 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowVal: A Knowledge-Augmented and Value-Guided Autonomous Driving System
Dec 23, 2025Visual-language reasoning, driving knowledge, and value alignment are essential for advanced autonomous driving systems. However, existing approaches largely rely on data-driven learning, making it difficult to capture the complex logic underlying decision-making through imitation or limited reinforcement rewards. To address this, we propose KnowVal, a new autonomous driving system that enables visual-language reasoning through the synergistic integration of open-world perception and knowledge retrieval. Specifically, we construct a comprehensive driving knowledge graph that encodes traffic laws, defensive driving principles, and ethical norms, complemented by an efficient LLM-based retrieval mechanism tailored for driving scenarios. Furthermore, we develop a human-preference dataset and train a Value Model to guide interpretable, value-aligned trajectory assessment. Experimental results show that our method substantially improves planning performance while remaining compatible with existing architectures. Notably, KnowVal achieves the lowest collision rate on nuScenes and state-of-the-art results on Bench2Drive.
HENet++: Hybrid Encoding and Multi-task Learning for 3D Perception and End-to-end Autonomous Driving
Nov 10, 2025Three-dimensional feature extraction is a critical component of autonomous driving systems, where perception tasks such as 3D object detection, bird's-eye-view (BEV) semantic segmentation, and occupancy prediction serve as important constraints on 3D features. While large image encoders, high-resolution images, and long-term temporal inputs can significantly enhance feature quality and deliver remarkable performance gains, these techniques are often incompatible in both training and inference due to computational resource constraints. Moreover, different tasks favor distinct feature representations, making it difficult for a single model to perform end-to-end inference across multiple tasks while maintaining accuracy comparable to that of single-task models. To alleviate these issues, we present the HENet and HENet++ framework for multi-task 3D perception and end-to-end autonomous driving. Specifically, we propose a hybrid image encoding network that uses a large image encoder for short-term frames and a small one for long-term frames. Furthermore, our framework simultaneously extracts both dense and sparse features, providing more suitable representations for different tasks, reducing cumulative errors, and delivering more comprehensive information to the planning module. The proposed architecture maintains compatibility with various existing 3D feature extraction methods and supports multimodal inputs. HENet++ achieves state-of-the-art end-to-end multi-task 3D perception results on the nuScenes benchmark, while also attaining the lowest collision rate on the nuScenes end-to-end autonomous driving benchmark.
InsFusion: Rethink Instance-level LiDAR-Camera Fusion for 3D Object Detection
Sep 10, 2025Three-dimensional Object Detection from multi-view cameras and LiDAR is a crucial component for autonomous driving and smart transportation. However, in the process of basic feature extraction, perspective transformation, and feature fusion, noise and error will gradually accumulate. To address this issue, we propose InsFusion, which can extract proposals from both raw and fused features and utilizes these proposals to query the raw features, thereby mitigating the impact of accumulated errors. Additionally, by incorporating attention mechanisms applied to the raw features, it thereby mitigates the impact of accumulated errors. Experiments on the nuScenes dataset demonstrate that InsFusion is compatible with various advanced baseline methods and delivers new state-of-the-art performance for 3D object detection.
OpenAD: Open-World Autonomous Driving Benchmark for 3D Object Detection
Nov 26, 2024



Open-world autonomous driving encompasses domain generalization and open-vocabulary. Domain generalization refers to the capabilities of autonomous driving systems across different scenarios and sensor parameter configurations. Open vocabulary pertains to the ability to recognize various semantic categories not encountered during training. In this paper, we introduce OpenAD, the first real-world open-world autonomous driving benchmark for 3D object detection. OpenAD is built on a corner case discovery and annotation pipeline integrating with a multimodal large language model (MLLM). The proposed pipeline annotates corner case objects in a unified format for five autonomous driving perception datasets with 2000 scenarios. In addition, we devise evaluation methodologies and evaluate various 2D and 3D open-world and specialized models. Moreover, we propose a vision-centric 3D open-world object detection baseline and further introduce an ensemble method by fusing general and specialized models to address the issue of lower precision in existing open-world methods for the OpenAD benchmark. Annotations, toolkit code, and all evaluation codes will be released.
