 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniDex: A Robot Foundation Suite for Universal Dexterous Hand Control from Egocentric Human Videos
Mar 23, 2026Dexterous manipulation remains challenging due to the cost of collecting real-robot teleoperation data, the heterogeneity of hand embodiments, and the high dimensionality of control. We present UniDex, a robot foundation suite that couples a large-scale robot-centric dataset with a unified vision-language-action (VLA) policy and a practical human-data capture setup for universal dexterous hand control. First, we construct UniDex-Dataset, a robot-centric dataset over 50K trajectories across eight dexterous hands (6--24 DoFs), derived from egocentric human video datasets. To transform human data into robot-executable trajectories, we employ a human-in-the-loop retargeting procedure to align fingertip trajectories while preserving plausible hand-object contacts, and we operate on explicit 3D pointclouds with human hands masked to narrow kinematic and visual gaps. Second, we introduce the Function-Actuator-Aligned Space (FAAS), a unified action space that maps functionally similar actuators to shared coordinates, enabling cross-hand transfer. Leveraging FAAS as the action parameterization, we train UniDex-VLA, a 3D VLA policy pretrained on UniDex-Dataset and finetuned with task demonstrations. In addition, we build UniDex-Cap, a simple portable capture setup that records synchronized RGB-D streams and human hand poses and converts them into robot-executable trajectories to enable human-robot data co-training that reduces reliance on costly robot demonstrations. On challenging tool-use tasks across two different hands, UniDex-VLA achieves 81% average task progress and outperforms prior VLA baselines by a large margin, while exhibiting strong spatial, object, and zero-shot cross-hand generalization. Together, UniDex-Dataset, UniDex-VLA, and UniDex-Cap provide a scalable foundation suite for universal dexterous manipulation.
KineDex: Learning Tactile-Informed Visuomotor Policies via Kinesthetic Teaching for Dexterous Manipulation
May 04, 2025
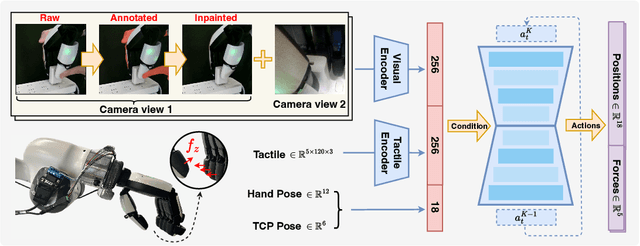


Collecting demonstrations enriched with fine-grained tactile information is critical for dexterous manipulation, particularly in contact-rich tasks that require precise force control and physical interaction. While prior works primarily focus on teleoperation or video-based retargeting, they often suffer from kinematic mismatches and the absence of real-time tactile feedback, hindering the acquisition of high-fidelity tactile data. To mitigate this issue, we propose KineDex, a hand-over-hand kinesthetic teaching paradigm in which the operator's motion is directly transferred to the dexterous hand, enabling the collection of physically grounded demonstrations enriched with accurate tactile feedback. To resolve occlusions from human hand, we apply inpainting technique to preprocess the visual observations. Based on these demonstrations, we then train a visuomotor policy using tactile-augmented inputs and implement force control during deployment for precise contact-rich manipulation. We evaluate KineDex on a suite of challenging contact-rich manipulation tasks, including particularly difficult scenarios such as squeezing toothpaste onto a toothbrush, which require precise multi-finger coordination and stable force regulation. Across these tasks, KineDex achieves an average success rate of 74.4%, representing a 57.7% improvement over the variant without force control. Comparative experiments with teleoperation and user studies further validate the advantages of KineDex in data collection efficiency and operability. Specifically, KineDex collects data over twice as fast as teleoperation across two tasks of varying difficulty, while maintaining a near-100% success rate, compared to under 50% for teleoperation.
RoboEngine: Plug-and-Play Robot Data Augmentation with Semantic Robot Segmentation and Background Generation
Mar 24, 2025



