 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttribution-Guided and Coverage-Maximized Pruning for Structural MoE Compression
Jun 16, 2026Mixture-of-Experts (MoE) models scale compute efficiently, yet remain expensive to deploy due to their substantial memory footprint and inference overhead. Prior compression methods mainly operate at the expert level, either removing entire experts or ranking experts by coarse-grained importance scores. However, such expert-wise decisions are often too coarse to capture fine-grained redundancy, leading to misallocated pruning budgets and limited compression. To address this problem, we observe that information within MoE experts is highly concentrated in a small subset of channels, leaving substantial redundancy even in experts deemed important. Based on this observation, we propose a structural pruning framework tailored for MoE models. Our method reformulates prune-ratio allocation as a channel-score coverage maximization problem and solves it efficiently using an attribution-based approximation. Experiments on DeepSeek and Qwen MoE models show that our method preserves model accuracy under 50% or 25% structured pruning when combined with 4-bit quantization. On Qwen3-30B-A3B, our approach reduces memory footprint by 5.27$\times$ and consistently outperforms state-of-the-art baselines across diverse benchmarks.
Diagonal-Tiled Mixed-Precision Attention for Efficient Low-Bit MXFP Inference
Apr 05, 2026Transformer-based large language models (LLMs) have demonstrated remarkable performance across a wide range of real-world tasks, but their inference cost remains prohibitively high due to the quadratic complexity of attention and the memory bandwidth limitations of high-precision operations. In this work, we present a low-bit mixed-precision attention kernel using the microscaling floating-point (MXFP) data format, utilizing the computing capability on next-generation GPU architectures. Our Diagonal-Tiled Mixed-Precision Attention (DMA) incorporates two kinds of low-bit computation at the tiling-level, and is a delicate fused kernel implemented using Triton, exploiting hardware-level parallelism and memory efficiency to enable fast and efficient inference without compromising model performance. Extensive empirical evaluations on NVIDIA B200 GPUs show that our kernel maintains generation quality with negligible degradation, and meanwhile achieves significant speedup by kernel fusion. We release our code at https://github.com/yifu-ding/MP-Sparse-Attn.
BWTA: Accurate and Efficient Binarized Transformer by Algorithm-Hardware Co-design
Apr 05, 2026Ultra low-bit quantization brings substantial efficiency for Transformer-based models, but the accuracy degradation and limited GPU support hinder its wide usage. In this paper, we analyze zero-point distortion in binarization and propose a Binary Weights & Ternary Activations (BWTA) quantization scheme, which projects tiny values to zero and preserves the accuracy of extremely low-bit models. For training, we propose Smooth Multi-Stage Quantization, combining a Levelwise Degradation Strategy and a Magnitude-Alignment Projection Factor to enable stable and fast convergence. For inference, we develop a BWTA MatMul CUDA kernel with instruction-level parallel bit-packing and comprehensive binary/ternary MatMul implementations for both linear and attention operators, allowing seamless integration across Transformer architectures. Experiments show that BWTA approaches full-precision performance for BERT, with an average 3.5% drop on GLUE and less than 2% drop on five tasks, and achieves comparable perplexity and accuracy for LLMs. In efficiency, it delivers 16 to 24 times kernel-level speedup over FP16 on NVIDIA GPUs, and 216 to 330 tokens/s end-to-end prefill speedup with lower memory footprint on LLMs. As an algorithm-hardware co-design, BWTA demonstrates practical, low-latency ultra-low-bit inference without sacrificing model quality.
SPA-Cache: Singular Proxies for Adaptive Caching in Diffusion Language Models
Jan 30, 2026While Diffusion Language Models (DLMs) offer a flexible, arbitrary-order alternative to the autoregressive paradigm, their non-causal nature precludes standard KV caching, forcing costly hidden state recomputation at every decoding step. Existing DLM caching approaches reduce this cost by selective hidden state updates; however, they are still limited by (i) costly token-wise update identification heuristics and (ii) rigid, uniform budget allocation that fails to account for heterogeneous hidden state dynamics. To address these challenges, we present SPA-Cache that jointly optimizes update identification and budget allocation in DLM cache. First, we derive a low-dimensional singular proxy that enables the identification of update-critical tokens in a low-dimensional subspace, substantially reducing the overhead of update identification. Second, we introduce an adaptive strategy that allocates fewer updates to stable layers without degrading generation quality. Together, these contributions significantly improve the efficiency of DLMs, yielding up to an $8\times$ throughput improvement over vanilla decoding and a $2$--$4\times$ speedup over existing caching baselines.
