 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMC+: Benchmarking Vision-Language Model Compression with a Plug-and-play Toolkit
Aug 13, 2025Large Vision-Language Models (VLMs) exhibit impressive multi-modal capabilities but suffer from prohibitive computational and memory demands, due to their long visual token sequences and massive parameter sizes. To address these issues, recent works have proposed training-free compression methods. However, existing efforts often suffer from three major limitations: (1) Current approaches do not decompose techniques into comparable modules, hindering fair evaluation across spatial and temporal redundancy. (2) Evaluation confined to simple single-turn tasks, failing to reflect performance in realistic scenarios. (3) Isolated use of individual compression techniques, without exploring their joint potential. To overcome these gaps, we introduce LLMC+, a comprehensive VLM compression benchmark with a versatile, plug-and-play toolkit. LLMC+ supports over 20 algorithms across five representative VLM families and enables systematic study of token-level and model-level compression. Our benchmark reveals that: (1) Spatial and temporal redundancies demand distinct technical strategies. (2) Token reduction methods degrade significantly in multi-turn dialogue and detail-sensitive tasks. (3) Combining token and model compression achieves extreme compression with minimal performance loss. We believe LLMC+ will facilitate fair evaluation and inspire future research in efficient VLM. Our code is available at https://github.com/ModelTC/LightCompress.
PTSBench: A Comprehensive Post-Training Sparsity Benchmark Towards Algorithms and Models
Dec 10, 2024With the increased attention to model efficiency, post-training sparsity (PTS) has become more and more prevalent because of its effectiveness and efficiency. However, there remain questions on better practice of PTS algorithms and the sparsification ability of models, which hinders the further development of this area. Therefore, a benchmark to comprehensively investigate the issues above is urgently needed. In this paper, we propose the first comprehensive post-training sparsity benchmark called PTSBench towards algorithms and models. We benchmark 10+ PTS general-pluggable fine-grained techniques on 3 typical tasks using over 40 off-the-shelf model architectures. Through extensive experiments and analyses, we obtain valuable conclusions and provide several insights from both algorithms and model aspects. Our PTSBench can provide (1) new observations for a better understanding of the PTS algorithms, (2) in-depth and comprehensive evaluations for the sparsification ability of models, and (3) a well-structured and easy-integrate open-source framework. We hope this work will provide illuminating conclusions and advice for future studies of post-training sparsity methods and sparsification-friendly model design. The code for our PTSBench is released at \href{https://github.com/ModelTC/msbench}{https://github.com/ModelTC/msbench}.
Reducing Events to Augment Log-based Anomaly Detection Models: An Empirical Study
Sep 07, 2024As software systems grow increasingly intricate, the precise detection of anomalies have become both essential and challenging. Current log-based anomaly detection methods depend heavily on vast amounts of log data leading to inefficient inference and potential misguidance by noise logs. However, the quantitative effects of log reduction on the effectiveness of anomaly detection remain unexplored. Therefore, we first conduct a comprehensive study on six distinct models spanning three datasets. Through the study, the impact of log quantity and their effectiveness in representing anomalies is qualifies, uncovering three distinctive log event types that differently influence model performance. Drawing from these insights, we propose LogCleaner: an efficient methodology for the automatic reduction of log events in the context of anomaly detection. Serving as middleware between software systems and models, LogCleaner continuously updates and filters anti-events and duplicative-events in the raw generated logs. Experimental outcomes highlight LogCleaner's capability to reduce over 70% of log events in anomaly detection, accelerating the model's inference speed by approximately 300%, and universally improving the performance of models for anomaly detection.
Fast and Controllable Post-training Sparsity: Learning Optimal Sparsity Allocation with Global Constraint in Minutes
May 09, 2024Neural network sparsity has attracted many research interests due to its similarity to biological schemes and high energy efficiency. However, existing methods depend on long-time training or fine-tuning, which prevents large-scale applications. Recently, some works focusing on post-training sparsity (PTS) have emerged. They get rid of the high training cost but usually suffer from distinct accuracy degradation due to neglect of the reasonable sparsity rate at each layer. Previous methods for finding sparsity rates mainly focus on the training-aware scenario, which usually fails to converge stably under the PTS setting with limited data and much less training cost. In this paper, we propose a fast and controllable post-training sparsity (FCPTS) framework. By incorporating a differentiable bridge function and a controllable optimization objective, our method allows for rapid and accurate sparsity allocation learning in minutes, with the added assurance of convergence to a predetermined global sparsity rate. Equipped with these techniques, we can surpass the state-of-the-art methods by a large margin, e.g., over 30\% improvement for ResNet-50 on ImageNet under the sparsity rate of 80\%. Our plug-and-play code and supplementary materials are open-sourced at https://github.com/ModelTC/FCPTS.