HENet: Hybrid Encoding for End-to-end Multi-task 3D Perception from Multi-view Cameras
Apr 03, 2024



Three-dimensional perception from multi-view cameras is a crucial component in autonomous driving systems, which involves multiple tasks like 3D object detection and bird's-eye-view (BEV) semantic segmentation. To improve perception precision, large image encoders, high-resolution images, and long-term temporal inputs have been adopted in recent 3D perception models, bringing remarkable performance gains. However, these techniques are often incompatible in training and inference scenarios due to computational resource constraints. Besides, modern autonomous driving systems prefer to adopt an end-to-end framework for multi-task 3D perception, which can simplify the overall system architecture and reduce the implementation complexity. However, conflict between tasks often arises when optimizing multiple tasks jointly within an end-to-end 3D perception model. To alleviate these issues, we present an end-to-end framework named HENet for multi-task 3D perception in this paper. Specifically, we propose a hybrid image encoding network, using a large image encoder for short-term frames and a small image encoder for long-term temporal frames. Then, we introduce a temporal feature integration module based on the attention mechanism to fuse the features of different frames extracted by the two aforementioned hybrid image encoders. Finally, according to the characteristics of each perception task, we utilize BEV features of different grid sizes, independent BEV encoders, and task decoders for different tasks. Experimental results show that HENet achieves state-of-the-art end-to-end multi-task 3D perception results on the nuScenes benchmark, including 3D object detection and BEV semantic segmentation. The source code and models will be released at https://github.com/VDIGPKU/HENet.
RCBEVDet: Radar-camera Fusion in Bird's Eye View for 3D Object Detection
Mar 25, 2024



Three-dimensional object detection is one of the key tasks in autonomous driving. To reduce costs in practice, low-cost multi-view cameras for 3D object detection are proposed to replace the expansive LiDAR sensors. However, relying solely on cameras is difficult to achieve highly accurate and robust 3D object detection. An effective solution to this issue is combining multi-view cameras with the economical millimeter-wave radar sensor to achieve more reliable multi-modal 3D object detection. In this paper, we introduce RCBEVDet, a radar-camera fusion 3D object detection method in the bird's eye view (BEV). Specifically, we first design RadarBEVNet for radar BEV feature extraction. RadarBEVNet consists of a dual-stream radar backbone and a Radar Cross-Section (RCS) aware BEV encoder. In the dual-stream radar backbone, a point-based encoder and a transformer-based encoder are proposed to extract radar features, with an injection and extraction module to facilitate communication between the two encoders. The RCS-aware BEV encoder takes RCS as the object size prior to scattering the point feature in BEV. Besides, we present the Cross-Attention Multi-layer Fusion module to automatically align the multi-modal BEV feature from radar and camera with the deformable attention mechanism, and then fuse the feature with channel and spatial fusion layers. Experimental results show that RCBEVDet achieves new state-of-the-art radar-camera fusion results on nuScenes and view-of-delft (VoD) 3D object detection benchmarks. Furthermore, RCBEVDet achieves better 3D detection results than all real-time camera-only and radar-camera 3D object detectors with a faster inference speed at 21~28 FPS. The source code will be released at https://github.com/VDIGPKU/RCBEVDet.
