 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELITE: Experiential Learning and Intent-Aware Transfer for Self-improving Embodied Agents
Mar 25, 2026Vision-language models (VLMs) have shown remarkable general capabilities, yet embodied agents built on them fail at complex tasks, often skipping critical steps, proposing invalid actions, and repeating mistakes. These failures arise from a fundamental gap between the static training data of VLMs and the physical interaction for embodied tasks. VLMs can learn rich semantic knowledge from static data but lack the ability to interact with the world. To address this issue, we introduce ELITE, an embodied agent framework with {E}xperiential {L}earning and {I}ntent-aware {T}ransfer that enables agents to continuously learn from their own environment interaction experiences, and transfer acquired knowledge to procedurally similar tasks. ELITE operates through two synergistic mechanisms, \textit{i.e.,} self-reflective knowledge construction and intent-aware retrieval. Specifically, self-reflective knowledge construction extracts reusable strategies from execution trajectories and maintains an evolving strategy pool through structured refinement operations. Then, intent-aware retrieval identifies relevant strategies from the pool and applies them to current tasks. Experiments on the EB-ALFRED and EB-Habitat benchmarks show that ELITE achieves 9\% and 5\% performance improvement over base VLMs in the online setting without any supervision. In the supervised setting, ELITE generalizes effectively to unseen task categories, achieving better performance compared to state-of-the-art training-based methods. These results demonstrate the effectiveness of ELITE for bridging the gap between semantic understanding and reliable action execution.
MeGU: Machine-Guided Unlearning with Target Feature Disentanglement
Feb 19, 2026The growing concern over training data privacy has elevated the "Right to be Forgotten" into a critical requirement, thereby raising the demand for effective Machine Unlearning. However, existing unlearning approaches commonly suffer from a fundamental trade-off: aggressively erasing the influence of target data often degrades model utility on retained data, while conservative strategies leave residual target information intact. In this work, the intrinsic representation properties learned during model pretraining are analyzed. It is demonstrated that semantic class concepts are entangled at the feature-pattern level, sharing associated features while preserving concept-specific discriminative components. This entanglement fundamentally limits the effectiveness of existing unlearning paradigms. Motivated by this insight, we propose Machine-Guided Unlearning (MeGU), a novel framework that guides unlearning through concept-aware re-alignment. Specifically, Multi-modal Large Language Models (MLLMs) are leveraged to explicitly determine re-alignment directions for target samples by assigning semantically meaningful perturbing labels. To improve efficiency, inter-class conceptual similarities estimated by the MLLM are encoded into a lightweight transition matrix. Furthermore, MeGU introduces a positive-negative feature noise pair to explicitly disentangle target concept influence. During finetuning, the negative noise suppresses target-specific feature patterns, while the positive noise reinforces remaining associated features and aligns them with perturbing concepts. This coordinated design enables selective disruption of target-specific representations while preserving shared semantic structures. As a result, MeGU enables controlled and selective forgetting, effectively mitigating both under-unlearning and over-unlearning.
HENet++: Hybrid Encoding and Multi-task Learning for 3D Perception and End-to-end Autonomous Driving
Nov 10, 2025Three-dimensional feature extraction is a critical component of autonomous driving systems, where perception tasks such as 3D object detection, bird's-eye-view (BEV) semantic segmentation, and occupancy prediction serve as important constraints on 3D features. While large image encoders, high-resolution images, and long-term temporal inputs can significantly enhance feature quality and deliver remarkable performance gains, these techniques are often incompatible in both training and inference due to computational resource constraints. Moreover, different tasks favor distinct feature representations, making it difficult for a single model to perform end-to-end inference across multiple tasks while maintaining accuracy comparable to that of single-task models. To alleviate these issues, we present the HENet and HENet++ framework for multi-task 3D perception and end-to-end autonomous driving. Specifically, we propose a hybrid image encoding network that uses a large image encoder for short-term frames and a small one for long-term frames. Furthermore, our framework simultaneously extracts both dense and sparse features, providing more suitable representations for different tasks, reducing cumulative errors, and delivering more comprehensive information to the planning module. The proposed architecture maintains compatibility with various existing 3D feature extraction methods and supports multimodal inputs. HENet++ achieves state-of-the-art end-to-end multi-task 3D perception results on the nuScenes benchmark, while also attaining the lowest collision rate on the nuScenes end-to-end autonomous driving benchmark.
VoxRole: A Comprehensive Benchmark for Evaluating Speech-Based Role-Playing Agents
Sep 04, 2025Recent significant advancements in Large Language Models (LLMs) have greatly propelled the development of Role-Playing Conversational Agents (RPCAs). These systems aim to create immersive user experiences through consistent persona adoption. However, current RPCA research faces dual limitations. First, existing work predominantly focuses on the textual modality, entirely overlooking critical paralinguistic features including intonation, prosody, and rhythm in speech, which are essential for conveying character emotions and shaping vivid identities. Second, the speech-based role-playing domain suffers from a long-standing lack of standardized evaluation benchmarks. Most current spoken dialogue datasets target only fundamental capability assessments, featuring thinly sketched or ill-defined character profiles. Consequently, they fail to effectively quantify model performance on core competencies like long-term persona consistency. To address this critical gap, we introduce VoxRole, the first comprehensive benchmark specifically designed for the evaluation of speech-based RPCAs. The benchmark comprises 13335 multi-turn dialogues, totaling 65.6 hours of speech from 1228 unique characters across 261 movies. To construct this resource, we propose a novel two-stage automated pipeline that first aligns movie audio with scripts and subsequently employs an LLM to systematically build multi-dimensional profiles for each character. Leveraging VoxRole, we conduct a multi-dimensional evaluation of contemporary spoken dialogue models, revealing crucial insights into their respective strengths and limitations in maintaining persona consistency.
