 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightMoE: Reducing Mixture-of-Experts Redundancy through Expert Replacing
Mar 13, 2026Mixture-of-Experts (MoE) based Large Language Models (LLMs) have demonstrated impressive performance and computational efficiency. However, their deployment is often constrained by substantial memory demands, primarily due to the need to load numerous expert modules. While existing expert compression techniques like pruning or merging attempt to mitigate this, they often suffer from irreversible knowledge loss or high training overhead. In this paper, we propose a novel expert compression paradigm termed expert replacing, which replaces redundant experts with parameter-efficient modules and recovers their capabilities with low training costs. We find that even a straightforward baseline of this paradigm yields promising performance. Building on this foundation, we introduce LightMoE, a framework that enhances the paradigm by introducing adaptive expert selection, hierarchical expert construction, and an annealed recovery strategy. Experimental results show that LightMoE matches the performance of LoRA fine-tuning at a 30% compression ratio. Even under a more aggressive 50% compression rate, it outperforms existing methods and achieves average performance improvements of 5.6% across five diverse tasks. These findings demonstrate that LightMoE strikes a superior balance among memory efficiency, training efficiency, and model performance.
CtrlAttack: A Unified Attack on World-Model Control in Diffusion Models
Mar 13, 2026Diffusion-based image-to-video (I2V) models increasingly exhibit world-model-like properties by implicitly capturing temporal dynamics. However, existing studies have mainly focused on visual quality and controllability, and the robustness of the state transition learned by the model remains understudied. To fill this gap, we are the first to analyze the vulnerability of I2V models, find that temporal control mechanisms constitute a new attack surface, and reveal the challenge of modeling them uniformly under different attack settings. Based on this, we propose a trajectory-control attack, called CtrlAttack, to interfere with state evolution during the generation process. Specifically, we represent the perturbation as a low-dimensional velocity field and construct a continuous displacement field via temporal integration, thereby affecting the model's state transitions while maintaining temporal consistency; meanwhile, we map the perturbation to the observation space, making the method applicable to both white-box and black-box attack settings. Experimental results show that even under low-dimensional and strongly regularized perturbation constraints, our method can still significantly disrupt temporal consistency by increasing the attack success rate (ASR) to over 90% in the white-box setting and over 80% in the black-box setting, while keeping the variation of the FID and FVD within 6 and 130, respectively, thus revealing the potential security risk of I2V models at the level of state dynamics.
DSA-SRGS: Super-Resolution Gaussian Splatting for Dynamic Sparse-View DSA Reconstruction
Mar 05, 2026Digital subtraction angiography (DSA) is a key imaging technique for the auxiliary diagnosis and treatment of cerebrovascular diseases. Recent advancements in gaussian splatting and dynamic neural representations have enabled robust 3D vessel reconstruction from sparse dynamic inputs. However, these methods are fundamentally constrained by the resolution of input projections, where performing naive upsampling to enhance rendering resolution inevitably results in severe blurring and aliasing artifacts. Such lack of super-resolution capability prevents the reconstructed 4D models from recovering fine-grained vascular details and intricate branching structures, which restricts their application in precision diagnosis and treatment. To solve this problem, this paper proposes DSA-SRGS, the first super-resolution gaussian splatting framework for dynamic sparse-view DSA reconstruction. Specifically, we introduce a Multi-Fidelity Texture Learning Module that integrates high-quality priors from a fine-tuned DSA-specific super-resolution model, into the 4D reconstruction optimization. To mitigate potential hallucination artifacts from pseudo-labels, this module employs a Confidence-Aware Strategy to adaptively weight supervision signals between the original low-resolution projections and the generated high-resolution pseudo-labels. Furthermore, we develop Radiative Sub-Pixel Densification, an adaptive strategy that leverages gradient accumulation from high-resolution sub-pixel sampling to refine the 4D radiative gaussian kernels. Extensive experiments on two clinical DSA datasets demonstrate that DSA-SRGS significantly outperforms state-of-the-art methods in both quantitative metrics and qualitative visual fidelity.
