 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAIN-VLA: Modeling Abstraction of Intention and eNvironment for Vision-Language-Action Models
Feb 02, 2026Despite significant progress in Visual-Language-Action (VLA), in highly complex and dynamic environments that involve real-time unpredictable interactions (such as 3D open worlds and large-scale PvP games), existing approaches remain inefficient at extracting action-critical signals from redundant sensor streams. To tackle this, we introduce MAIN-VLA, a framework that explicitly Models the Abstraction of Intention and eNvironment to ground decision-making in deep semantic alignment rather than superficial pattern matching. Specifically, our Intention Abstraction (IA) extracts verbose linguistic instructions and their associated reasoning into compact, explicit semantic primitives, while the Environment Semantics Abstraction (ESA) projects overwhelming visual streams into a structured, topological affordance representation. Furthermore, aligning these two abstract modalities induces an emergent attention-concentration effect, enabling a parameter-free token-pruning strategy that filters out perceptual redundancy without degrading performance. Extensive experiments in open-world Minecraft and large-scale PvP environments (Game for Peace and Valorant) demonstrate that MAIN-VLA sets a new state-of-the-art, which achieves superior decision quality, stronger generalization, and cutting-edge inference efficiency.
Spark-Prover-X1: Formal Theorem Proving Through Diverse Data Training
Nov 18, 2025Large Language Models (LLMs) have shown significant promise in automated theorem proving, yet progress is often constrained by the scarcity of diverse and high-quality formal language data. To address this issue, we introduce Spark-Prover-X1, a 7B parameter model trained via an three-stage framework designed to unlock the reasoning potential of more accessible and moderately-sized LLMs. The first stage infuses deep knowledge through continuous pre-training on a broad mathematical corpus, enhanced by a suite of novel data tasks. Key innovation is a "CoT-augmented state prediction" task to achieve fine-grained reasoning. The second stage employs Supervised Fine-tuning (SFT) within an expert iteration loop to specialize both the Spark-Prover-X1-7B and Spark-Formalizer-X1-7B models. Finally, a targeted round of Group Relative Policy Optimization (GRPO) is applied to sharpen the prover's capabilities on the most challenging problems. To facilitate robust evaluation, particularly on problems from real-world examinations, we also introduce ExamFormal-Bench, a new benchmark dataset of 402 formal problems. Experimental results demonstrate that Spark-Prover achieves state-of-the-art performance among similarly-sized open-source models within the "Whole-Proof Generation" paradigm. It shows exceptional performance on difficult competition benchmarks, notably solving 27 problems on PutnamBench (pass@32) and achieving 24.0\% on CombiBench (pass@32). Our work validates that this diverse training data and progressively refined training pipeline provides an effective path for enhancing the formal reasoning capabilities of lightweight LLMs. Both Spark-Prover-X1-7B and Spark-Formalizer-X1-7B, along with the ExamFormal-Bench dataset, are made publicly available at: https://www.modelscope.cn/organization/iflytek, https://gitcode.com/ifly_opensource.
Fine-Grained DINO Tuning with Dual Supervision for Face Forgery Detection
Nov 15, 2025The proliferation of sophisticated deepfakes poses significant threats to information integrity. While DINOv2 shows promise for detection, existing fine-tuning approaches treat it as generic binary classification, overlooking distinct artifacts inherent to different deepfake methods. To address this, we propose a DeepFake Fine-Grained Adapter (DFF-Adapter) for DINOv2. Our method incorporates lightweight multi-head LoRA modules into every transformer block, enabling efficient backbone adaptation. DFF-Adapter simultaneously addresses authenticity detection and fine-grained manipulation type classification, where classifying forgery methods enhances artifact sensitivity. We introduce a shared branch propagating fine-grained manipulation cues to the authenticity head. This enables multi-task cooperative optimization, explicitly enhancing authenticity discrimination with manipulation-specific knowledge. Utilizing only 3.5M trainable parameters, our parameter-efficient approach achieves detection accuracy comparable to or even surpassing that of current complex state-of-the-art methods.
