 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniX: Unifying Autoregression and Diffusion for Chest X-Ray Understanding and Generation
Jan 16, 2026Despite recent progress, medical foundation models still struggle to unify visual understanding and generation, as these tasks have inherently conflicting goals: semantic abstraction versus pixel-level reconstruction. Existing approaches, typically based on parameter-shared autoregressive architectures, frequently lead to compromised performance in one or both tasks. To address this, we present UniX, a next-generation unified medical foundation model for chest X-ray understanding and generation. UniX decouples the two tasks into an autoregressive branch for understanding and a diffusion branch for high-fidelity generation. Crucially, a cross-modal self-attention mechanism is introduced to dynamically guide the generation process with understanding features. Coupled with a rigorous data cleaning pipeline and a multi-stage training strategy, this architecture enables synergistic collaboration between tasks while leveraging the strengths of diffusion models for superior generation. On two representative benchmarks, UniX achieves a 46.1% improvement in understanding performance (Micro-F1) and a 24.2% gain in generation quality (FD-RadDino), using only a quarter of the parameters of LLM-CXR. By achieving performance on par with task-specific models, our work establishes a scalable paradigm for synergistic medical image understanding and generation. Codes and models are available at https://github.com/ZrH42/UniX.
MeSS: City Mesh-Guided Outdoor Scene Generation with Cross-View Consistent Diffusion
Aug 21, 2025Mesh models have become increasingly accessible for numerous cities; however, the lack of realistic textures restricts their application in virtual urban navigation and autonomous driving. To address this, this paper proposes MeSS (Meshbased Scene Synthesis) for generating high-quality, styleconsistent outdoor scenes with city mesh models serving as the geometric prior. While image and video diffusion models can leverage spatial layouts (such as depth maps or HD maps) as control conditions to generate street-level perspective views, they are not directly applicable to 3D scene generation. Video diffusion models excel at synthesizing consistent view sequences that depict scenes but often struggle to adhere to predefined camera paths or align accurately with rendered control videos. In contrast, image diffusion models, though unable to guarantee cross-view visual consistency, can produce more geometry-aligned results when combined with ControlNet. Building on this insight, our approach enhances image diffusion models by improving cross-view consistency. The pipeline comprises three key stages: first, we generate geometrically consistent sparse views using Cascaded Outpainting ControlNets; second, we propagate denser intermediate views via a component dubbed AGInpaint; and third, we globally eliminate visual inconsistencies (e.g., varying exposure) using the GCAlign module. Concurrently with generation, a 3D Gaussian Splatting (3DGS) scene is reconstructed by initializing Gaussian balls on the mesh surface. Our method outperforms existing approaches in both geometric alignment and generation quality. Once synthesized, the scene can be rendered in diverse styles through relighting and style transfer techniques.