RegCL: Continual Adaptation of Segment Anything Model via Model Merging
Jul 16, 2025
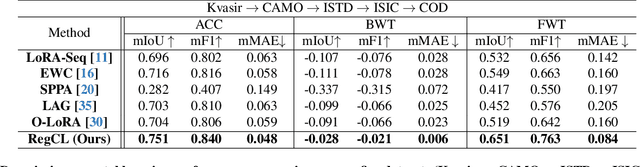
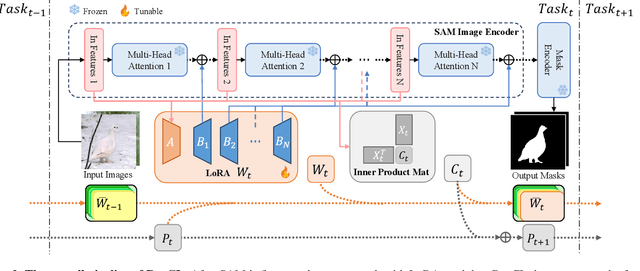
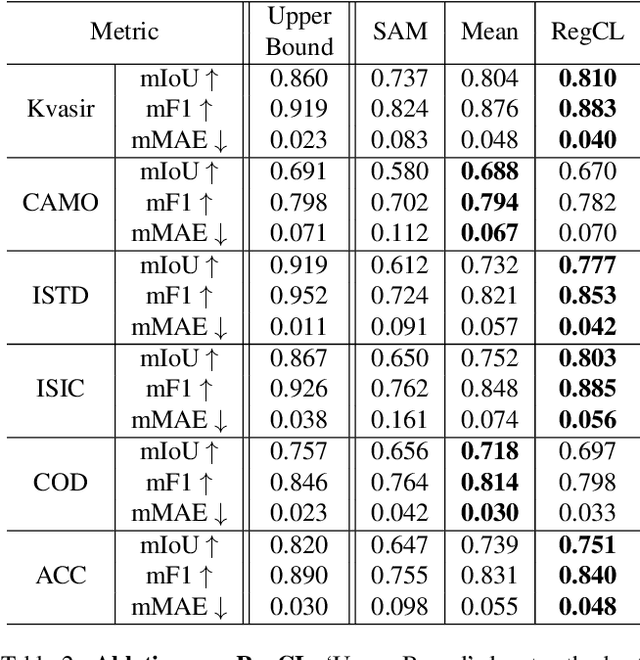
To address the performance limitations of the Segment Anything Model (SAM) in specific domains, existing works primarily adopt adapter-based one-step adaptation paradigms. However, some of these methods are specific developed for specific domains. If used on other domains may lead to performance degradation. This issue of catastrophic forgetting severely limits the model's scalability. To address this issue, this paper proposes RegCL, a novel non-replay continual learning (CL) framework designed for efficient multi-domain knowledge integration through model merging. Specifically, RegCL incorporates the model merging algorithm into the continual learning paradigm by merging the parameters of SAM's adaptation modules (e.g., LoRA modules) trained on different domains. The merging process is guided by weight optimization, which minimizes prediction discrepancies between the merged model and each of the domain-specific models. RegCL effectively consolidates multi-domain knowledge while maintaining parameter efficiency, i.e., the model size remains constant regardless of the number of tasks, and no historical data storage is required. Experimental results demonstrate that RegCL achieves favorable continual learning performance across multiple downstream datasets, validating its effectiveness in dynamic scenarios.
LeVo: High-Quality Song Generation with Multi-Preference Alignment
Jun 09, 2025



Recent advances in large language models (LLMs) and audio language models have significantly improved music generation, particularly in lyrics-to-song generation. However, existing approaches still struggle with the complex composition of songs and the scarcity of high-quality data, leading to limitations in sound quality, musicality, instruction following, and vocal-instrument harmony. To address these challenges, we introduce LeVo, an LM-based framework consisting of LeLM and a music codec. LeLM is capable of parallelly modeling two types of tokens: mixed tokens, which represent the combined audio of vocals and accompaniment to achieve vocal-instrument harmony, and dual-track tokens, which separately encode vocals and accompaniment for high-quality song generation. It employs two decoder-only transformers and a modular extension training strategy to prevent interference between different token types. To further enhance musicality and instruction following, we introduce a multi-preference alignment method based on Direct Preference Optimization (DPO). This method handles diverse human preferences through a semi-automatic data construction process and DPO post-training. Experimental results demonstrate that LeVo consistently outperforms existing methods on both objective and subjective metrics. Ablation studies further justify the effectiveness of our designs. Audio examples are available at https://levo-demo.github.io/.