DrivingGaussian++: Towards Realistic Reconstruction and Editable Simulation for Surrounding Dynamic Driving Scenes
Aug 28, 2025We present DrivingGaussian++, an efficient and effective framework for realistic reconstructing and controllable editing of surrounding dynamic autonomous driving scenes. DrivingGaussian++ models the static background using incremental 3D Gaussians and reconstructs moving objects with a composite dynamic Gaussian graph, ensuring accurate positions and occlusions. By integrating a LiDAR prior, it achieves detailed and consistent scene reconstruction, outperforming existing methods in dynamic scene reconstruction and photorealistic surround-view synthesis. DrivingGaussian++ supports training-free controllable editing for dynamic driving scenes, including texture modification, weather simulation, and object manipulation, leveraging multi-view images and depth priors. By integrating large language models (LLMs) and controllable editing, our method can automatically generate dynamic object motion trajectories and enhance their realism during the optimization process. DrivingGaussian++ demonstrates consistent and realistic editing results and generates dynamic multi-view driving scenarios, while significantly enhancing scene diversity. More results and code can be found at the project site: https://xiong-creator.github.io/DrivingGaussian_plus.github.io
RobuRCDet: Enhancing Robustness of Radar-Camera Fusion in Bird's Eye View for 3D Object Detection
Feb 18, 2025While recent low-cost radar-camera approaches have shown promising results in multi-modal 3D object detection, both sensors face challenges from environmental and intrinsic disturbances. Poor lighting or adverse weather conditions degrade camera performance, while radar suffers from noise and positional ambiguity. Achieving robust radar-camera 3D object detection requires consistent performance across varying conditions, a topic that has not yet been fully explored. In this work, we first conduct a systematic analysis of robustness in radar-camera detection on five kinds of noises and propose RobuRCDet, a robust object detection model in BEV. Specifically, we design a 3D Gaussian Expansion (3DGE) module to mitigate inaccuracies in radar points, including position, Radar Cross-Section (RCS), and velocity. The 3DGE uses RCS and velocity priors to generate a deformable kernel map and variance for kernel size adjustment and value distribution. Additionally, we introduce a weather-adaptive fusion module, which adaptively fuses radar and camera features based on camera signal confidence. Extensive experiments on the popular benchmark, nuScenes, show that our model achieves competitive results in regular and noisy conditions.
OccGS: Zero-shot 3D Occupancy Reconstruction with Semantic and Geometric-Aware Gaussian Splatting
Feb 07, 2025
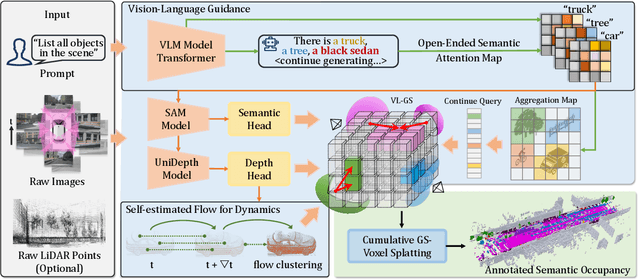
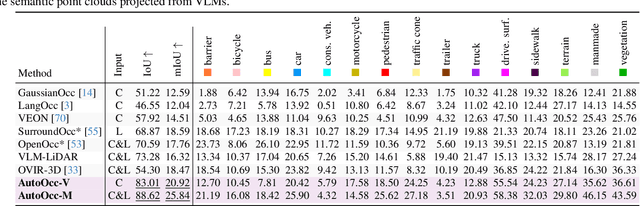
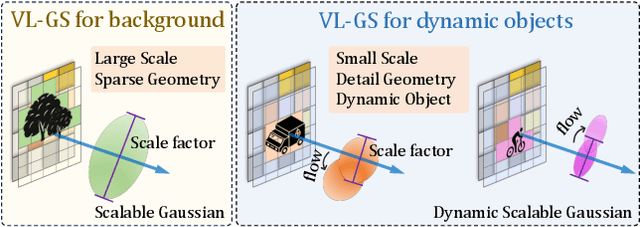
Obtaining semantic 3D occupancy from raw sensor data without manual annotations remains an essential yet challenging task. While prior works have approached this as a perception prediction problem, we formulate it as scene-aware 3D occupancy reconstruction with geometry and semantics. In this work, we propose OccGS, a novel 3D Occupancy reconstruction framework utilizing Semantic and Geometric-Aware Gaussian Splatting in a zero-shot manner. Leveraging semantics extracted from vision-language models and geometry guided by LiDAR points, OccGS constructs Semantic and Geometric-Aware Gaussians from raw multisensor data. We also develop a cumulative Gaussian-to-3D voxel splatting method for reconstructing occupancy from the Gaussians. OccGS performs favorably against self-supervised methods in occupancy prediction, achieving comparable performance to fully supervised approaches and achieving state-of-the-art performance on zero-shot semantic 3D occupancy estimation.