REX-RAG: Reasoning Exploration with Policy Correction in Retrieval-Augmented Generation
Aug 12, 2025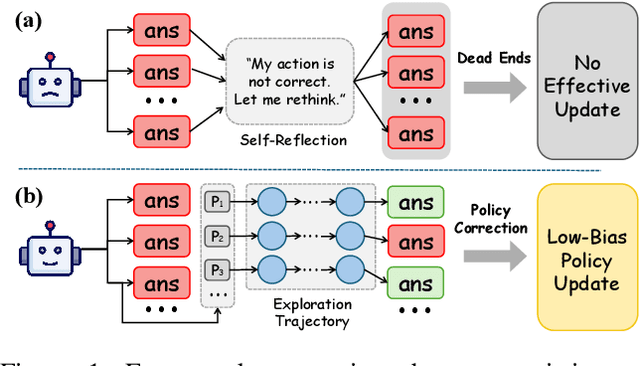
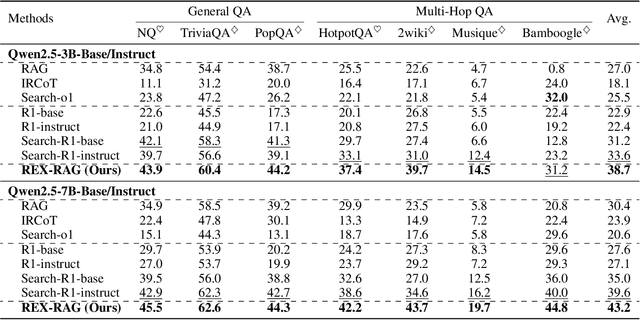
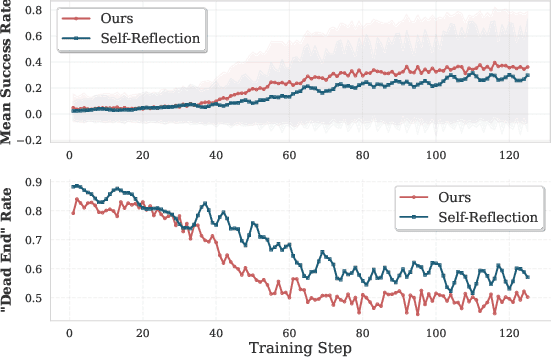
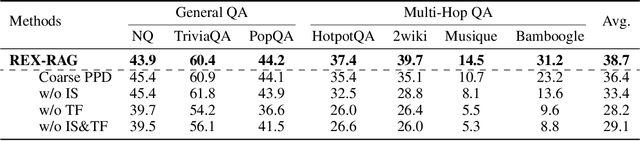
Reinforcement learning (RL) is emerging as a powerful paradigm for enabling large language models (LLMs) to perform complex reasoning tasks. Recent advances indicate that integrating RL with retrieval-augmented generation (RAG) allows LLMs to dynamically incorporate external knowledge, leading to more informed and robust decision making. However, we identify a critical challenge during policy-driven trajectory sampling: LLMs are frequently trapped in unproductive reasoning paths, which we refer to as "dead ends", committing to overconfident yet incorrect conclusions. This severely hampers exploration and undermines effective policy optimization. To address this challenge, we propose REX-RAG (Reasoning Exploration with Policy Correction in Retrieval-Augmented Generation), a novel framework that explores alternative reasoning paths while maintaining rigorous policy learning through principled distributional corrections. Our approach introduces two key innovations: (1) Mixed Sampling Strategy, which combines a novel probe sampling method with exploratory prompts to escape dead ends; and (2) Policy Correction Mechanism, which employs importance sampling to correct distribution shifts induced by mixed sampling, thereby mitigating gradient estimation bias. We evaluate it on seven question-answering benchmarks, and the experimental results show that REX-RAG achieves average performance gains of 5.1% on Qwen2.5-3B and 3.6% on Qwen2.5-7B over strong baselines, demonstrating competitive results across multiple datasets. The code is publicly available at https://github.com/MiliLab/REX-RAG.
Intra-Trajectory Consistency for Reward Modeling
Jun 10, 2025Reward models are critical for improving large language models (LLMs), particularly in reinforcement learning from human feedback (RLHF) or inference-time verification. Current reward modeling typically relies on scores of overall responses to learn the outcome rewards for the responses. However, since the response-level scores are coarse-grained supervision signals, the reward model struggles to identify the specific components within a response trajectory that truly correlate with the scores, leading to poor generalization on unseen responses. In this paper, we propose to leverage generation probabilities to establish reward consistency between processes in the response trajectory, which allows the response-level supervisory signal to propagate across processes, thereby providing additional fine-grained signals for reward learning. Building on analysis under the Bayesian framework, we develop an intra-trajectory consistency regularization to enforce that adjacent processes with higher next-token generation probability maintain more consistent rewards. We apply the proposed regularization to the advanced outcome reward model, improving its performance on RewardBench. Besides, we show that the reward model trained with the proposed regularization induces better DPO-aligned policies and achieves better best-of-N (BON) inference-time verification results. Our code is provided in https://github.com/chaoyang101/ICRM.
