 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniDriveVLA: Unifying Understanding, Perception, and Action Planning for Autonomous Driving
Apr 02, 2026Vision-Language-Action (VLA) models have recently emerged in autonomous driving, with the promise of leveraging rich world knowledge to improve the cognitive capabilities of driving systems. However, adapting such models for driving tasks currently faces a critical dilemma between spatial perception and semantic reasoning. Consequently, existing VLA systems are forced into suboptimal compromises: directly adopting 2D Vision-Language Models yields limited spatial perception, whereas enhancing them with 3D spatial representations often impairs the native reasoning capacity of VLMs. We argue that this dilemma largely stems from the coupled optimization of spatial perception and semantic reasoning within shared model parameters. To overcome this, we propose UniDriveVLA, a Unified Driving Vision-Language-Action model based on Mixture-of-Transformers that addresses the perception-reasoning conflict via expert decoupling. Specifically, it comprises three experts for driving understanding, scene perception, and action planning, which are coordinated through masked joint attention. In addition, we combine a sparse perception paradigm with a three-stage progressive training strategy to improve spatial perception while maintaining semantic reasoning capability. Extensive experiments show that UniDriveVLA achieves state-of-the-art performance in open-loop evaluation on nuScenes and closed-loop evaluation on Bench2Drive. Moreover, it demonstrates strong performance across a broad range of perception, prediction, and understanding tasks, including 3D detection, online mapping, motion forecasting, and driving-oriented VQA, highlighting its broad applicability as a unified model for autonomous driving. Code and model have been released at https://github.com/xiaomi-research/unidrivevla
MindDrive: A Vision-Language-Action Model for Autonomous Driving via Online Reinforcement Learning
Dec 16, 2025


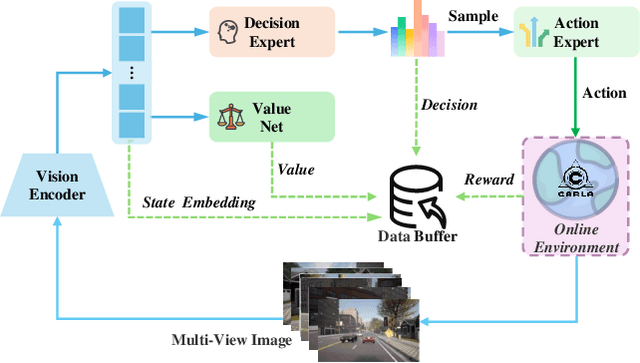
Current Vision-Language-Action (VLA) paradigms in autonomous driving primarily rely on Imitation Learning (IL), which introduces inherent challenges such as distribution shift and causal confusion. Online Reinforcement Learning offers a promising pathway to address these issues through trial-and-error learning. However, applying online reinforcement learning to VLA models in autonomous driving is hindered by inefficient exploration in continuous action spaces. To overcome this limitation, we propose MindDrive, a VLA framework comprising a large language model (LLM) with two distinct sets of LoRA parameters. The one LLM serves as a Decision Expert for scenario reasoning and driving decision-making, while the other acts as an Action Expert that dynamically maps linguistic decisions into feasible trajectories. By feeding trajectory-level rewards back into the reasoning space, MindDrive enables trial-and-error learning over a finite set of discrete linguistic driving decisions, instead of operating directly in a continuous action space. This approach effectively balances optimal decision-making in complex scenarios, human-like driving behavior, and efficient exploration in online reinforcement learning. Using the lightweight Qwen-0.5B LLM, MindDrive achieves Driving Score (DS) of 78.04 and Success Rate (SR) of 55.09% on the challenging Bench2Drive benchmark. To the best of our knowledge, this is the first work to demonstrate the effectiveness of online reinforcement learning for the VLA model in autonomous driving.