MoDES: Accelerating Mixture-of-Experts Multimodal Large Language Models via Dynamic Expert Skipping
Nov 19, 2025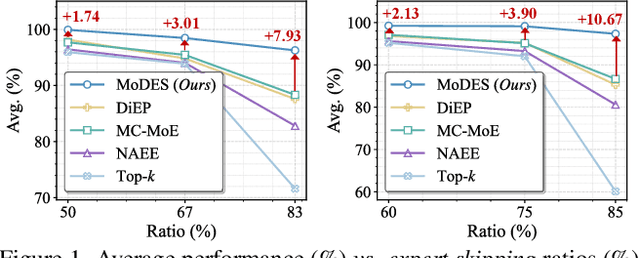

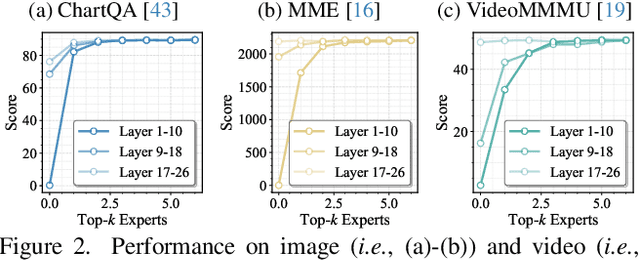
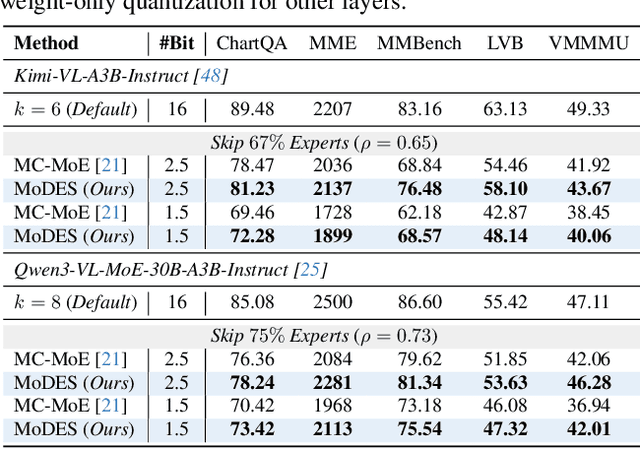
Mixture-of-Experts (MoE) Multimodal large language models (MLLMs) excel at vision-language tasks, but they suffer from high computational inefficiency. To reduce inference overhead, expert skipping methods have been proposed to deactivate redundant experts based on the current input tokens. However, we find that applying these methods-originally designed for unimodal large language models (LLMs)-to MLLMs results in considerable performance degradation. This is primarily because such methods fail to account for the heterogeneous contributions of experts across MoE layers and modality-specific behaviors of tokens within these layers. Motivated by these findings, we propose MoDES, the first training-free framework that adaptively skips experts to enable efficient and accurate MoE MLLM inference. It incorporates a globally-modulated local gating (GMLG) mechanism that integrates global layer-wise importance into local routing probabilities to accurately estimate per-token expert importance. A dual-modality thresholding (DMT) method is then applied, which processes tokens from each modality separately, to derive the skipping schedule. To set the optimal thresholds, we introduce a frontier search algorithm that exploits monotonicity properties, cutting convergence time from several days to a few hours. Extensive experiments for 3 model series across 13 benchmarks demonstrate that MoDES far outperforms previous approaches. For instance, when skipping 88% experts for Qwen3-VL-MoE-30B-A3B-Instruct, the performance boost is up to 10.67% (97.33% vs. 86.66%). Furthermore, MoDES significantly enhances inference speed, improving the prefilling time by 2.16$\times$ and the decoding time by 1.26$\times$.