GALA3D: Towards Text-to-3D Complex Scene Generation via Layout-guided Generative Gaussian Splatting
Feb 11, 2024



We present GALA3D, generative 3D GAussians with LAyout-guided control, for effective compositional text-to-3D generation. We first utilize large language models (LLMs) to generate the initial layout and introduce a layout-guided 3D Gaussian representation for 3D content generation with adaptive geometric constraints. We then propose an object-scene compositional optimization mechanism with conditioned diffusion to collaboratively generate realistic 3D scenes with consistent geometry, texture, scale, and accurate interactions among multiple objects while simultaneously adjusting the coarse layout priors extracted from the LLMs to align with the generated scene. Experiments show that GALA3D is a user-friendly, end-to-end framework for state-of-the-art scene-level 3D content generation and controllable editing while ensuring the high fidelity of object-level entities within the scene. Source codes and models will be available at https://gala3d.github.io/.
DrivingGaussian: Composite Gaussian Splatting for Surrounding Dynamic Autonomous Driving Scenes
Dec 13, 2023



We present DrivingGaussian, an efficient and effective framework for surrounding dynamic autonomous driving scenes. For complex scenes with moving objects, we first sequentially and progressively model the static background of the entire scene with incremental static 3D Gaussians. We then leverage a composite dynamic Gaussian graph to handle multiple moving objects, individually reconstructing each object and restoring their accurate positions and occlusion relationships within the scene. We further use a LiDAR prior for Gaussian Splatting to reconstruct scenes with greater details and maintain panoramic consistency. DrivingGaussian outperforms existing methods in driving scene reconstruction and enables photorealistic surround-view synthesis with high-fidelity and multi-camera consistency. The source code and trained models will be released.
PET Tracer Conversion among Brain PET via Variable Augmented Invertible Network
Nov 15, 2023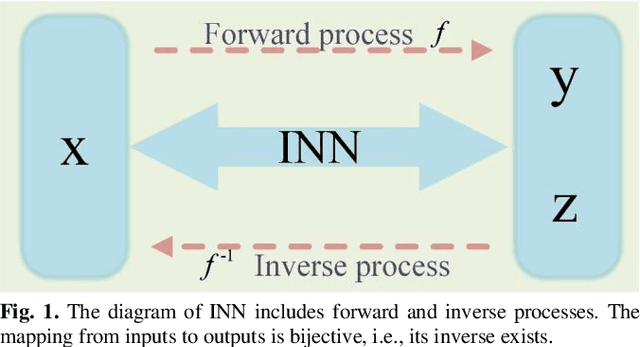
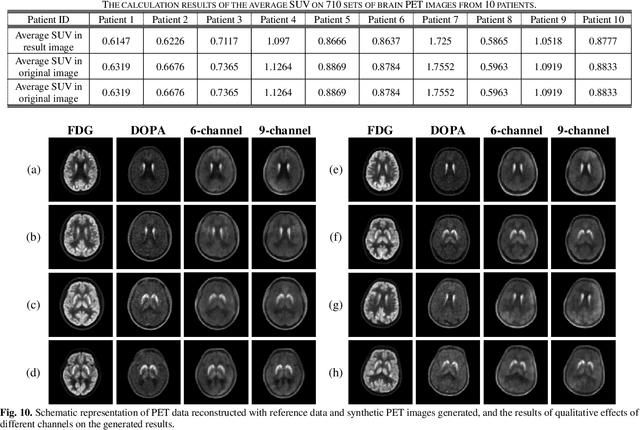
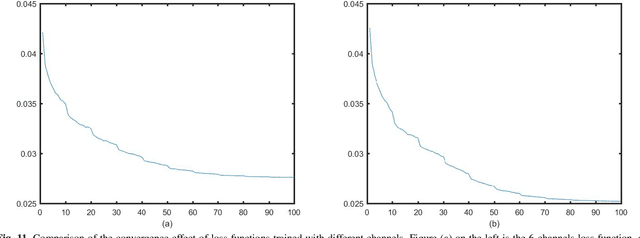
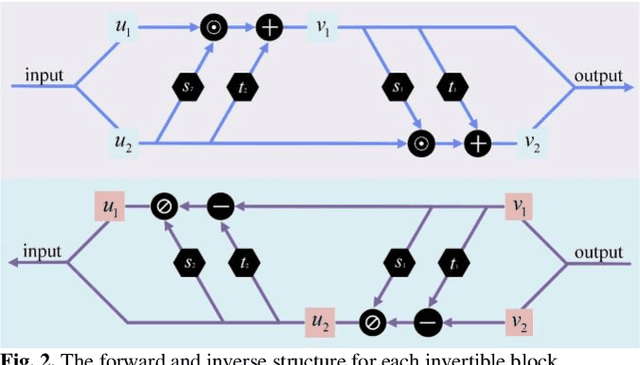