Extending Large Vision-Language Model for Diverse Interactive Tasks in Autonomous Driving
May 13, 2025



The Large Visual-Language Models (LVLMs) have significantly advanced image understanding. Their comprehension and reasoning capabilities enable promising applications in autonomous driving scenarios. However, existing research typically focuses on front-view perspectives and partial objects within scenes, struggling to achieve comprehensive scene understanding. Meanwhile, existing LVLMs suffer from the lack of mapping relationship between 2D and 3D and insufficient integration of 3D object localization and instruction understanding. To tackle these limitations, we first introduce NuInteract, a large-scale dataset with over 1.5M multi-view image language pairs spanning dense scene captions and diverse interactive tasks. Furthermore, we propose DriveMonkey, a simple yet effective framework that seamlessly integrates LVLMs with a spatial processor using a series of learnable queries. The spatial processor, designed as a plug-and-play component, can be initialized with pre-trained 3D detectors to improve 3D perception. Our experiments show that DriveMonkey outperforms general LVLMs, especially achieving a 9.86% notable improvement on the 3D visual grounding task. The dataset and code will be released at https://github.com/zc-zhao/DriveMonkey.
ORION: A Holistic End-to-End Autonomous Driving Framework by Vision-Language Instructed Action Generation
Mar 25, 2025End-to-end (E2E) autonomous driving methods still struggle to make correct decisions in interactive closed-loop evaluation due to limited causal reasoning capability. Current methods attempt to leverage the powerful understanding and reasoning abilities of Vision-Language Models (VLMs) to resolve this dilemma. However, the problem is still open that few VLMs for E2E methods perform well in the closed-loop evaluation due to the gap between the semantic reasoning space and the purely numerical trajectory output in the action space. To tackle this issue, we propose ORION, a holistic E2E autonomous driving framework by vision-language instructed action generation. ORION uniquely combines a QT-Former to aggregate long-term history context, a Large Language Model (LLM) for driving scenario reasoning, and a generative planner for precision trajectory prediction. ORION further aligns the reasoning space and the action space to implement a unified E2E optimization for both visual question-answering (VQA) and planning tasks. Our method achieves an impressive closed-loop performance of 77.74 Driving Score (DS) and 54.62% Success Rate (SR) on the challenge Bench2Drive datasets, which outperforms state-of-the-art (SOTA) methods by a large margin of 14.28 DS and 19.61% SR.
MiLA: Multi-view Intensive-fidelity Long-term Video Generation World Model for Autonomous Driving
Mar 20, 2025In recent years, data-driven techniques have greatly advanced autonomous driving systems, but the need for rare and diverse training data remains a challenge, requiring significant investment in equipment and labor. World models, which predict and generate future environmental states, offer a promising solution by synthesizing annotated video data for training. However, existing methods struggle to generate long, consistent videos without accumulating errors, especially in dynamic scenes. To address this, we propose MiLA, a novel framework for generating high-fidelity, long-duration videos up to one minute. MiLA utilizes a Coarse-to-Re(fine) approach to both stabilize video generation and correct distortion of dynamic objects. Additionally, we introduce a Temporal Progressive Denoising Scheduler and Joint Denoising and Correcting Flow modules to improve the quality of generated videos. Extensive experiments on the nuScenes dataset show that MiLA achieves state-of-the-art performance in video generation quality. For more information, visit the project website: https://github.com/xiaomi-mlab/mila.github.io.
Learning A Zero-shot Occupancy Network from Vision Foundation Models via Self-supervised Adaptation
Mar 10, 2025

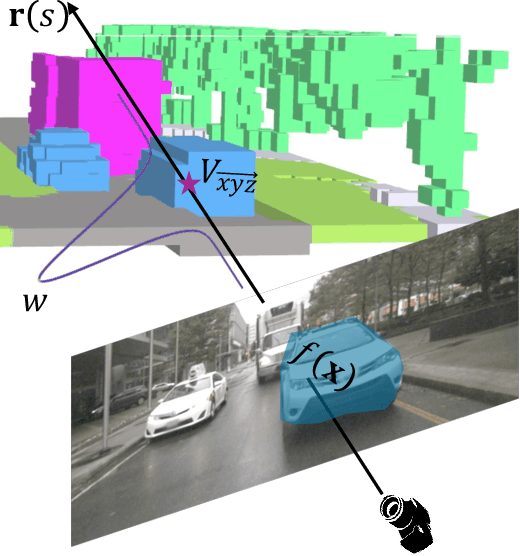

Estimating the 3D world from 2D monocular images is a fundamental yet challenging task due to the labour-intensive nature of 3D annotations. To simplify label acquisition, this work proposes a novel approach that bridges 2D vision foundation models (VFMs) with 3D tasks by decoupling 3D supervision into an ensemble of image-level primitives, e.g., semantic and geometric components. As a key motivator, we leverage the zero-shot capabilities of vision-language models for image semantics. However, due to the notorious ill-posed problem - multiple distinct 3D scenes can produce identical 2D projections, directly inferring metric depth from a monocular image in a zero-shot manner is unsuitable. In contrast, 2D VFMs provide promising sources of relative depth, which theoretically aligns with metric depth when properly scaled and offset. Thus, we adapt the relative depth derived from VFMs into metric depth by optimising the scale and offset using temporal consistency, also known as novel view synthesis, without access to ground-truth metric depth. Consequently, we project the semantics into 3D space using the reconstructed metric depth, thereby providing 3D supervision. Extensive experiments on nuScenes and SemanticKITTI demonstrate the effectiveness of our framework. For instance, the proposed method surpasses the current state-of-the-art by 3.34% mIoU on nuScenes for voxel occupancy prediction.