VORTA: Efficient Video Diffusion via Routing Sparse Attention
May 24, 2025



Video Diffusion Transformers (VDiTs) have achieved remarkable progress in high-quality video generation, but remain computationally expensive due to the quadratic complexity of attention over high-dimensional video sequences. Recent attention acceleration methods leverage the sparsity of attention patterns to improve efficiency; however, they often overlook inefficiencies of redundant long-range interactions. To address this problem, we propose \textbf{VORTA}, an acceleration framework with two novel components: 1) a sparse attention mechanism that efficiently captures long-range dependencies, and 2) a routing strategy that adaptively replaces full 3D attention with specialized sparse attention variants throughout the sampling process. It achieves a $1.76\times$ end-to-end speedup without quality loss on VBench. Furthermore, VORTA can seamlessly integrate with various other acceleration methods, such as caching and step distillation, reaching up to $14.41\times$ speedup with negligible performance degradation. VORTA demonstrates its efficiency and enhances the practicality of VDiTs in real-world settings.
QVGen: Pushing the Limit of Quantized Video Generative Models
May 16, 2025Video diffusion models (DMs) have enabled high-quality video synthesis. Yet, their substantial computational and memory demands pose serious challenges to real-world deployment, even on high-end GPUs. As a commonly adopted solution, quantization has proven notable success in reducing cost for image DMs, while its direct application to video DMs remains ineffective. In this paper, we present QVGen, a novel quantization-aware training (QAT) framework tailored for high-performance and inference-efficient video DMs under extremely low-bit quantization (e.g., 4-bit or below). We begin with a theoretical analysis demonstrating that reducing the gradient norm is essential to facilitate convergence for QAT. To this end, we introduce auxiliary modules ($\Phi$) to mitigate large quantization errors, leading to significantly enhanced convergence. To eliminate the inference overhead of $\Phi$, we propose a rank-decay strategy that progressively eliminates $\Phi$. Specifically, we repeatedly employ singular value decomposition (SVD) and a proposed rank-based regularization $\mathbf{\gamma}$ to identify and decay low-contributing components. This strategy retains performance while zeroing out inference overhead. Extensive experiments across $4$ state-of-the-art (SOTA) video DMs, with parameter sizes ranging from $1.3$B $\sim14$B, show that QVGen is the first to reach full-precision comparable quality under 4-bit settings. Moreover, it significantly outperforms existing methods. For instance, our 3-bit CogVideoX-2B achieves improvements of $+25.28$ in Dynamic Degree and $+8.43$ in Scene Consistency on VBench.
Dynamic Parallel Tree Search for Efficient LLM Reasoning
Feb 22, 2025Tree of Thoughts (ToT) enhances Large Language Model (LLM) reasoning by structuring problem-solving as a spanning tree. However, recent methods focus on search accuracy while overlooking computational efficiency. The challenges of accelerating the ToT lie in the frequent switching of reasoning focus, and the redundant exploration of suboptimal solutions. To alleviate this dilemma, we propose Dynamic Parallel Tree Search (DPTS), a novel parallelism framework that aims to dynamically optimize the reasoning path in inference. It includes the Parallelism Streamline in the generation phase to build up a flexible and adaptive parallelism with arbitrary paths by fine-grained cache management and alignment. Meanwhile, the Search and Transition Mechanism filters potential candidates to dynamically maintain the reasoning focus on more possible solutions and have less redundancy. Experiments on Qwen-2.5 and Llama-3 with Math500 and GSM8K datasets show that DPTS significantly improves efficiency by 2-4x on average while maintaining or even surpassing existing reasoning algorithms in accuracy, making ToT-based reasoning more scalable and computationally efficient.