ACE-Brain-0: Spatial Intelligence as a Shared Scaffold for Universal Embodiments
Mar 03, 2026Universal embodied intelligence demands robust generalization across heterogeneous embodiments, such as autonomous driving, robotics, and unmanned aerial vehicles (UAVs). However, existing embodied brain in training a unified model over diverse embodiments frequently triggers long-tail data, gradient interference, and catastrophic forgetting, making it notoriously difficult to balance universal generalization with domain-specific proficiency. In this report, we introduce ACE-Brain-0, a generalist foundation brain that unifies spatial reasoning, autonomous driving, and embodied manipulation within a single multimodal large language model~(MLLM). Our key insight is that spatial intelligence serves as a universal scaffold across diverse physical embodiments: although vehicles, robots, and UAVs differ drastically in morphology, they share a common need for modeling 3D mental space, making spatial cognition a natural, domain-agnostic foundation for cross-embodiment transfer. Building on this insight, we propose the Scaffold-Specialize-Reconcile~(SSR) paradigm, which first establishes a shared spatial foundation, then cultivates domain-specialized experts, and finally harmonizes them through data-free model merging. Furthermore, we adopt Group Relative Policy Optimization~(GRPO) to strengthen the model's comprehensive capability. Extensive experiments demonstrate that ACE-Brain-0 achieves competitive and even state-of-the-art performance across 24 spatial and embodiment-related benchmarks.
TranX-Adapter: Bridging Artifacts and Semantics within MLLMs for Robust AI-generated Image Detection
Feb 25, 2026Rapid advances in AI-generated image (AIGI) technology enable highly realistic synthesis, threatening public information integrity and security. Recent studies have demonstrated that incorporating texture-level artifact features alongside semantic features into multimodal large language models (MLLMs) can enhance their AIGI detection capability. However, our preliminary analyses reveal that artifact features exhibit high intra-feature similarity, leading to an almost uniform attention map after the softmax operation. This phenomenon causes attention dilution, thereby hindering effective fusion between semantic and artifact features. To overcome this limitation, we propose a lightweight fusion adapter, TranX-Adapter, which integrates a Task-aware Optimal-Transport Fusion that leverages the Jensen-Shannon divergence between artifact and semantic prediction probabilities as a cost matrix to transfer artifact information into semantic features, and an X-Fusion that employs cross-attention to transfer semantic information into artifact features. Experiments on standard AIGI detection benchmarks upon several advanced MLLMs, show that our TranX-Adapter brings consistent and significant improvements (up to +6% accuracy).
Bootstrapping MLLM for Weakly-Supervised Class-Agnostic Object Counting
Feb 13, 2026Object counting is a fundamental task in computer vision, with broad applicability in many real-world scenarios. Fully-supervised counting methods require costly point-level annotations per object. Few weakly-supervised methods leverage only image-level object counts as supervision and achieve fairly promising results. They are, however, often limited to counting a single category, e.g. person. In this paper, we propose WS-COC, the first MLLM-driven weakly-supervised framework for class-agnostic object counting. Instead of directly fine-tuning MLLMs to predict object counts, which can be challenging due to the modality gap, we incorporate three simple yet effective strategies to bootstrap the counting paradigm in both training and testing: First, a divide-and-discern dialogue tuning strategy is proposed to guide the MLLM to determine whether the object count falls within a specific range and progressively break down the range through multi-round dialogue. Second, a compare-and-rank count optimization strategy is introduced to train the MLLM to optimize the relative ranking of multiple images according to their object counts. Third, a global-and-local counting enhancement strategy aggregates and fuses local and global count predictions to improve counting performance in dense scenes. Extensive experiments on FSC-147, CARPK, PUCPR+, and ShanghaiTech show that WS-COC matches or even surpasses many state-of-art fully-supervised methods while significantly reducing annotation costs. Code is available at https://github.com/viscom-tongji/WS-COC.
