 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLASIL: Learner-Aware Supervised Imitation Learning For Long-term Microscopic Traffic Simulation
Apr 08, 2024



Microscopic traffic simulation plays a crucial role in transportation engineering by providing insights into individual vehicle behavior and overall traffic flow. However, creating a realistic simulator that accurately replicates human driving behaviors in various traffic conditions presents significant challenges. Traditional simulators relying on heuristic models often fail to deliver accurate simulations due to the complexity of real-world traffic environments. Due to the covariate shift issue, existing imitation learning-based simulators often fail to generate stable long-term simulations. In this paper, we propose a novel approach called learner-aware supervised imitation learning to address the covariate shift problem in multi-agent imitation learning. By leveraging a variational autoencoder simultaneously modeling the expert and learner state distribution, our approach augments expert states such that the augmented state is aware of learner state distribution. Our method, applied to urban traffic simulation, demonstrates significant improvements over existing state-of-the-art baselines in both short-term microscopic and long-term macroscopic realism when evaluated on the real-world dataset pNEUMA.
LiDAR-NeRF: Novel LiDAR View Synthesis via Neural Radiance Fields
Apr 20, 2023



We introduce a new task, novel view synthesis for LiDAR sensors. While traditional model-based LiDAR simulators with style-transfer neural networks can be applied to render novel views, they fall short in producing accurate and realistic LiDAR patterns, because the renderers they rely on exploit game engines, which are not differentiable. We address this by formulating, to the best of our knowledge, the first differentiable LiDAR renderer, and propose an end-to-end framework, LiDAR-NeRF, leveraging a neural radiance field (NeRF) to enable jointly learning the geometry and the attributes of 3D points. To evaluate the effectiveness of our approach, we establish an object-centric multi-view LiDAR dataset, dubbed NeRF-MVL. It contains observations of objects from 9 categories seen from 360-degree viewpoints captured with multiple LiDAR sensors. Our extensive experiments on the scene-level KITTI-360 dataset, and on our object-level NeRF-MVL show that our LiDAR- NeRF surpasses the model-based algorithms significantly.
PUPS: Point Cloud Unified Panoptic Segmentation
Feb 28, 2023Point cloud panoptic segmentation is a challenging task that seeks a holistic solution for both semantic and instance segmentation to predict groupings of coherent points. Previous approaches treat semantic and instance segmentation as surrogate tasks, and they either use clustering methods or bounding boxes to gather instance groupings with costly computation and hand-crafted designs in the instance segmentation task. In this paper, we propose a simple but effective point cloud unified panoptic segmentation (PUPS) framework, which use a set of point-level classifiers to directly predict semantic and instance groupings in an end-to-end manner. To realize PUPS, we introduce bipartite matching to our training pipeline so that our classifiers are able to exclusively predict groupings of instances, getting rid of hand-crafted designs, e.g. anchors and Non-Maximum Suppression (NMS). In order to achieve better grouping results, we utilize a transformer decoder to iteratively refine the point classifiers and develop a context-aware CutMix augmentation to overcome the class imbalance problem. As a result, PUPS achieves 1st place on the leader board of SemanticKITTI panoptic segmentation task and state-of-the-art results on nuScenes.
Benchmarking the Robustness of LiDAR-Camera Fusion for 3D Object Detection
May 30, 2022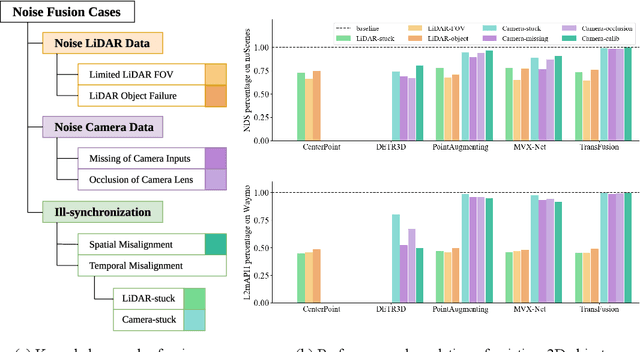
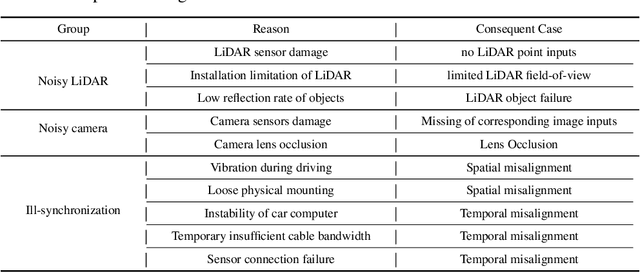
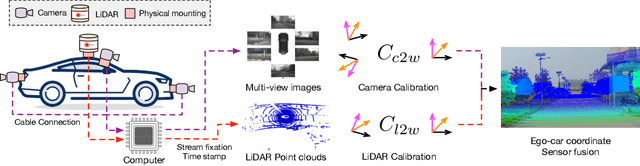
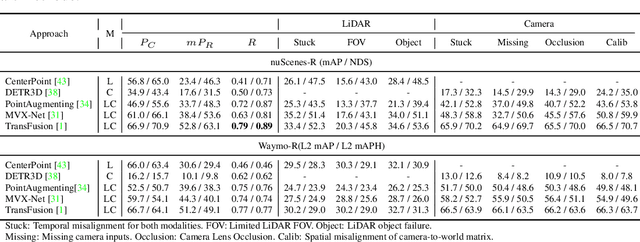
There are two critical sensors for 3D perception in autonomous driving, the camera and the LiDAR. The camera provides rich semantic information such as color, texture, and the LiDAR reflects the 3D shape and locations of surrounding objects. People discover that fusing these two modalities can significantly boost the performance of 3D perception models as each modality has complementary information to the other. However, we observe that current datasets are captured from expensive vehicles that are explicitly designed for data collection purposes, and cannot truly reflect the realistic data distribution due to various reasons. To this end, we collect a series of real-world cases with noisy data distribution, and systematically formulate a robustness benchmark toolkit, that simulates these cases on any clean autonomous driving datasets. We showcase the effectiveness of our toolkit by establishing the robustness benchmark on two widely-adopted autonomous driving datasets, nuScenes and Waymo, then, to the best of our knowledge, holistically benchmark the state-of-the-art fusion methods for the first time. We observe that: i) most fusion methods, when solely developed on these data, tend to fail inevitably when there is a disruption to the LiDAR input; ii) the improvement of the camera input is significantly inferior to the LiDAR one. We further propose an efficient robust training strategy to improve the robustness of the current fusion method. The benchmark and code are available at https://github.com/kcyu2014/lidar-camera-robust-benchmark