 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Long-Context Modeling in Diffusion Language Models via Block Approximate Sparse Attention
May 19, 2026Diffusion Language Models (DLMs) enable globally coherent, bidirectional, and controllable text generation, offering advantages over traditional autoregressive LLMs, while scaling to ultra-long sequences remains costly. Many existing block-sparse attention methods select blocks by fixed sampling patterns over the high-resolution attention space, such as tail regions or anti-diagonal stripes. Such prior-driven sampling can miss salient tokens and introduce instability under distribution shifts. In this paper, we propose the Block Approximate Sparse Attention framework (BA-Att) with block-wise pre-downsampled operation, which identifies informative regions within a compact downsampled space, avoiding reliance on brittle positional priors. To analyze its theoretical behavior, we define an oracle post-downsample attention map and formalize the approximation error between pre- and post-downsample schemes. Based on this insight, we introduce a lightweight norm-sorting module and a covariance-compensated correction that approximates full covariance using diagonal QK variances, reducing computational complexity. Extensive experiments show that our operator achieves up to 6.95x acceleration over FlashAttention in attention computation, and maintains near full-attention performance at 50% sparsity across language models, multimodal language models, and video generation models, demonstrating strong efficiency and generalization.
MDP3: A Training-free Approach for List-wise Frame Selection in Video-LLMs
Jan 06, 2025

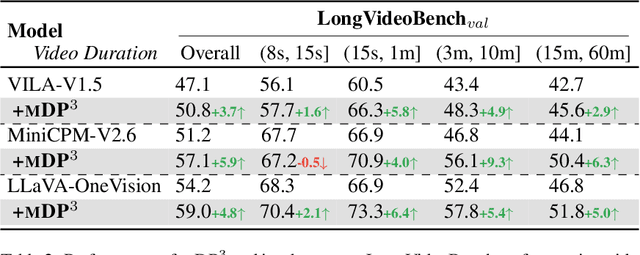

Video large language models (Video-LLMs) have made significant progress in understanding videos. However, processing multiple frames leads to lengthy visual token sequences, presenting challenges such as the limited context length cannot accommodate the entire video, and the inclusion of irrelevant frames hinders visual perception. Hence, effective frame selection is crucial. This paper emphasizes that frame selection should follow three key principles: query relevance, list-wise diversity, and sequentiality. Existing methods, such as uniform frame sampling and query-frame matching, do not capture all of these principles. Thus, we propose Markov decision determinantal point process with dynamic programming (MDP3) for frame selection, a training-free and model-agnostic method that can be seamlessly integrated into existing Video-LLMs. Our method first estimates frame similarities conditioned on the query using a conditional Gaussian kernel within the reproducing kernel Hilbert space~(RKHS). We then apply the determinantal point process~(DPP) to the similarity matrix to capture both query relevance and list-wise diversity. To incorporate sequentiality, we segment the video and apply DPP within each segment, conditioned on the preceding segment selection, modeled as a Markov decision process~(MDP) for allocating selection sizes across segments. Theoretically, MDP3 provides a \((1 - 1/e)\)-approximate solution to the NP-hard list-wise frame selection problem with pseudo-polynomial time complexity, demonstrating its efficiency. Empirically, MDP3 significantly outperforms existing methods, verifying its effectiveness and robustness.