Streaming-dLLM: Accelerating Diffusion LLMs via Suffix Pruning and Dynamic Decoding
Jan 27, 2026Diffusion Large Language Models (dLLMs) offer a compelling paradigm for natural language generation, leveraging parallel decoding and bidirectional attention to achieve superior global coherence compared to autoregressive models. While recent works have accelerated inference via KV cache reuse or heuristic decoding, they overlook the intrinsic inefficiencies within the block-wise diffusion process. Specifically, they suffer from spatial redundancy by modeling informative-sparse suffix regions uniformly and temporal inefficiency by applying fixed denoising schedules across all the decoding process. To address this, we propose Streaming-dLLM, a training-free framework that streamlines inference across both spatial and temporal dimensions. Spatially, we introduce attenuation guided suffix modeling to approximate the full context by pruning redundant mask tokens. Temporally, we employ a dynamic confidence aware strategy with an early exit mechanism, allowing the model to skip unnecessary iterations for converged tokens. Extensive experiments show that Streaming-dLLM achieves up to 68.2X speedup while maintaining generation quality, highlighting its effectiveness in diffusion decoding. The code is available at https://github.com/xiaoshideta/Streaming-dLLM.
UniX: Unifying Autoregression and Diffusion for Chest X-Ray Understanding and Generation
Jan 16, 2026Despite recent progress, medical foundation models still struggle to unify visual understanding and generation, as these tasks have inherently conflicting goals: semantic abstraction versus pixel-level reconstruction. Existing approaches, typically based on parameter-shared autoregressive architectures, frequently lead to compromised performance in one or both tasks. To address this, we present UniX, a next-generation unified medical foundation model for chest X-ray understanding and generation. UniX decouples the two tasks into an autoregressive branch for understanding and a diffusion branch for high-fidelity generation. Crucially, a cross-modal self-attention mechanism is introduced to dynamically guide the generation process with understanding features. Coupled with a rigorous data cleaning pipeline and a multi-stage training strategy, this architecture enables synergistic collaboration between tasks while leveraging the strengths of diffusion models for superior generation. On two representative benchmarks, UniX achieves a 46.1% improvement in understanding performance (Micro-F1) and a 24.2% gain in generation quality (FD-RadDino), using only a quarter of the parameters of LLM-CXR. By achieving performance on par with task-specific models, our work establishes a scalable paradigm for synergistic medical image understanding and generation. Codes and models are available at https://github.com/ZrH42/UniX.
REX-RAG: Reasoning Exploration with Policy Correction in Retrieval-Augmented Generation
Aug 12, 2025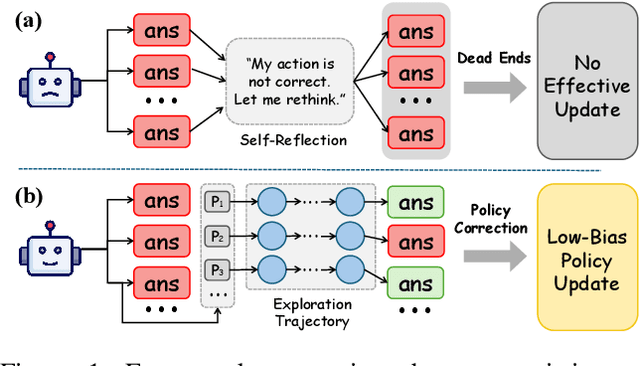
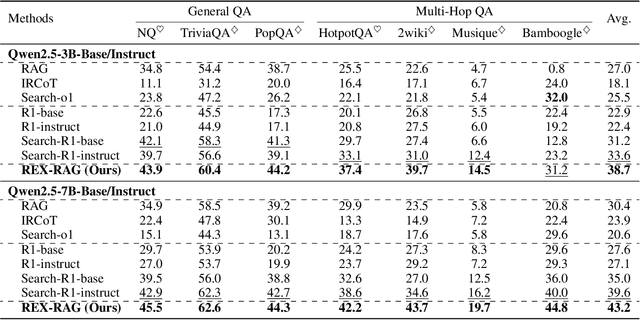
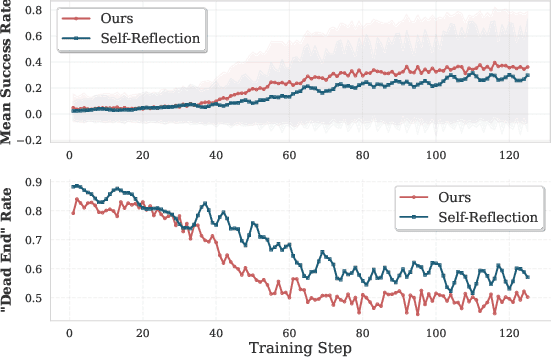
