 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Human Frontal View Synthesis from a Single Image
Mar 16, 2026Photorealistic human novel view synthesis from a single image is crucial for democratizing immersive 3D telepresence, eliminating the need for complex multi-camera setups. However, current rendering-centric methods prioritize visual fidelity over explicit geometric understanding and struggle with intricate regions like faces and hands, leading to temporal instability. Meanwhile, human-centric frameworks suffer from memory bottlenecks since they typically rely on an auxiliary model to provide informative structural priors for geometric modeling, which limits real-time performance. To address these challenges, we propose PrismMirror, a geometry-guided framework for instant frontal view synthesis from a single image. By avoiding external geometric modeling and focusing on frontal view synthesis, our model optimizes visual integrity for telepresence. Specifically, PrismMirror introduces a novel cascade learning strategy that enables coarse-to-fine geometric feature learning. It first directly learns coarse geometric features, such as SMPL-X meshes and point clouds, and then refines textures through rendering supervision. To achieve real-time efficiency, we distill this unified framework into a lightweight linear attention model. Notably, PrismMirror is the first monocular human frontal view synthesis model that achieves real-time inference at 24 FPS, significantly outperforming previous methods in both visual authenticity and structural accuracy.
Flash-VAED: Plug-and-Play VAE Decoders for Efficient Video Generation
Feb 22, 2026Latent diffusion models have enabled high-quality video synthesis, yet their inference remains costly and time-consuming. As diffusion transformers become increasingly efficient, the latency bottleneck inevitably shifts to VAE decoders. To reduce their latency while maintaining quality, we propose a universal acceleration framework for VAE decoders that preserves full alignment with the original latent distribution. Specifically, we propose (1) an independence-aware channel pruning method to effectively mitigate severe channel redundancy, and (2) a stage-wise dominant operator optimization strategy to address the high inference cost of the widely used causal 3D convolutions in VAE decoders. Based on these innovations, we construct a Flash-VAED family. Moreover, we design a three-phase dynamic distillation framework that efficiently transfers the capabilities of the original VAE decoder to Flash-VAED. Extensive experiments on Wan and LTX-Video VAE decoders demonstrate that our method outperforms baselines in both quality and speed, achieving approximately a 6$\times$ speedup while maintaining the reconstruction performance up to 96.9%. Notably, Flash-VAED accelerates the end-to-end generation pipeline by up to 36% with negligible quality drops on VBench-2.0.
Light Forcing: Accelerating Autoregressive Video Diffusion via Sparse Attention
Feb 04, 2026Advanced autoregressive (AR) video generation models have improved visual fidelity and interactivity, but the quadratic complexity of attention remains a primary bottleneck for efficient deployment. While existing sparse attention solutions have shown promise on bidirectional models, we identify that applying these solutions to AR models leads to considerable performance degradation for two reasons: isolated consideration of chunk generation and insufficient utilization of past informative context. Motivated by these observations, we propose \textsc{Light Forcing}, the \textit{first} sparse attention solution tailored for AR video generation models. It incorporates a \textit{Chunk-Aware Growth} mechanism to quantitatively estimate the contribution of each chunk, which determines their sparsity allocation. This progressive sparsity increase strategy enables the current chunk to inherit prior knowledge in earlier chunks during generation. Additionally, we introduce a \textit{Hierarchical Sparse Attention} to capture informative historical and local context in a coarse-to-fine manner. Such two-level mask selection strategy (\ie, frame and block level) can adaptively handle diverse attention patterns. Extensive experiments demonstrate that our method outperforms existing sparse attention in quality (\eg, 84.5 on VBench) and efficiency (\eg, $1.2{\sim}1.3\times$ end-to-end speedup). Combined with FP8 quantization and LightVAE, \textsc{Light Forcing} further achieves a $2.3\times$ speedup and 19.7\,FPS on an RTX~5090 GPU. Code will be released at \href{https://github.com/chengtao-lv/LightForcing}{https://github.com/chengtao-lv/LightForcing}.