SurroundSDF: Implicit 3D Scene Understanding Based on Signed Distance Field
Mar 21, 2024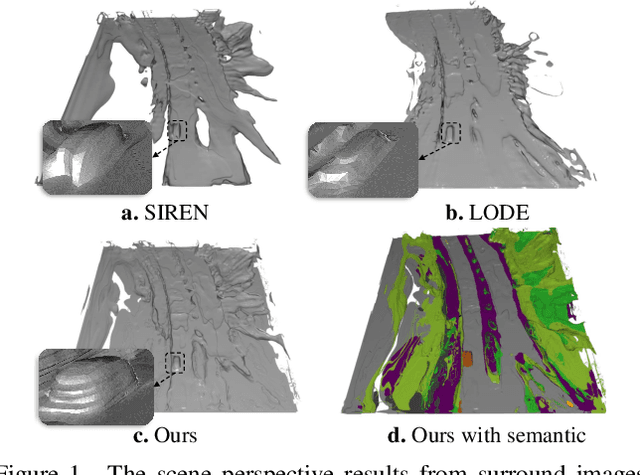



Vision-centric 3D environment understanding is both vital and challenging for autonomous driving systems. Recently, object-free methods have attracted considerable attention. Such methods perceive the world by predicting the semantics of discrete voxel grids but fail to construct continuous and accurate obstacle surfaces. To this end, in this paper, we propose SurroundSDF to implicitly predict the signed distance field (SDF) and semantic field for the continuous perception from surround images. Specifically, we introduce a query-based approach and utilize SDF constrained by the Eikonal formulation to accurately describe the surfaces of obstacles. Furthermore, considering the absence of precise SDF ground truth, we propose a novel weakly supervised paradigm for SDF, referred to as the Sandwich Eikonal formulation, which emphasizes applying correct and dense constraints on both sides of the surface, thereby enhancing the perceptual accuracy of the surface. Experiments suggest that our method achieves SOTA for both occupancy prediction and 3D scene reconstruction tasks on the nuScenes dataset.
Benchmarking the Robustness of LiDAR-Camera Fusion for 3D Object Detection
May 30, 2022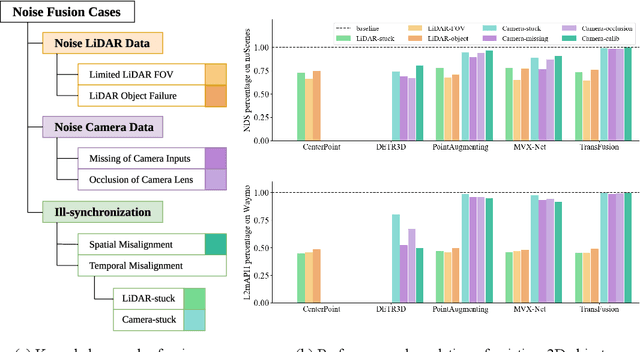
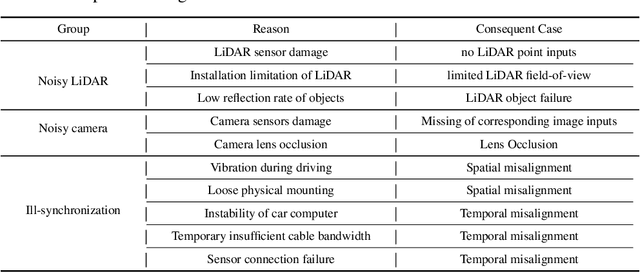
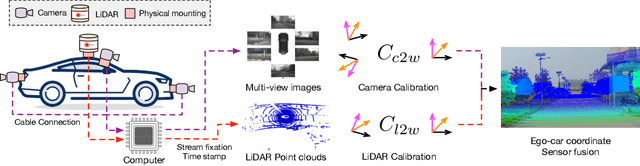
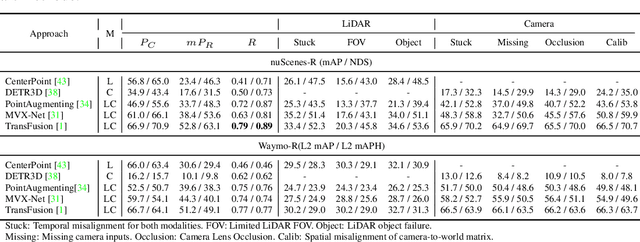
There are two critical sensors for 3D perception in autonomous driving, the camera and the LiDAR. The camera provides rich semantic information such as color, texture, and the LiDAR reflects the 3D shape and locations of surrounding objects. People discover that fusing these two modalities can significantly boost the performance of 3D perception models as each modality has complementary information to the other. However, we observe that current datasets are captured from expensive vehicles that are explicitly designed for data collection purposes, and cannot truly reflect the realistic data distribution due to various reasons. To this end, we collect a series of real-world cases with noisy data distribution, and systematically formulate a