 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOccGS: Zero-shot 3D Occupancy Reconstruction with Semantic and Geometric-Aware Gaussian Splatting
Feb 07, 2025
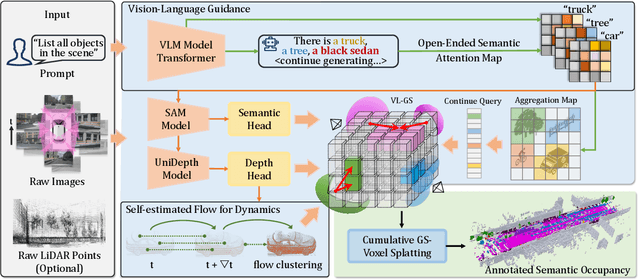
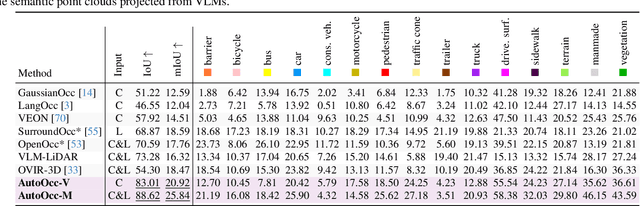
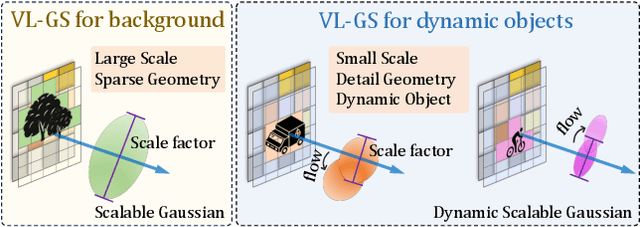
Obtaining semantic 3D occupancy from raw sensor data without manual annotations remains an essential yet challenging task. While prior works have approached this as a perception prediction problem, we formulate it as scene-aware 3D occupancy reconstruction with geometry and semantics. In this work, we propose OccGS, a novel 3D Occupancy reconstruction framework utilizing Semantic and Geometric-Aware Gaussian Splatting in a zero-shot manner. Leveraging semantics extracted from vision-language models and geometry guided by LiDAR points, OccGS constructs Semantic and Geometric-Aware Gaussians from raw multisensor data. We also develop a cumulative Gaussian-to-3D voxel splatting method for reconstructing occupancy from the Gaussians. OccGS performs favorably against self-supervised methods in occupancy prediction, achieving comparable performance to fully supervised approaches and achieving state-of-the-art performance on zero-shot semantic 3D occupancy estimation.
COVID-19 SignSym: A fast adaptation of general clinical NLP tools to identify and normalize COVID-19 signs and symptoms to OMOP common data model
Jul 13, 2020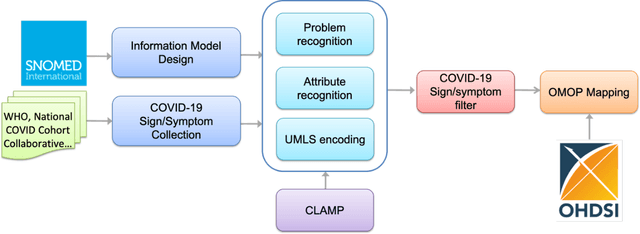



The COVID-19 pandemic swept across the world rapidly infecting millions of people. An efficient tool that can accurately recognize important clinical concepts of COVID-19 from free text in electronic health records will be significantly valuable to accelerate various applications of COVID-19 research. To this end, the existing clinical NLP tool CLAMP was quickly adapted to COVID-19 information and generated an automated tool called COVID-19 SignSym, which can extract and signs/symptoms and their eight attributes such as temporal information and negations from clinical text. The extracted information is also mapped to standard clinical concepts in the common data model of OHDSI OMOP. Evaluation on clinical notes and medical dialogues demonstrated promising results. It is freely accessible to the community as a downloadable package of APIs (https://clamp.uth.edu/covid/nlp.php). We believe COVID-19 SignSym will provide fundamental supports to the secondary use of EHRs, thus accelerating the global research of COVID-19.
Enhancing Clinical Concept Extraction with Contextual Embedding
Feb 22, 2019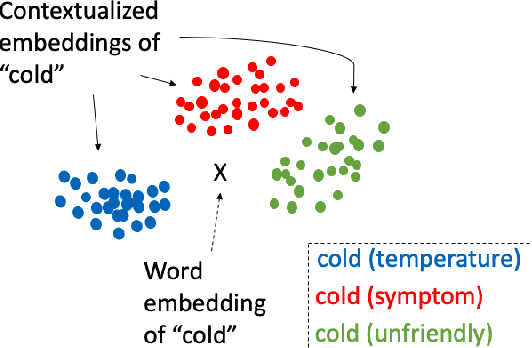
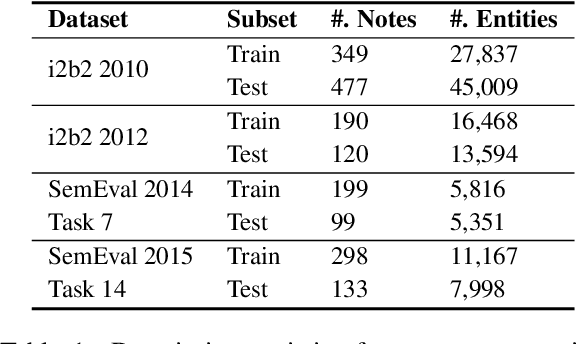
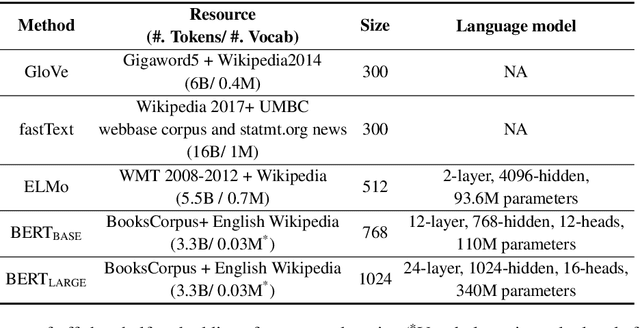
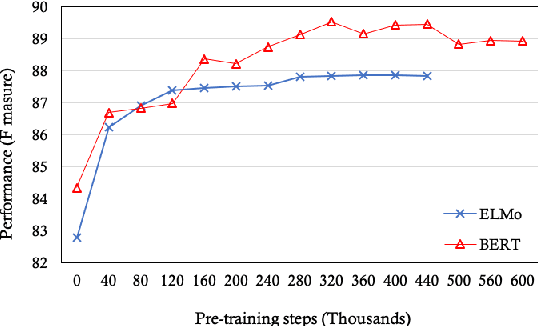
Neural network-based representations ("embeddings") have dramatically advanced natural language processing (NLP) tasks in the past few years. This certainly holds for clinical concept extraction, especially when combined with deep learning-based models. Recently, however, more advanced embedding methods and representations (e.g., ELMo, BERT) have further pushed the state-of-the-art in NLP. While these certainly improve clinical concept extraction as well, there are no commonly agreed upon best practices for how to integrate these representations for extracting concepts. The purpose of this study, then, is to explore the space of possible options in utilizing these new models, including comparing these to more traditional word embedding methods (word2vec, GloVe, fastText). We evaluate a battery of embedding methods on four clinical concept extraction corpora, explore effects of pre-training on extraction performance, and present an intuitive way to understand the semantic information encoded by advanced contextualized representations. Notably, we achieved new state-of-the-art performances across all four corpora.