Multi-Agent Conversational Online Learning for Adaptive LLM Response Identification
Jan 03, 2025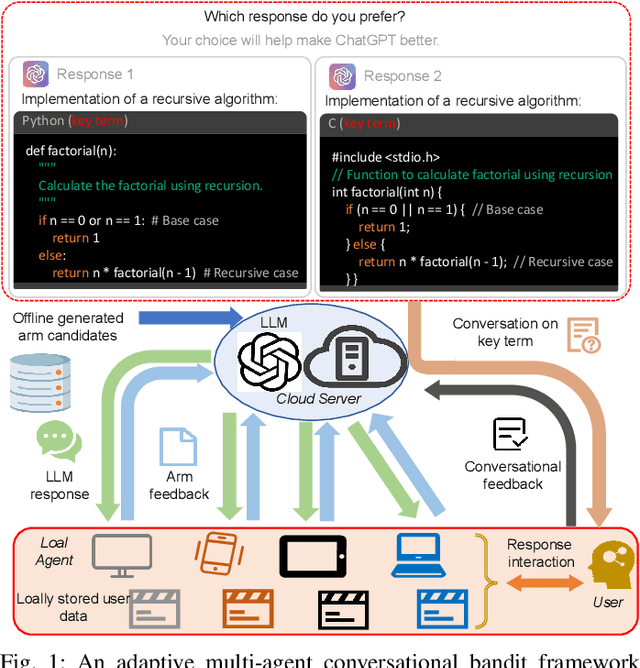


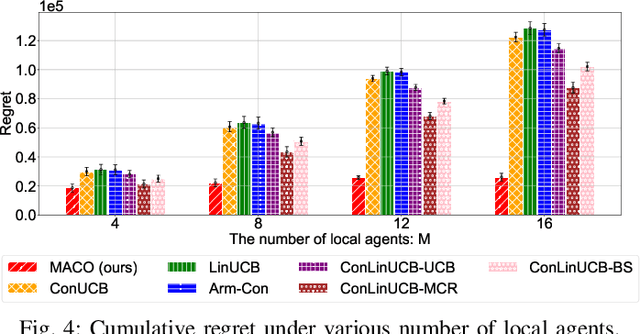
The remarkable generative capability of large language models (LLMs) has sparked a growing interest in automatically generating responses for different applications. Given the dynamic nature of user preferences and the uncertainty of LLM response performance, it is crucial to design efficient online learning algorithms to identify optimal LLM responses (i.e., high-quality responses that also meet user preferences). Most existing online algorithms adopt a centralized approach and fail to leverage explicit user preferences for more efficient and personalized LLM response identification. In contrast, this paper introduces \textit{MACO} (\underline{M}ulti-\underline{A}gent \underline{C}onversational \underline{O}nline Learning for Adaptive LLM Response Identification): 1) The online LLM response identification process is accelerated by multiple local agents (such as smartphones), while enhancing data privacy; 2) A novel conversational mechanism is proposed to adaptively conduct conversations for soliciting user preferences (e.g., a preference for a humorous tone over a serious one in generated responses), so to minimize uncertainty in preference estimation. Our theoretical analysis demonstrates that \cadi\ is near-optimal regarding cumulative regret. Additionally, \cadi\ offers reduced communication costs and computational complexity by eliminating the traditional, computing-intensive ``G-optimal design" found in previous works. Extensive experiments with the open LLM \textit{Llama}, coupled with two different embedding models from Google and OpenAI for text vector representation, demonstrate that \cadi\ significantly outperforms the current state-of-the-art in online LLM response identification.
Frame-Voyager: Learning to Query Frames for Video Large Language Models
Oct 07, 2024Video Large Language Models (Video-LLMs) have made remarkable progress in video understanding tasks. However, they are constrained by the maximum length of input tokens, making it impractical to input entire videos. Existing frame selection approaches, such as uniform frame sampling and text-frame retrieval, fail to account for the information density variations in the videos or the complex instructions in the tasks, leading to sub-optimal performance. In this paper, we propose Frame-Voyager that learns to query informative frame combinations, based on the given textual queries in the task. To train Frame-Voyager, we introduce a new data collection and labeling pipeline, by ranking frame combinations using a pre-trained Video-LLM. Given a video of M frames, we traverse its T-frame combinations, feed them into a Video-LLM, and rank them based on Video-LLM's prediction losses. Using this ranking as supervision, we train Frame-Voyager to query the frame combinations with lower losses. In experiments, we evaluate Frame-Voyager on four Video Question Answering benchmarks by plugging it into two different Video-LLMs. The experimental results demonstrate that Frame-Voyager achieves impressive results in all settings, highlighting its potential as a plug-and-play solution for Video-LLMs.
Neural Radiance Fields with Torch Units
Apr 03, 2024



Neural Radiance Fields (NeRF) give rise to learning-based 3D reconstruction methods widely used in industrial applications. Although prevalent methods achieve considerable improvements in small-scale scenes, accomplishing reconstruction in complex and large-scale scenes is still challenging. First, the background in complex scenes shows a large variance among different views. Second, the current inference pattern, $i.e.$, a pixel only relies on an individual camera ray, fails to capture contextual information. To solve these problems, we propose to enlarge the ray perception field and build up the sample points interactions. In this paper, we design a novel inference pattern that encourages a single camera ray possessing more contextual information, and models the relationship among sample points on each camera ray. To hold contextual information,a camera ray in our proposed method can render a patch of pixels simultaneously. Moreover, we replace the MLP in neural radiance field models with distance-aware convolutions to enhance the feature propagation among sample points from the same camera ray. To summarize, as a torchlight, a ray in our proposed method achieves rendering a patch of image. Thus, we call the proposed method, Torch-NeRF. Extensive experiments on KITTI-360 and LLFF show that the Torch-NeRF exhibits excellent performance.