robustness benchmark toolkit, that simulates these cases on any clean autonomous driving datasets. We showcase the effectiveness of our toolkit by establishing the robustness benchmark on two widely-adopted autonomous driving datasets, nuScenes and Waymo, then, to the best of our knowledge, holistically benchmark the state-of-the-art fusion methods for the first time. We observe that: i) most fusion methods, when solely developed on these data, tend to fail inevitably when there is a disruption to the LiDAR input; ii) the improvement of the camera input is significantly inferior to the LiDAR one. We further propose an efficient robust training strategy to improve the robustness of the current fusion method. The benchmark and code are available at https://github.com/kcyu2014/lidar-camera-robust-benchmark
BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework
May 27, 2022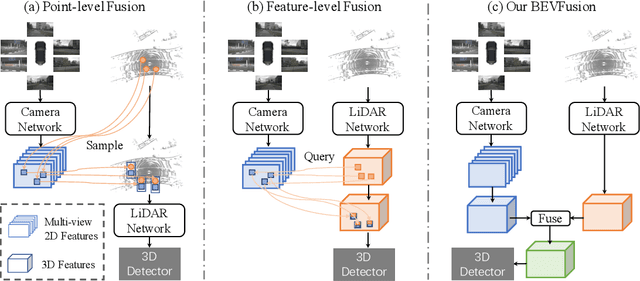

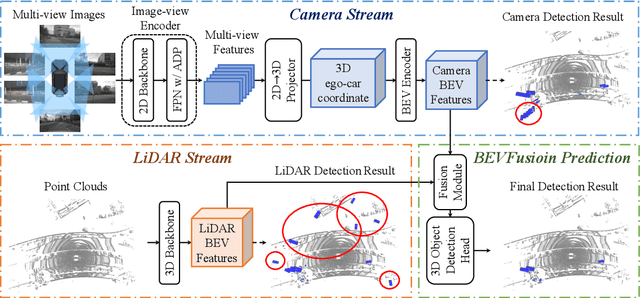
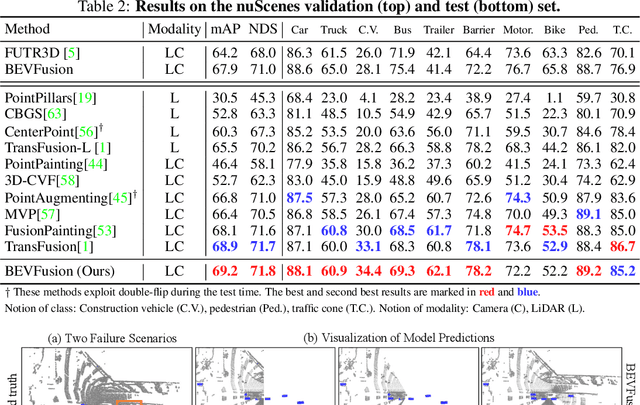
Fusing the camera and LiDAR information has become a de-facto standard for 3D object detection tasks. Current methods rely on point clouds from the LiDAR sensor as queries to leverage the feature from the image space. However, people discover that this underlying assumption makes the current fusion framework infeasible to produce any prediction when there is a LiDAR malfunction, regardless of minor or major. This fundamentally limits the deployment capability to realistic autonomous driving scenarios. In contrast, we propose a surprisingly simple yet novel fusion framework, dubbed BEVFusion, whose camera stream does not depend on the input of LiDAR data, thus addressing the downside of previous methods. We empirically show that our framework surpasses the state-of-the-art methods under the normal training settings. Under the robustness training settings that simulate various LiDAR malfunctions, our framework significantly surpasses the state-of-the-art methods by 15.7% to 28.9% mAP. To the best of our knowledge, we are the first to handle realistic LiDAR malfunction and can be deployed to realistic scenarios without any post-processing procedure. The code is available at https://github.com/ADLab-AutoDrive/BEVFusion.