LLM-QBench: A Benchmark Towards the Best Practice for Post-training Quantization of Large Language Models
May 09, 2024



Recent advancements in large language models (LLMs) are propelling us toward artificial general intelligence, thanks to their remarkable emergent abilities and reasoning capabilities. However, the substantial computational and memory requirements of LLMs limit their widespread adoption. Quan- tization, a key compression technique, offers a viable solution to mitigate these demands by compressing and accelerating LLMs, albeit with poten- tial risks to model accuracy. Numerous studies have aimed to minimize the accuracy loss associated with quantization. However, the quantization configurations in these studies vary and may not be optimized for hard- ware compatibility. In this paper, we focus on identifying the most effective practices for quantizing LLMs, with the goal of balancing performance with computational efficiency. For a fair analysis, we develop a quantization toolkit LLMC, and design four crucial principles considering the inference efficiency, quantized accuracy, calibration cost, and modularization. By benchmarking on various models and datasets with over 500 experiments, three takeaways corresponding to calibration data, quantization algorithm, and quantization schemes are derived. Finally, a best practice of LLM PTQ pipeline is constructed. All the benchmark results and the toolkit can be found at https://github.com/ModelTC/llmc.
Compressing Models with Few Samples: Mimicking then Replacing
Jan 07, 2022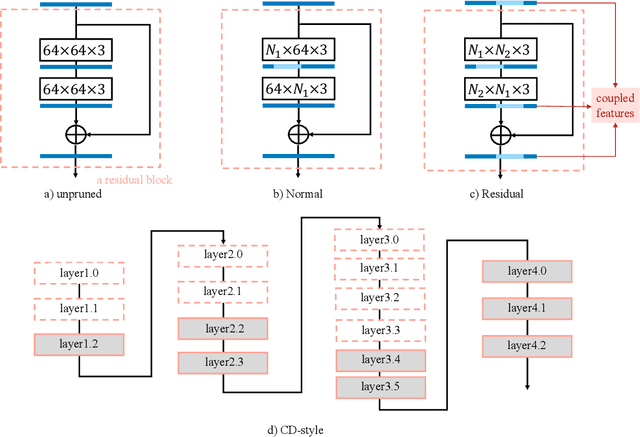

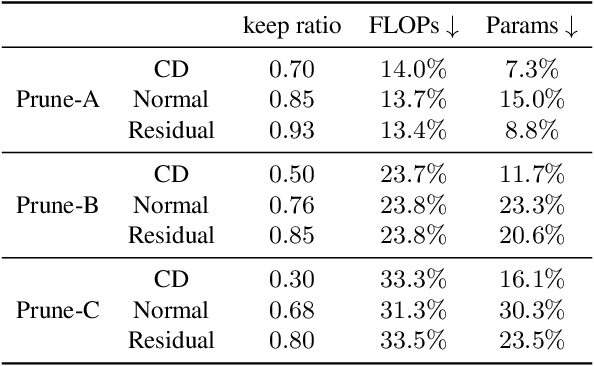
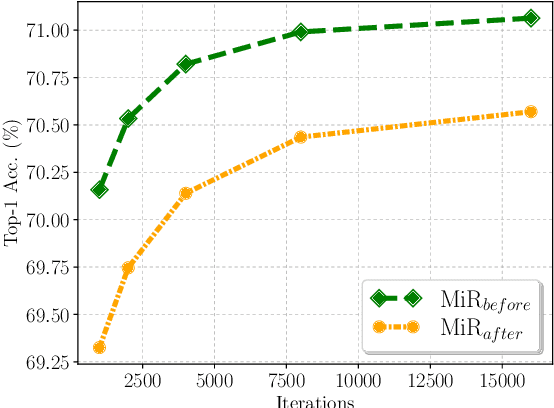
Few-sample compression aims to compress a big redundant model into a small compact one with only few samples. If we fine-tune models with these limited few samples directly, models will be vulnerable to overfit and learn almost nothing. Hence, previous methods optimize the compressed model layer-by-layer and try to make every layer have the same outputs as the corresponding layer in the teacher model, which is cumbersome. In this paper, we propose a new framework named Mimicking then Replacing (MiR) for few-sample compression, which firstly urges the pruned model to output the same features as the teacher's in the penultimate layer, and then replaces teacher's layers before penultimate with a well-tuned compact one. Unlike previous layer-wise reconstruction methods, our MiR optimizes the entire network holistically, which is not only simple and effective, but also unsupervised and general. MiR outperforms previous methods with large margins. Codes will be available soon.