LLMCBench: Benchmarking Large Language Model Compression for Efficient Deployment
Oct 28, 2024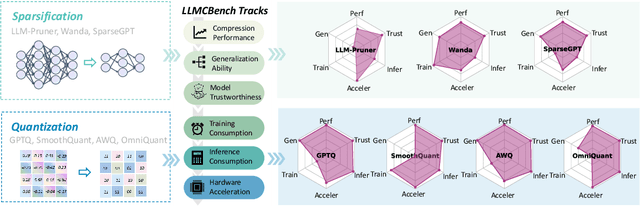
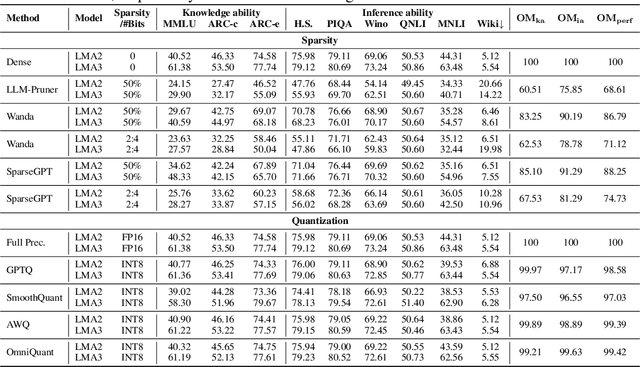
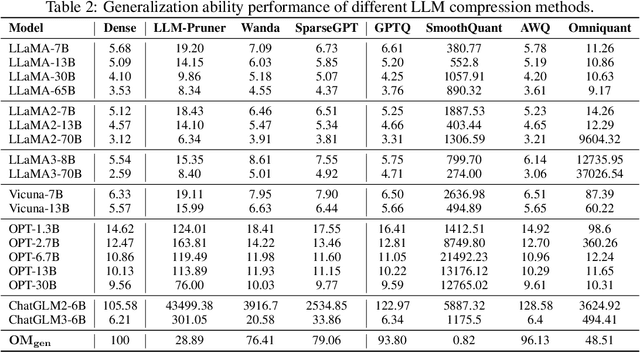
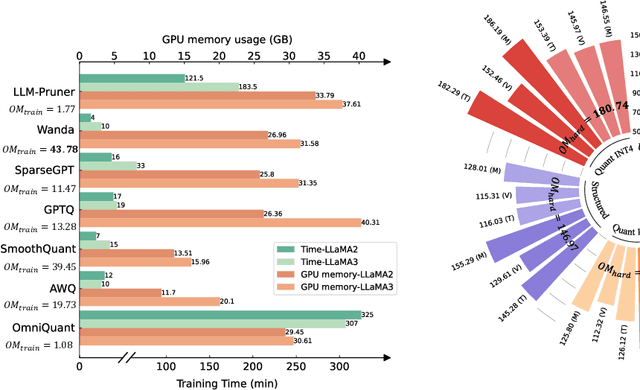
Although large language models (LLMs) have demonstrated their strong intelligence ability, the high demand for computation and storage hinders their practical application. To this end, many model compression techniques are proposed to increase the efficiency of LLMs. However, current researches only validate their methods on limited models, datasets, metrics, etc, and still lack a comprehensive evaluation under more general scenarios. So it is still a question of which model compression approach we should use under a specific case. To mitigate this gap, we present the Large Language Model Compression Benchmark (LLMCBench), a rigorously designed benchmark with an in-depth analysis for LLM compression algorithms. We first analyze the actual model production requirements and carefully design evaluation tracks and metrics. Then, we conduct extensive experiments and comparison using multiple mainstream LLM compression approaches. Finally, we perform an in-depth analysis based on the evaluation and provide useful insight for LLM compression design. We hope our LLMCBench can contribute insightful suggestions for LLM compression algorithm design and serve as a foundation for future research. Our code is available at https://github.com/AboveParadise/LLMCBench.
A Survey of Low-bit Large Language Models: Basics, Systems, and Algorithms
Sep 25, 2024



Large language models (LLMs) have achieved remarkable advancements in natural language processing, showcasing exceptional performance across various tasks. However, the expensive memory and computational requirements present significant challenges for their practical deployment. Low-bit quantization has emerged as a critical approach to mitigate these challenges by reducing the bit-width of model parameters, activations, and gradients, thus decreasing memory usage and computational demands. This paper presents a comprehensive survey of low-bit quantization methods tailored for LLMs, covering the fundamental principles, system implementations, and algorithmic strategies. An overview of basic concepts and new data formats specific to low-bit LLMs is first introduced, followed by a review of frameworks and systems that facilitate low-bit LLMs across various hardware platforms. Then, we categorize and analyze techniques and toolkits for efficient low-bit training and inference of LLMs. Finally, we conclude with a discussion of future trends and potential advancements of low-bit LLMs. Our systematic overview from basic, system, and algorithm perspectives can offer valuable insights and guidelines for future works to enhance the efficiency and applicability of LLMs through low-bit quantization.