Positron emission tomography (PET) serves as an essential tool for diagnosis of encephalopathy and brain science research. However, it suffers from the limited choice of tracers. Nowadays, with the wide application of PET imaging in neuropsychiatric treatment, 6-18F-fluoro-3, 4-dihydroxy-L-phenylalanine (DOPA) has been found to be more effective than 18F-labeled fluorine-2-deoxyglucose (FDG) in the field. Nevertheless, due to the complexity of its preparation and other limitations, DOPA is far less widely used than FDG. To address this issue, a tracer conversion invertible neural network (TC-INN) for image projection is developed to map FDG images to DOPA images through deep learning. More diagnostic information is obtained by generating PET images from FDG to DOPA. Specifically, the proposed TC-INN consists of two separate phases, one for training traceable data, the other for rebuilding new data. The reference DOPA PET image is used as a learning target for the corresponding network during the training process of tracer conversion. Meanwhile, the invertible network iteratively estimates the resultant DOPA PET data and compares it to the reference DOPA PET data. Notably, the reversible model employs variable enhancement technique to achieve better power generation. Moreover, image registration needs to be performed before training due to the angular deviation of the acquired FDG and DOPA data information. Experimental results exhibited excellent generation capability in mapping between FDG and DOPA, suggesting that PET tracer conversion has great potential in the case of limited tracer applications.
SAMPLING: Scene-adaptive Hierarchical Multiplane Images Representation for Novel View Synthesis from a Single Image
Sep 13, 2023Recent novel view synthesis methods obtain promising results for relatively small scenes, e.g., indoor environments and scenes with a few objects, but tend to fail for unbounded outdoor scenes with a single image as input. In this paper, we introduce SAMPLING, a Scene-adaptive Hierarchical Multiplane Images Representation for Novel View Synthesis from a Single Image based on improved multiplane images (MPI). Observing that depth distribution varies significantly for unbounded outdoor scenes, we employ an adaptive-bins strategy for MPI to arrange planes in accordance with each scene image. To represent intricate geometry and multi-scale details, we further introduce a hierarchical refinement branch, which results in high-quality synthesized novel views. Our method demonstrates considerable performance gains in synthesizing large-scale unbounded outdoor scenes using a single image on the KITTI dataset and generalizes well to the unseen Tanks and Temples dataset.The code and models will soon be made available.