Focus-dLLM: Accelerating Long-Context Diffusion LLM Inference via Confidence-Guided Context Focusing
Feb 02, 2026Diffusion Large Language Models (dLLMs) deliver strong long-context processing capability in a non-autoregressive decoding paradigm. However, the considerable computational cost of bidirectional full attention limits the inference efficiency. Although sparse attention is promising, existing methods remain ineffective. This stems from the need to estimate attention importance for tokens yet to be decoded, while the unmasked token positions are unknown during diffusion. In this paper, we present Focus-dLLM, a novel training-free attention sparsification framework tailored for accurate and efficient long-context dLLM inference. Based on the finding that token confidence strongly correlates across adjacent steps, we first design a past confidence-guided indicator to predict unmasked regions. Built upon this, we propose a sink-aware pruning strategy to accurately estimate and remove redundant attention computation, while preserving highly influential attention sinks. To further reduce overhead, this strategy reuses identified sink locations across layers, leveraging the observed cross-layer consistency. Experimental results show that our method offers more than $29\times$ lossless speedup under $32K$ context length. The code is publicly available at: https://github.com/Longxmas/Focus-dLLM
MoDES: Accelerating Mixture-of-Experts Multimodal Large Language Models via Dynamic Expert Skipping
Nov 19, 2025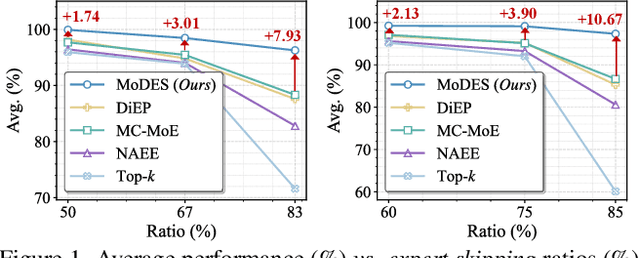

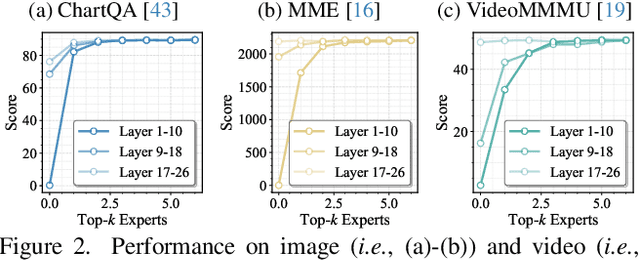
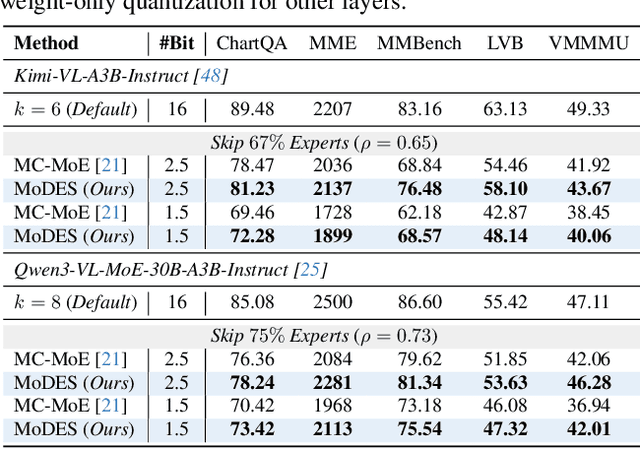
Mixture-of-Experts (MoE) Multimodal large language models (MLLMs) excel at vision-language tasks, but they suffer from high computational inefficiency. To reduce inference overhead, expert skipping methods have been proposed to deactivate redundant experts based on the current input tokens. However, we find that applying these methods-originally designed for unimodal large language models (LLMs)-to MLLMs results in considerable performance degradation. This is primarily because such methods fail to account for the heterogeneous contributions of experts across MoE layers and modality-specific behaviors of tokens within these layers. Motivated by these findings, we propose MoDES, the first training-free framework that adaptively skips experts to enable efficient and accurate MoE MLLM inference. It incorporates a globally-modulated local gating (GMLG) mechanism that integrates global layer-wise importance into local routing probabilities to accurately estimate per-token expert importance. A dual-modality thresholding (DMT) method is then applied, which processes tokens from each modality separately, to derive the skipping schedule. To set the optimal thresholds, we introduce a frontier search algorithm that exploits monotonicity properties, cutting convergence time from several days to a few hours. Extensive experiments for 3 model series across 13 benchmarks demonstrate that MoDES far outperforms previous approaches. For instance, when skipping 88% experts for Qwen3-VL-MoE-30B-A3B-Instruct, the performance boost is up to 10.67% (97.33% vs. 86.66%). Furthermore, MoDES significantly enhances inference speed, improving the prefilling time by 2.16$\times$ and the decoding time by 1.26$\times$.