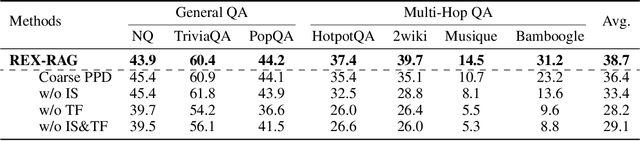
Reinforcement learning (RL) is emerging as a powerful paradigm for enabling large language models (LLMs) to perform complex reasoning tasks. Recent advances indicate that integrating RL with retrieval-augmented generation (RAG) allows LLMs to dynamically incorporate external knowledge, leading to more informed and robust decision making. However, we identify a critical challenge during policy-driven trajectory sampling: LLMs are frequently trapped in unproductive reasoning paths, which we refer to as "dead ends", committing to overconfident yet incorrect conclusions. This severely hampers exploration and undermines effective policy optimization. To address this challenge, we propose REX-RAG (Reasoning Exploration with Policy Correction in Retrieval-Augmented Generation), a novel framework that explores alternative reasoning paths while maintaining rigorous policy learning through principled distributional corrections. Our approach introduces two key innovations: (1) Mixed Sampling Strategy, which combines a novel probe sampling method with exploratory prompts to escape dead ends; and (2) Policy Correction Mechanism, which employs importance sampling to correct distribution shifts induced by mixed sampling, thereby mitigating gradient estimation bias. We evaluate it on seven question-answering benchmarks, and the experimental results show that REX-RAG achieves average performance gains of 5.1% on Qwen2.5-3B and 3.6% on Qwen2.5-7B over strong baselines, demonstrating competitive results across multiple datasets. The code is publicly available at https://github.com/MiliLab/REX-RAG.
Demonstration of Efficient Predictive Surrogates for Large-scale Quantum Processors
Jul 23, 2025The ongoing development of quantum processors is driving breakthroughs in scientific discovery. Despite this progress, the formidable cost of fabricating large-scale quantum processors means they will remain rare for the foreseeable future, limiting their widespread application. To address this bottleneck, we introduce the concept of predictive surrogates, which are classical learning models designed to emulate the mean-value behavior of a given quantum processor with provably computational efficiency. In particular, we propose two predictive surrogates that can substantially reduce the need for quantum processor access in diverse practical scenarios. To demonstrate their potential in advancing digital quantum simulation, we use these surrogates to emulate a quantum processor with up to 20 programmable superconducting qubits, enabling efficient pre-training of variational quantum eigensolvers for families of transverse-field Ising models and identification of non-equilibrium Floquet symmetry-protected topological phases. Experimental results reveal that the predictive surrogates not only reduce measurement overhead by orders of magnitude, but can also surpass the performance of conventional, quantum-resource-intensive approaches. Collectively, these findings establish predictive surrogates as a practical pathway to broadening the impact of advanced quantum processors.