Benchmarking the Robustness of LiDAR-Camera Fusion for 3D Object Detection
May 30, 2022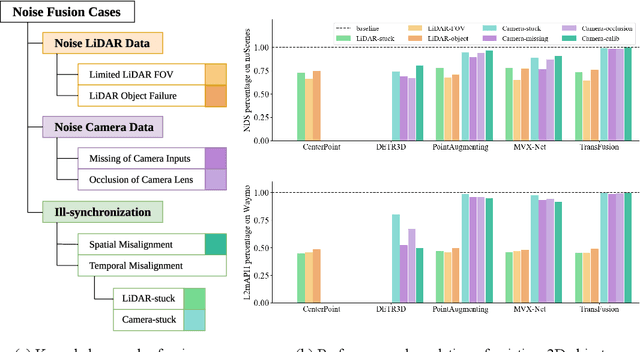
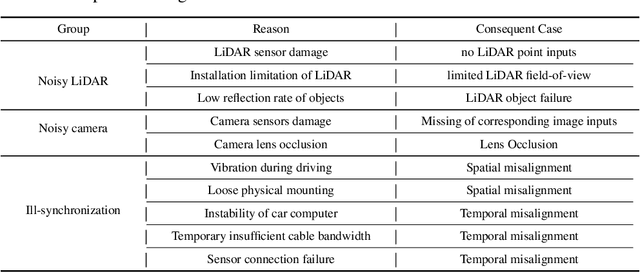
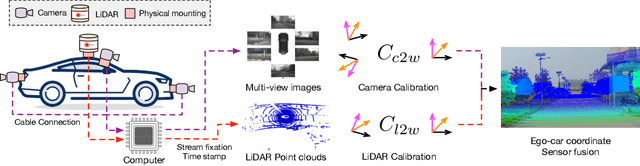
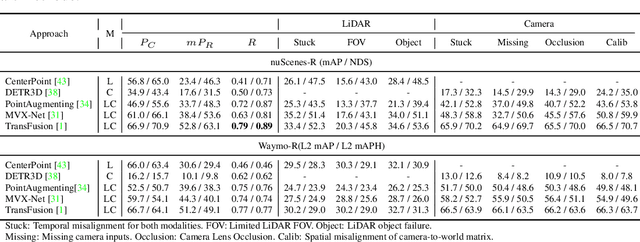
There are two critical sensors for 3D perception in autonomous driving, the camera and the LiDAR. The camera provides rich semantic information such as color, texture, and the LiDAR reflects the 3D shape and locations of surrounding objects. People discover that fusing these two modalities can significantly boost the performance of 3D perception models as each modality has complementary information to the other. However, we observe that current datasets are captured from expensive vehicles that are explicitly designed for data collection purposes, and cannot truly reflect the realistic data distribution due to various reasons. To this end, we collect a series of real-world cases with noisy data distribution, and systematically formulate a robustness benchmark toolkit, that simulates these cases on any clean autonomous driving datasets. We showcase the effectiveness of our toolkit by establishing the robustness benchmark on two widely-adopted autonomous driving datasets, nuScenes and Waymo, then, to the best of our knowledge, holistically benchmark the state-of-the-art fusion methods for the first time. We observe that: i) most fusion methods, when solely developed on these data, tend to fail inevitably when there is a disruption to the LiDAR input; ii) the improvement of the camera input is significantly inferior to the LiDAR one. We further propose an efficient robust training strategy to improve the robustness of the current fusion method. The benchmark and code are available at https://github.com/kcyu2014/lidar-camera-robust-benchmark
BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework
May 27, 2022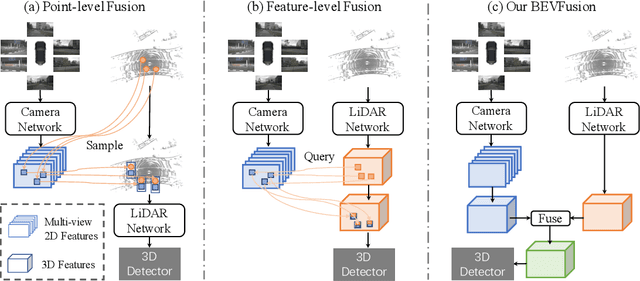

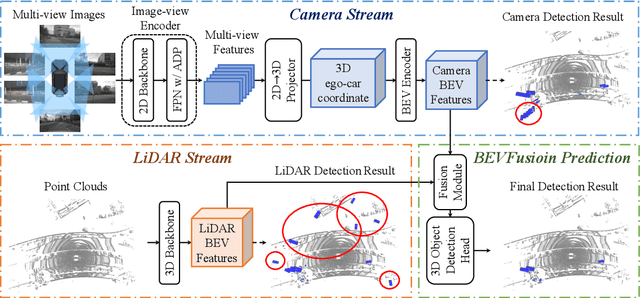
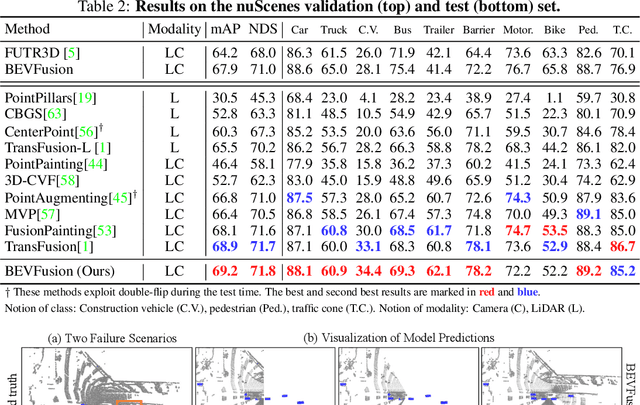
Fusing the camera and LiDAR information has become a de-facto standard for 3D object detection tasks. Current methods rely on point clouds from the LiDAR sensor as queries to leverage the feature from the image space. However, people discover that this underlying assumption makes the current fusion framework infeasible to produce any prediction when there is a LiDAR malfunction, regardless of minor or major. This fundamentally limits the deployment capability to realistic autonomous driving scenarios. In contrast, we propose a surprisingly simple yet novel fusion framework, dubbed BEVFusion, whose camera stream does not depend on the input of LiDAR data, thus addressing the downside of previous methods. We empirically show that our framework surpasses the state-of-the-art methods under the normal training settings. Under the robustness training settings that simulate various LiDAR malfunctions, our framework significantly surpasses the state-of-the-art methods by 15.7% to 28.9% mAP. To the best of our knowledge, we are the first to handle realistic LiDAR malfunction and can be deployed to realistic scenarios without any post-processing procedure. The code is available at https://github.com/ADLab-AutoDrive/BEVFusion.