LLMC+: Benchmarking Vision-Language Model Compression with a Plug-and-play Toolkit
Aug 13, 2025Large Vision-Language Models (VLMs) exhibit impressive multi-modal capabilities but suffer from prohibitive computational and memory demands, due to their long visual token sequences and massive parameter sizes. To address these issues, recent works have proposed training-free compression methods. However, existing efforts often suffer from three major limitations: (1) Current approaches do not decompose techniques into comparable modules, hindering fair evaluation across spatial and temporal redundancy. (2) Evaluation confined to simple single-turn tasks, failing to reflect performance in realistic scenarios. (3) Isolated use of individual compression techniques, without exploring their joint potential. To overcome these gaps, we introduce LLMC+, a comprehensive VLM compression benchmark with a versatile, plug-and-play toolkit. LLMC+ supports over 20 algorithms across five representative VLM families and enables systematic study of token-level and model-level compression. Our benchmark reveals that: (1) Spatial and temporal redundancies demand distinct technical strategies. (2) Token reduction methods degrade significantly in multi-turn dialogue and detail-sensitive tasks. (3) Combining token and model compression achieves extreme compression with minimal performance loss. We believe LLMC+ will facilitate fair evaluation and inspire future research in efficient VLM. Our code is available at https://github.com/ModelTC/LightCompress.
SlimInfer: Accelerating Long-Context LLM Inference via Dynamic Token Pruning
Aug 08, 2025Long-context inference for Large Language Models (LLMs) is heavily limited by high computational demands. While several existing methods optimize attention computation, they still process the full set of hidden states at each layer, limiting overall efficiency. In this work, we propose SlimInfer, an innovative framework that aims to accelerate inference by directly pruning less critical prompt tokens during the forward pass. Our key insight is an information diffusion phenomenon: As information from critical tokens propagates through layers, it becomes distributed across the entire sequence. This diffusion process suggests that LLMs can maintain their semantic integrity when excessive tokens, even including these critical ones, are pruned in hidden states. Motivated by this, SlimInfer introduces a dynamic fine-grained pruning mechanism that accurately removes redundant tokens of hidden state at intermediate layers. This layer-wise pruning naturally enables an asynchronous KV cache manager that prefetches required token blocks without complex predictors, reducing both memory usage and I/O costs. Extensive experiments show that SlimInfer can achieve up to $\mathbf{2.53\times}$ time-to-first-token (TTFT) speedup and $\mathbf{1.88\times}$ end-to-end latency reduction for LLaMA3.1-8B-Instruct on a single RTX 4090, without sacrificing performance on LongBench. Our code will be released upon acceptance.