Knowledge Distillation via the Target-aware Transformer
May 22, 2022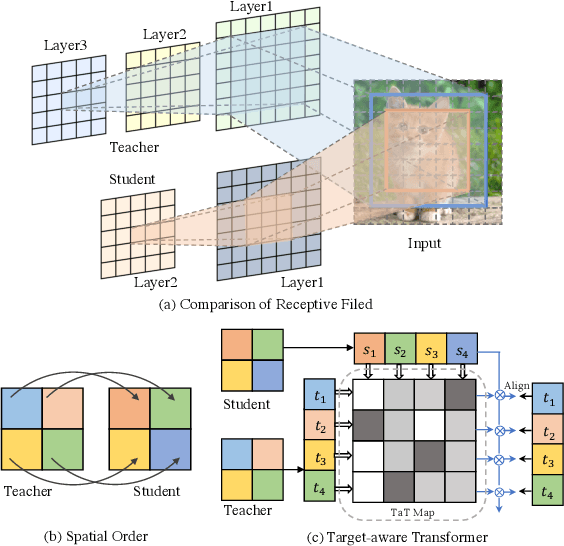
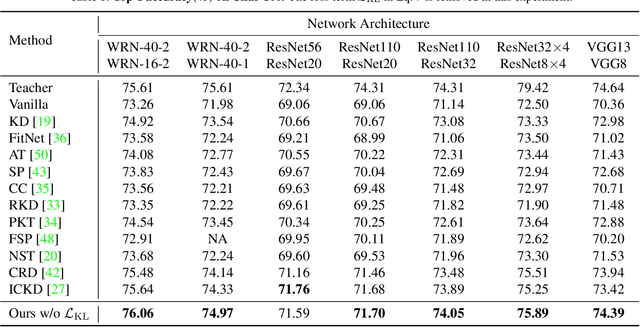
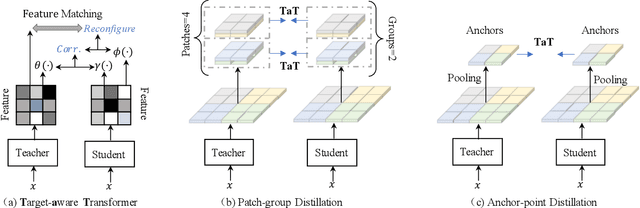

Knowledge distillation becomes a de facto standard to improve the performance of small neural networks. Most of the previous works propose to regress the representational features from the teacher to the student in a one-to-one spatial matching fashion. However, people tend to overlook the fact that, due to the architecture differences, the semantic information on the same spatial location usually vary. This greatly undermines the underlying assumption of the one-to-one distillation approach. To this end, we propose a novel one-to-all spatial matching knowledge distillation approach. Specifically, we allow each pixel of the teacher feature to be distilled to all spatial locations of the student features given its similarity, which is generated from a target-aware transformer. Our approach surpasses the state-of-the-art methods by a significant margin on various computer vision benchmarks, such as ImageNet, Pascal VOC and COCOStuff10k. Code will be released soon.