AnesBench: Multi-Dimensional Evaluation of LLM Reasoning in Anesthesiology
Apr 03, 2025The application of large language models (LLMs) in the medical field has gained significant attention, yet their reasoning capabilities in more specialized domains like anesthesiology remain underexplored. In this paper, we systematically evaluate the reasoning capabilities of LLMs in anesthesiology and analyze key factors influencing their performance. To this end, we introduce AnesBench, a cross-lingual benchmark designed to assess anesthesiology-related reasoning across three levels: factual retrieval (System 1), hybrid reasoning (System 1.x), and complex decision-making (System 2). Through extensive experiments, we first explore how model characteristics, including model scale, Chain of Thought (CoT) length, and language transferability, affect reasoning performance. Then, we further evaluate the effectiveness of different training strategies, leveraging our curated anesthesiology-related dataset, including continuous pre-training (CPT) and supervised fine-tuning (SFT). Additionally, we also investigate how the test-time reasoning techniques, such as Best-of-N sampling and beam search, influence reasoning performance, and assess the impact of reasoning-enhanced model distillation, specifically DeepSeek-R1. We will publicly release AnesBench, along with our CPT and SFT training datasets and evaluation code at https://github.com/MiliLab/AnesBench.
Dynamic Parallel Tree Search for Efficient LLM Reasoning
Feb 22, 2025Tree of Thoughts (ToT) enhances Large Language Model (LLM) reasoning by structuring problem-solving as a spanning tree. However, recent methods focus on search accuracy while overlooking computational efficiency. The challenges of accelerating the ToT lie in the frequent switching of reasoning focus, and the redundant exploration of suboptimal solutions. To alleviate this dilemma, we propose Dynamic Parallel Tree Search (DPTS), a novel parallelism framework that aims to dynamically optimize the reasoning path in inference. It includes the Parallelism Streamline in the generation phase to build up a flexible and adaptive parallelism with arbitrary paths by fine-grained cache management and alignment. Meanwhile, the Search and Transition Mechanism filters potential candidates to dynamically maintain the reasoning focus on more possible solutions and have less redundancy. Experiments on Qwen-2.5 and Llama-3 with Math500 and GSM8K datasets show that DPTS significantly improves efficiency by 2-4x on average while maintaining or even surpassing existing reasoning algorithms in accuracy, making ToT-based reasoning more scalable and computationally efficient.
MambaHSI: Spatial-Spectral Mamba for Hyperspectral Image Classification
Jan 09, 2025Transformer has been extensively explored for hyperspectral image (HSI) classification. However, transformer poses challenges in terms of speed and memory usage because of its quadratic computational complexity. Recently, the Mamba model has emerged as a promising approach, which has strong long-distance modeling capabilities while maintaining a linear computational complexity. However, representing the HSI is challenging for the Mamba due to the requirement for an integrated spatial and spectral understanding. To remedy these drawbacks, we propose a novel HSI classification model based on a Mamba model, named MambaHSI, which can simultaneously model long-range interaction of the whole image and integrate spatial and spectral information in an adaptive manner. Specifically, we design a spatial Mamba block (SpaMB) to model the long-range interaction of the whole image at the pixel-level. Then, we propose a spectral Mamba block (SpeMB) to split the spectral vector into multiple groups, mine the relations across different spectral groups, and extract spectral features. Finally, we propose a spatial-spectral fusion module (SSFM) to adaptively integrate spatial and spectral features of a HSI. To our best knowledge, this is the first image-level HSI classification model based on the Mamba. We conduct extensive experiments on four diverse HSI datasets. The results demonstrate the effectiveness and superiority of the proposed model for HSI classification. This reveals the great potential of Mamba to be the next-generation backbone for HSI models. Codes are available at https://github.com/li-yapeng/MambaHSI .