QVGen: Pushing the Limit of Quantized Video Generative Models
May 16, 2025Video diffusion models (DMs) have enabled high-quality video synthesis. Yet, their substantial computational and memory demands pose serious challenges to real-world deployment, even on high-end GPUs. As a commonly adopted solution, quantization has proven notable success in reducing cost for image DMs, while its direct application to video DMs remains ineffective. In this paper, we present QVGen, a novel quantization-aware training (QAT) framework tailored for high-performance and inference-efficient video DMs under extremely low-bit quantization (e.g., 4-bit or below). We begin with a theoretical analysis demonstrating that reducing the gradient norm is essential to facilitate convergence for QAT. To this end, we introduce auxiliary modules ($\Phi$) to mitigate large quantization errors, leading to significantly enhanced convergence. To eliminate the inference overhead of $\Phi$, we propose a rank-decay strategy that progressively eliminates $\Phi$. Specifically, we repeatedly employ singular value decomposition (SVD) and a proposed rank-based regularization $\mathbf{\gamma}$ to identify and decay low-contributing components. This strategy retains performance while zeroing out inference overhead. Extensive experiments across $4$ state-of-the-art (SOTA) video DMs, with parameter sizes ranging from $1.3$B $\sim14$B, show that QVGen is the first to reach full-precision comparable quality under 4-bit settings. Moreover, it significantly outperforms existing methods. For instance, our 3-bit CogVideoX-2B achieves improvements of $+25.28$ in Dynamic Degree and $+8.43$ in Scene Consistency on VBench.
PTSBench: A Comprehensive Post-Training Sparsity Benchmark Towards Algorithms and Models
Dec 10, 2024With the increased attention to model efficiency, post-training sparsity (PTS) has become more and more prevalent because of its effectiveness and efficiency. However, there remain questions on better practice of PTS algorithms and the sparsification ability of models, which hinders the further development of this area. Therefore, a benchmark to comprehensively investigate the issues above is urgently needed. In this paper, we propose the first comprehensive post-training sparsity benchmark called PTSBench towards algorithms and models. We benchmark 10+ PTS general-pluggable fine-grained techniques on 3 typical tasks using over 40 off-the-shelf model architectures. Through extensive experiments and analyses, we obtain valuable conclusions and provide several insights from both algorithms and model aspects. Our PTSBench can provide (1) new observations for a better understanding of the PTS algorithms, (2) in-depth and comprehensive evaluations for the sparsification ability of models, and (3) a well-structured and easy-integrate open-source framework. We hope this work will provide illuminating conclusions and advice for future studies of post-training sparsity methods and sparsification-friendly model design. The code for our PTSBench is released at \href{https://github.com/ModelTC/msbench}{https://github.com/ModelTC/msbench}.
HarmoniCa: Harmonizing Training and Inference for Better Feature Cache in Diffusion Transformer Acceleration
Oct 02, 2024Diffusion Transformers (DiTs) have gained prominence for outstanding scalability and extraordinary performance in generative tasks. However, their considerable inference costs impede practical deployment. The feature cache mechanism, which involves storing and retrieving redundant computations across timesteps, holds promise for reducing per-step inference time in diffusion models. Most existing caching methods for DiT are manually designed. Although the learning-based approach attempts to optimize strategies adaptively, it suffers from discrepancies between training and inference, which hampers both the performance and acceleration ratio. Upon detailed analysis, we pinpoint that these discrepancies primarily stem from two aspects: (1) Prior Timestep Disregard, where training ignores the effect of cache usage at earlier timesteps, and (2) Objective Mismatch, where the training target (align predicted noise in each timestep) deviates from the goal of inference (generate the high-quality image). To alleviate these discrepancies, we propose HarmoniCa, a novel method that Harmonizes training and inference with a novel learning-based Caching framework built upon Step-Wise Denoising Training (SDT) and Image Error Proxy-Guided Objective (IEPO). Compared to the traditional training paradigm, the newly proposed SDT maintains the continuity of the denoising process, enabling the model to leverage information from prior timesteps during training, similar to the way it operates during inference. Furthermore, we design IEPO, which integrates an efficient proxy mechanism to approximate the final image error caused by reusing the cached feature. Therefore, IEPO helps balance final image quality and cache utilization, resolving the issue of training that only considers the impact of cache usage on the predicted output at each timestep.