Visual augmentation has become a crucial technique for enhancing the visual robustness of imitation learning. However, existing methods are often limited by prerequisites such as camera calibration or the need for controlled environments (e.g., green screen setups). In this work, we introduce RoboEngine, the first plug-and-play visual robot data augmentation toolkit. For the first time, users can effortlessly generate physics- and task-aware robot scenes with just a few lines of code. To achieve this, we present a novel robot scene segmentation dataset, a generalizable high-quality robot segmentation model, and a fine-tuned background generation model, which together form the core components of the out-of-the-box toolkit. Using RoboEngine, we demonstrate the ability to generalize robot manipulation tasks across six entirely new scenes, based solely on demonstrations collected from a single scene, achieving a more than 200% performance improvement compared to the no-augmentation baseline. All datasets, model weights, and the toolkit will be publicly released.
UniHOI: Learning Fast, Dense and Generalizable 4D Reconstruction for Egocentric Hand Object Interaction Videos
Nov 14, 2024Egocentric Hand Object Interaction (HOI) videos provide valuable insights into human interactions with the physical world, attracting growing interest from the computer vision and robotics communities. A key task in fully understanding the geometry and dynamics of HOI scenes is dense pointclouds sequence reconstruction. However, the inherent motion of both hands and the camera makes this challenging. Current methods often rely on time-consuming test-time optimization, making them impractical for reconstructing internet-scale videos. To address this, we introduce UniHOI, a model that unifies the estimation of all variables necessary for dense 4D reconstruction, including camera intrinsic, camera poses, and video depth, for egocentric HOI scene in a fast feed-forward manner. We end-to-end optimize all these variables to improve their consistency in 3D space. Furthermore, our model could be trained solely on large-scale monocular video dataset, overcoming the limitation of scarce labeled HOI data. We evaluate UniHOI with both in-domain and zero-shot generalization setting, surpassing all baselines in pointclouds sequence reconstruction and long-term 3D scene flow recovery. UniHOI is the first approach to offer fast, dense, and generalizable monocular egocentric HOI scene reconstruction in the presence of motion. Code and trained model will be released in the future.
General Flow as Foundation Affordance for Scalable Robot Learning
Jan 21, 2024



We address the challenge of acquiring real-world manipulation skills with a scalable framework.Inspired by the success of large-scale auto-regressive prediction in Large Language Models (LLMs), we hold the belief that identifying an appropriate prediction target capable of leveraging large-scale datasets is crucial for achieving efficient and universal learning. Therefore, we propose to utilize flow, which represents the future trajectories of 3D points on objects of interest, as an ideal prediction target in robot learning. To exploit scalable data resources, we turn our attention to cross-embodiment datasets. We develop, for the first time, a language-conditioned prediction model directly from large-scale RGBD human video datasets. Our predicted flow offers actionable geometric and physics guidance, thus facilitating stable zero-shot skill transfer in real-world scenarios.We deploy our method with a policy based on closed-loop flow prediction. Remarkably, without any additional training, our method achieves an impressive 81% success rate in human-to-robot skill transfer, covering 18 tasks in 6 scenes. Our framework features the following benefits: (1) scalability: leveraging cross-embodiment data resources; (2) universality: multiple object categories, including rigid, articulated, and soft bodies; (3) stable skill transfer: providing actionable guidance with a small inference domain-gap. These lead to a new pathway towards scalable general robot learning. Data, code, and model weights will be made publicly available.
Depression Diagnosis and Analysis via Multimodal Multi-order Factor Fusion
Dec 31, 2022



Depression is a leading cause of death worldwide, and the diagnosis of depression is nontrivial. Multimodal learning is a popular solution for automatic diagnosis of depression, and the existing works suffer two main drawbacks: 1) the high-order interactions between different modalities can not be well exploited; and 2) interpretability of the models are weak. To remedy these drawbacks, we propose a multimodal multi-order factor fusion (MMFF) method. Our method can well exploit the high-order interactions between different modalities by extracting and assembling modality factors under the guide of a shared latent proxy. We conduct extensive experiments on two recent and popular datasets, E-DAIC-WOZ and CMDC, and the results show that our method achieve significantly better performance compared with other existing approaches. Besides, by analyzing the process of factor assembly, our model can intuitively show the contribution of each factor. This helps us understand the fusion mechanism.