PUPS: Point Cloud Unified Panoptic Segmentation
Feb 28, 2023Point cloud panoptic segmentation is a challenging task that seeks a holistic solution for both semantic and instance segmentation to predict groupings of coherent points. Previous approaches treat semantic and instance segmentation as surrogate tasks, and they either use clustering methods or bounding boxes to gather instance groupings with costly computation and hand-crafted designs in the instance segmentation task. In this paper, we propose a simple but effective point cloud unified panoptic segmentation (PUPS) framework, which use a set of point-level classifiers to directly predict semantic and instance groupings in an end-to-end manner. To realize PUPS, we introduce bipartite matching to our training pipeline so that our classifiers are able to exclusively predict groupings of instances, getting rid of hand-crafted designs, e.g. anchors and Non-Maximum Suppression (NMS). In order to achieve better grouping results, we utilize a transformer decoder to iteratively refine the point classifiers and develop a context-aware CutMix augmentation to overcome the class imbalance problem. As a result, PUPS achieves 1st place on the leader board of SemanticKITTI panoptic segmentation task and state-of-the-art results on nuScenes.
F3A-GAN: Facial Flow for Face Animation with Generative Adversarial Networks
May 13, 2022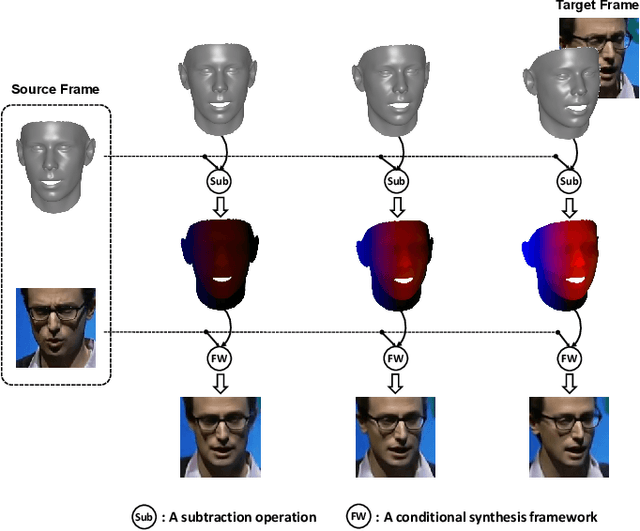



Formulated as a conditional generation problem, face animation aims at synthesizing continuous face images from a single source image driven by a set of conditional face motion. Previous works mainly model the face motion as conditions with 1D or 2D representation (e.g., action units, emotion codes, landmark), which often leads to low-quality results in some complicated scenarios such as continuous generation and largepose transformation. To tackle this problem, the conditions are supposed to meet two requirements, i.e., motion information preserving and geometric continuity. To this end, we propose a novel representation based on a 3D geometric flow, termed facial flow, to represent the natural motion of the human face at any pose. Compared with other previous conditions, the proposed facial flow well controls the continuous changes to the face. After that, in order to utilize the facial flow for face editing, we build a synthesis framework generating continuous images with conditional facial flows. To fully take advantage of the motion information of facial flows, a hierarchical conditional framework is designed to combine the extracted multi-scale appearance features from images and motion features from flows in a hierarchical manner. The framework then decodes multiple fused features back to images progressively. Experimental results demonstrate the effectiveness of our method compared to other state-of-the-art methods.