Design and implementation of smart cooking based on amazon echo
Dec 04, 2018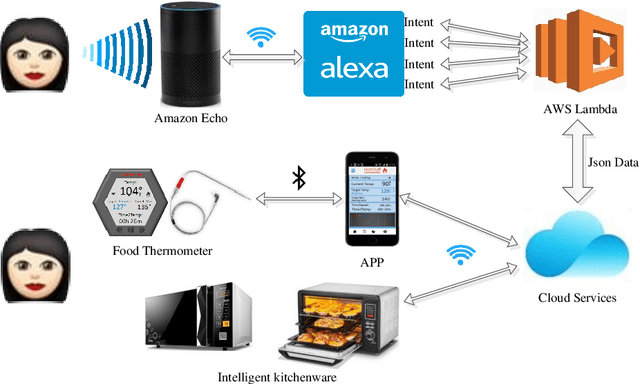
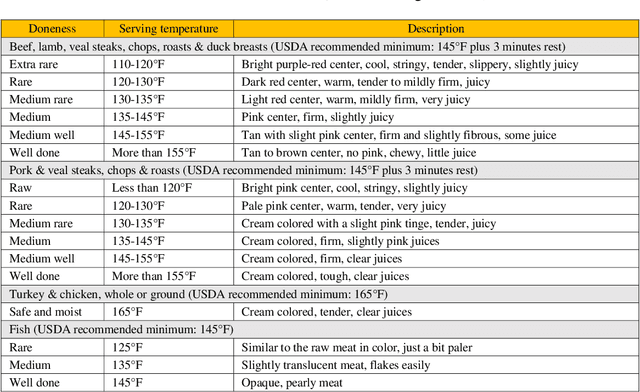
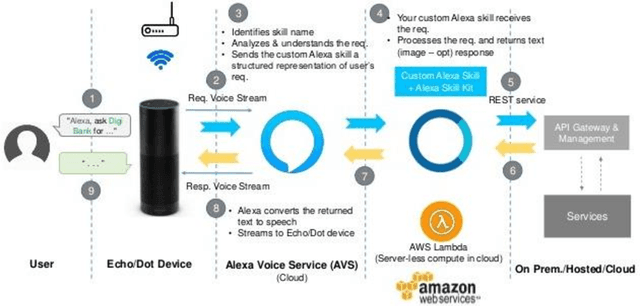
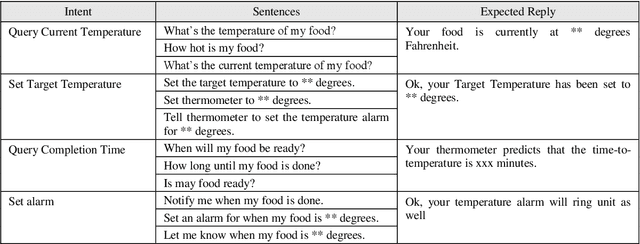
Smart cooking based on Amazon Echo uses the internet of things and cloud computing to assist in cooking food. People may speak to Amazon Echo during the cooking in order to get the information and situation of the cooking. Amazon Echo recognizes what people say, then transfers the information to the cloud services, and speaks to people the results that cloud services make by querying the embedded cooking knowledge and achieving the information of intelligent kitchen devices online. An intelligent food thermometer and its mobile application are well-designed and implemented to monitor the temperature of cooking food.
* 9 pages, 3 figures, 2 tables