* accepted by IEEE TGRS
Detect Changes like Humans: Incorporating Semantic Priors for Improved Change Detection
Dec 22, 2024



When given two similar images, humans identify their differences by comparing the appearance ({\it e.g., color, texture}) with the help of semantics ({\it e.g., objects, relations}). However, mainstream change detection models adopt a supervised training paradigm, where the annotated binary change map is the main constraint. Thus, these methods primarily emphasize the difference-aware features between bi-temporal images and neglect the semantic understanding of the changed landscapes, which undermines the accuracy in the presence of noise and illumination variations. To this end, this paper explores incorporating semantic priors to improve the ability to detect changes. Firstly, we propose a Semantic-Aware Change Detection network, namely SA-CDNet, which transfers the common knowledge of the visual foundation models ({\it i.e., FastSAM}) to change detection. Inspired by the human visual paradigm, a novel dual-stream feature decoder is derived to distinguish changes by combining semantic-aware features and difference-aware features. Secondly, we design a single-temporal semantic pre-training strategy to enhance the semantic understanding of landscapes, which brings further increments. Specifically, we construct pseudo-change detection data from public single-temporal remote sensing segmentation datasets for large-scale pre-training, where an extra branch is also introduced for the proxy semantic segmentation task. Experimental results on five challenging benchmarks demonstrate the superiority of our method over the existing state-of-the-art methods. The code is available at \href{https://github.com/thislzm/SA-CD}{SA-CD}.
Can Language Models Perform Robust Reasoning in Chain-of-thought Prompting with Noisy Rationales?
Oct 31, 2024

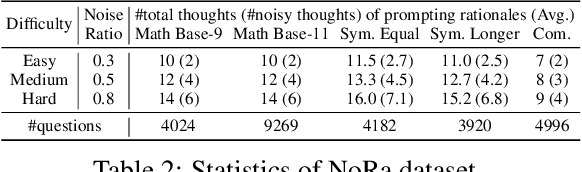
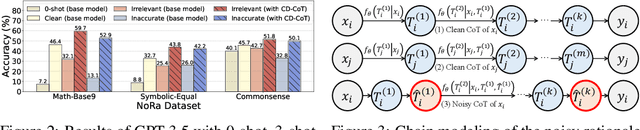
This paper investigates an under-explored challenge in large language models (LLMs): chain-of-thought prompting with noisy rationales, which include irrelevant or inaccurate reasoning thoughts within examples used for in-context learning. We construct NoRa dataset that is tailored to evaluate the robustness of reasoning in the presence of noisy rationales. Our findings on NoRa dataset reveal a prevalent vulnerability to such noise among current LLMs, with existing robust methods like self-correction and self-consistency showing limited efficacy. Notably, compared to prompting with clean rationales, base LLM drops by 1.4%-19.8% in accuracy with irrelevant thoughts and more drastically by 2.2%-40.4% with inaccurate thoughts. Addressing this challenge necessitates external supervision that should be accessible in practice. Here, we propose the method of contrastive denoising with noisy chain-of-thought (CD-CoT). It enhances LLMs' denoising-reasoning capabilities by contrasting noisy rationales with only one clean rationale, which can be the minimal requirement for denoising-purpose prompting. This method follows a principle of exploration and exploitation: (1) rephrasing and selecting rationales in the input space to achieve explicit denoising and (2) exploring diverse reasoning paths and voting on answers in the output space. Empirically, CD-CoT demonstrates an average improvement of 17.8% in accuracy over the base model and shows significantly stronger denoising capabilities than baseline methods. The source code is publicly available at: https://github.com/tmlr-group/NoisyRationales.
What If the Input is Expanded in OOD Detection?
Oct 24, 2024



Out-of-distribution (OOD) detection aims to identify OOD inputs from unknown classes, which is important for the reliable deployment of machine learning models in the open world. Various scoring functions are proposed to distinguish it from in-distribution (ID) data. However, existing methods generally focus on excavating the discriminative information from a single input, which implicitly limits its representation dimension. In this work, we introduce a novel perspective, i.e., employing different common corruptions on the input space, to expand that. We reveal an interesting phenomenon termed confidence mutation, where the confidence of OOD data can decrease significantly under the corruptions, while the ID data shows a higher confidence expectation considering the resistance of semantic features. Based on that, we formalize a new scoring method, namely, Confidence aVerage (CoVer), which can capture the dynamic differences by simply averaging the scores obtained from different corrupted inputs and the original ones, making the OOD and ID distributions more separable in detection tasks. Extensive experiments and analyses have been conducted to understand and verify the effectiveness of CoVer. The code is publicly available at: https://github.com/tmlr-group/CoVer.