D3T-GAN: Data-Dependent Domain Transfer GANs for Few-shot Image Generation
May 12, 2022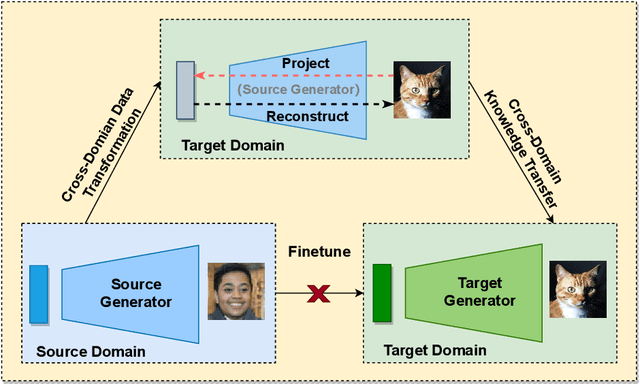
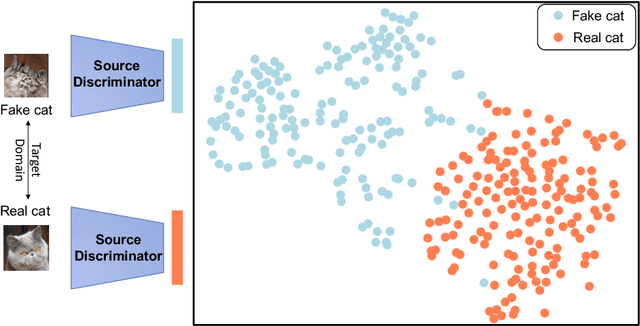
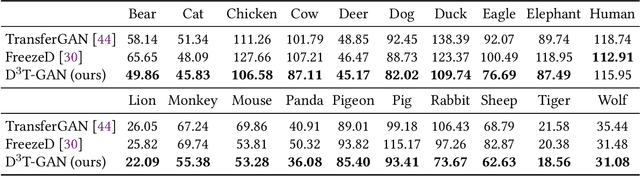
As an important and challenging problem, few-shot image generation aims at generating realistic images through training a GAN model given few samples. A typical solution for few-shot generation is to transfer a well-trained GAN model from a data-rich source domain to the data-deficient target domain. In this paper, we propose a novel self-supervised transfer scheme termed D3T-GAN, addressing the cross-domain GANs transfer in few-shot image generation. Specifically, we design two individual strategies to transfer knowledge between generators and discriminators, respectively. To transfer knowledge between generators, we conduct a data-dependent transformation, which projects and reconstructs the target samples into the source generator space. Then, we perform knowledge transfer from transformed samples to generated samples. To transfer knowledge between discriminators, we design a multi-level discriminant knowledge distillation from the source discriminator to the target discriminator on both the real and fake samples. Extensive experiments show that our method improve the quality of generated images and achieves the state-of-the-art FID scores on commonly used datasets.
Compressing Models with Few Samples: Mimicking then Replacing
Jan 07, 2022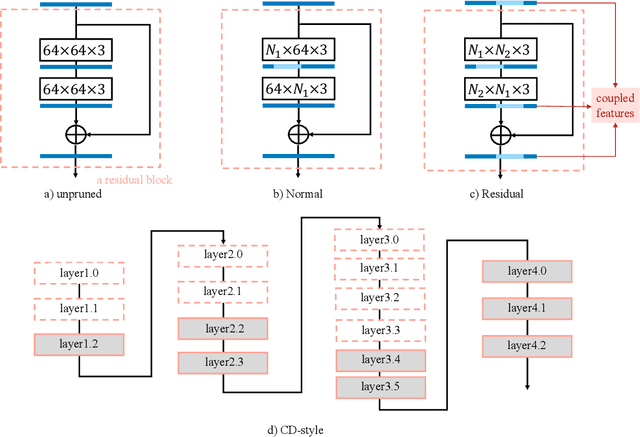

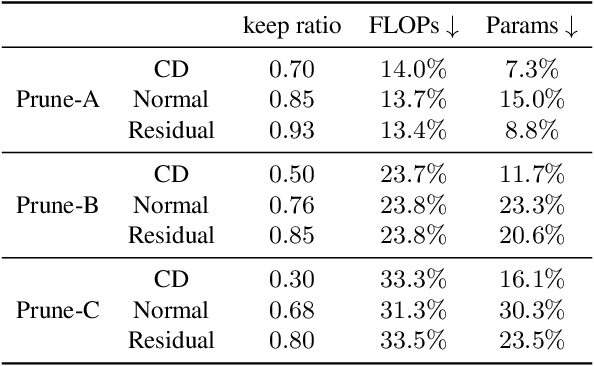
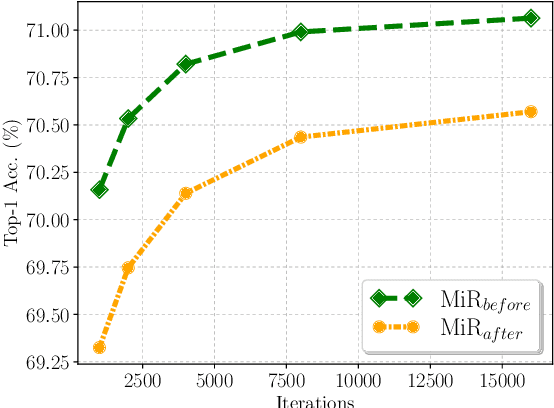
Few-sample compression aims to compress a big redundant model into a small compact one with only few samples. If we fine-tune models with these limited few samples directly, models will be vulnerable to overfit and learn almost nothing. Hence, previous methods optimize the compressed model layer-by-layer and try to make every layer have the same outputs as the corresponding layer in the teacher model, which is cumbersome. In this paper, we propose a new framework named Mimicking then Replacing (MiR) for few-sample compression, which firstly urges the pruned model to output the same features as the teacher's in the penultimate layer, and then replaces teacher's layers before penultimate with a well-tuned compact one. Unlike previous layer-wise reconstruction methods, our MiR optimizes the entire network holistically, which is not only simple and effective, but also unsupervised and general. MiR outperforms previous methods with large margins. Codes will be available soon.