RFTF: Reinforcement Fine-tuning for Embodied Agents with Temporal Feedback
May 26, 2025Vision-Language-Action (VLA) models have demonstrated significant potential in the field of embodied intelligence, enabling agents to follow human instructions to complete complex tasks in physical environments. Existing embodied agents are often trained through behavior cloning, which requires expensive data and computational resources and is constrained by human demonstrations. To address this issue, many researchers explore the application of reinforcement fine-tuning to embodied agents. However, typical reinforcement fine-tuning methods for embodied agents usually rely on sparse, outcome-based rewards, which struggle to provide fine-grained feedback for specific actions within an episode, thus limiting the model's manipulation capabilities and generalization performance. In this paper, we propose RFTF, a novel reinforcement fine-tuning method that leverages a value model to generate dense rewards in embodied scenarios. Specifically, our value model is trained using temporal information, eliminating the need for costly robot action labels. In addition, RFTF incorporates a range of techniques, such as GAE and sample balance to enhance the effectiveness of the fine-tuning process. By addressing the sparse reward problem in reinforcement fine-tuning, our method significantly improves the performance of embodied agents, delivering superior generalization and adaptation capabilities across diverse embodied tasks. Experimental results show that embodied agents fine-tuned with RFTF achieve new state-of-the-art performance on the challenging CALVIN ABC-D with an average success length of 4.296. Moreover, RFTF enables rapid adaptation to new environments. After fine-tuning in the D environment of CALVIN for a few episodes, RFTF achieved an average success length of 4.301 in this new environment.
VL-SAM-V2: Open-World Object Detection with General and Specific Query Fusion
May 25, 2025



Current perception models have achieved remarkable success by leveraging large-scale labeled datasets, but still face challenges in open-world environments with novel objects. To address this limitation, researchers introduce open-set perception models to detect or segment arbitrary test-time user-input categories. However, open-set models rely on human involvement to provide predefined object categories as input during inference. More recently, researchers have framed a more realistic and challenging task known as open-ended perception that aims to discover unseen objects without requiring any category-level input from humans at inference time. Nevertheless, open-ended models suffer from low performance compared to open-set models. In this paper, we present VL-SAM-V2, an open-world object detection framework that is capable of discovering unseen objects while achieving favorable performance. To achieve this, we combine queries from open-set and open-ended models and propose a general and specific query fusion module to allow different queries to interact. By adjusting queries from open-set models, we enable VL-SAM-V2 to be evaluated in the open-set or open-ended mode. In addition, to learn more diverse queries, we introduce ranked learnable queries to match queries with proposals from open-ended models by sorting. Moreover, we design a denoising point training strategy to facilitate the training process. Experimental results on LVIS show that our method surpasses the previous open-set and open-ended methods, especially on rare objects.
DiffCSS: Diverse and Expressive Conversational Speech Synthesis with Diffusion Models
Feb 27, 2025



Conversational speech synthesis (CSS) aims to synthesize both contextually appropriate and expressive speech, and considerable efforts have been made to enhance the understanding of conversational context. However, existing CSS systems are limited to deterministic prediction, overlooking the diversity of potential responses. Moreover, they rarely employ language model (LM)-based TTS backbones, limiting the naturalness and quality of synthesized speech. To address these issues, in this paper, we propose DiffCSS, an innovative CSS framework that leverages diffusion models and an LM-based TTS backbone to generate diverse, expressive, and contextually coherent speech. A diffusion-based context-aware prosody predictor is proposed to sample diverse prosody embeddings conditioned on multimodal conversational context. Then a prosody-controllable LM-based TTS backbone is developed to synthesize high-quality speech with sampled prosody embeddings. Experimental results demonstrate that the synthesized speech from DiffCSS is more diverse, contextually coherent, and expressive than existing CSS systems
RobuRCDet: Enhancing Robustness of Radar-Camera Fusion in Bird's Eye View for 3D Object Detection
Feb 18, 2025While recent low-cost radar-camera approaches have shown promising results in multi-modal 3D object detection, both sensors face challenges from environmental and intrinsic disturbances. Poor lighting or adverse weather conditions degrade camera performance, while radar suffers from noise and positional ambiguity. Achieving robust radar-camera 3D object detection requires consistent performance across varying conditions, a topic that has not yet been fully explored. In this work, we first conduct a systematic analysis of robustness in radar-camera detection on five kinds of noises and propose RobuRCDet, a robust object detection model in BEV. Specifically, we design a 3D Gaussian Expansion (3DGE) module to mitigate inaccuracies in radar points, including position, Radar Cross-Section (RCS), and velocity. The 3DGE uses RCS and velocity priors to generate a deformable kernel map and variance for kernel size adjustment and value distribution. Additionally, we introduce a weather-adaptive fusion module, which adaptively fuses radar and camera features based on camera signal confidence. Extensive experiments on the popular benchmark, nuScenes, show that our model achieves competitive results in regular and noisy conditions.