Deep RGB-D Saliency Detection with Depth-Sensitive Attention and Automatic Multi-Modal Fusion
Mar 22, 2021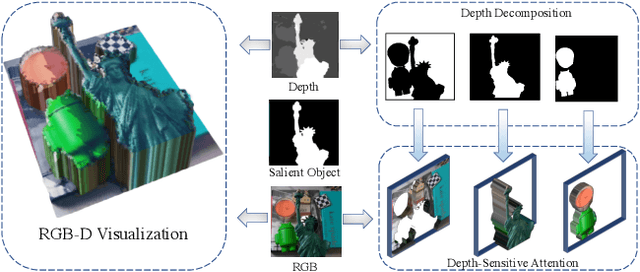
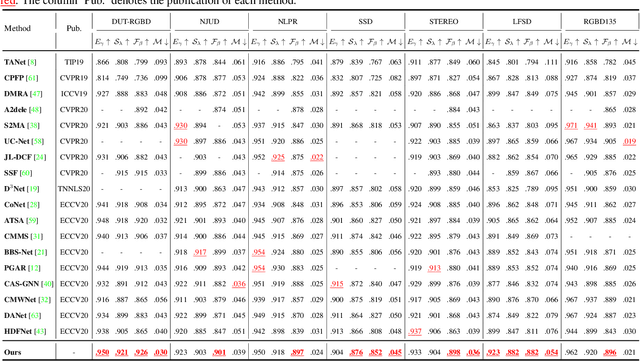
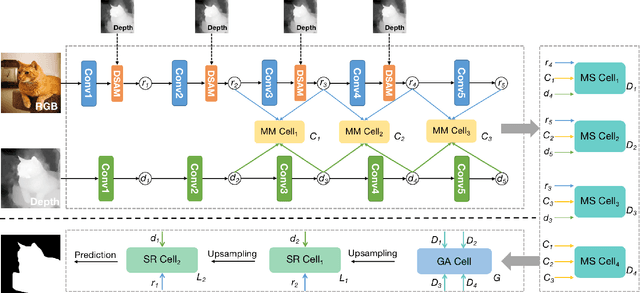
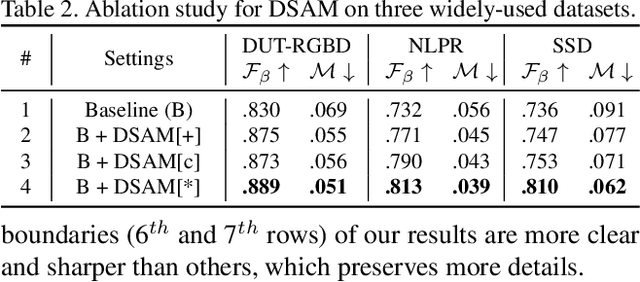
RGB-D salient object detection (SOD) is usually formulated as a problem of classification or regression over two modalities, i.e., RGB and depth. Hence, effective RGBD feature modeling and multi-modal feature fusion both play a vital role in RGB-D SOD. In this paper, we propose a depth-sensitive RGB feature modeling scheme using the depth-wise geometric prior of salient objects. In principle, the feature modeling scheme is carried out in a depth-sensitive attention module, which leads to the RGB feature enhancement as well as the background distraction reduction by capturing the depth geometry prior. Moreover, to perform effective multi-modal feature fusion, we further present an automatic architecture search approach for RGB-D SOD, which does well in finding out a feasible architecture from our specially designed multi-modal multi-scale search space. Extensive experiments on seven standard benchmarks demonstrate the effectiveness of the proposed approach against the state-of-the-art.