 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOccGS: Zero-shot 3D Occupancy Reconstruction with Semantic and Geometric-Aware Gaussian Splatting
Feb 07, 2025
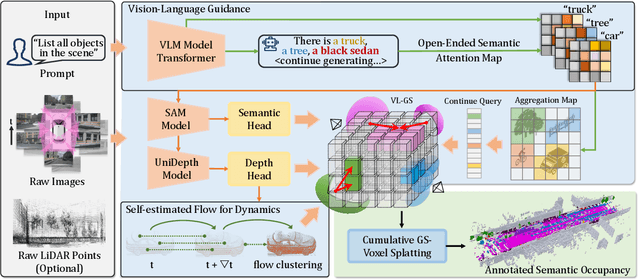
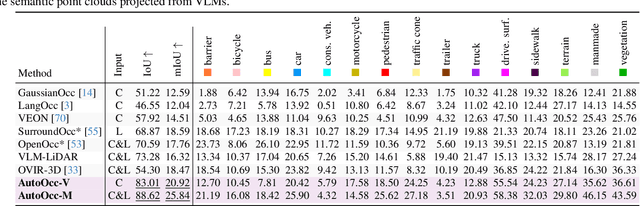
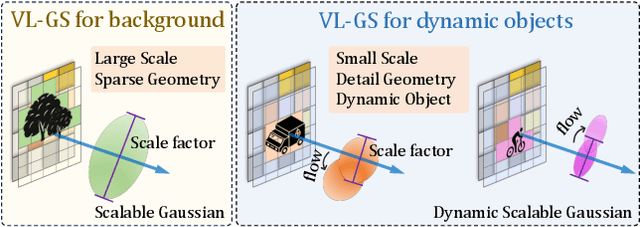
Obtaining semantic 3D occupancy from raw sensor data without manual annotations remains an essential yet challenging task. While prior works have approached this as a perception prediction problem, we formulate it as scene-aware 3D occupancy reconstruction with geometry and semantics. In this work, we propose OccGS, a novel 3D Occupancy reconstruction framework utilizing Semantic and Geometric-Aware Gaussian Splatting in a zero-shot manner. Leveraging semantics extracted from vision-language models and geometry guided by LiDAR points, OccGS constructs Semantic and Geometric-Aware Gaussians from raw multisensor data. We also develop a cumulative Gaussian-to-3D voxel splatting method for reconstructing occupancy from the Gaussians. OccGS performs favorably against self-supervised methods in occupancy prediction, achieving comparable performance to fully supervised approaches and achieving state-of-the-art performance on zero-shot semantic 3D occupancy estimation.
TEOcc: Radar-camera Multi-modal Occupancy Prediction via Temporal Enhancement
Oct 15, 2024



As a novel 3D scene representation, semantic occupancy has gained much attention in autonomous driving. However, existing occupancy prediction methods mainly focus on designing better occupancy representations, such as tri-perspective view or neural radiance fields, while ignoring the advantages of using long-temporal information. In this paper, we propose a radar-camera multi-modal temporal enhanced occupancy prediction network, dubbed TEOcc. Our method is inspired by the success of utilizing temporal information in 3D object detection. Specifically, we introduce a temporal enhancement branch to learn temporal occupancy prediction. In this branch, we randomly discard the t-k input frame of the multi-view camera and predict its 3D occupancy by long-term and short-term temporal decoders separately with the information from other adjacent frames and multi-modal inputs. Besides, to reduce computational costs and incorporate multi-modal inputs, we specially designed 3D convolutional layers for long-term and short-term temporal decoders. Furthermore, since the lightweight occupancy prediction head is a dense classification head, we propose to use a shared occupancy prediction head for the temporal enhancement and main branches. It is worth noting that the temporal enhancement branch is only performed during training and is discarded during inference. Experiment results demonstrate that TEOcc achieves state-of-the-art occupancy prediction on nuScenes benchmarks. In addition, the proposed temporal enhancement branch is a plug-and-play module that can be easily integrated into existing occupancy prediction methods to improve the performance of occupancy prediction. The code and models will be released at https://github.com/VDIGPKU/TEOcc.
HENet: Hybrid Encoding for End-to-end Multi-task 3D Perception from Multi-view Cameras
Apr 03, 2024



Three-dimensional perception from multi-view cameras is a crucial component in autonomous driving systems, which involves multiple tasks like 3D object detection and bird's-eye-view (BEV) semantic segmentation. To improve perception precision, large image encoders, high-resolution images, and long-term temporal inputs have been adopted in recent 3D perception models, bringing remarkable performance gains. However, these techniques are often incompatible in training and inference scenarios due to computational resource constraints. Besides, modern autonomous driving systems prefer to adopt an end-to-end framework for multi-task 3D perception, which can simplify the overall system architecture and reduce the implementation complexity. However, conflict between tasks often arises when optimizing multiple tasks jointly within an end-to-end 3D perception model. To alleviate these issues, we present an end-to-end framework named HENet for multi-task 3D perception in this paper. Specifically, we propose a hybrid image encoding network, using a large image encoder for short-term frames and a small image encoder for long-term temporal frames. Then, we introduce a temporal feature integration module based on the attention mechanism to fuse the features of different frames extracted by the two aforementioned hybrid image encoders. Finally, according to the characteristics of each perception task, we utilize BEV features of different grid sizes, independent BEV encoders, and task decoders for different tasks. Experimental results show that HENet achieves state-of-the-art end-to-end multi-task 3D perception results on the nuScenes benchmark, including 3D object detection and BEV semantic segmentation. The source code and models will be released at https://github.com/VDIGPKU/HENet.
RCBEVDet: Radar-camera Fusion in Bird's Eye View for 3D Object Detection
Mar 25, 2024



Three-dimensional object detection is one of the key tasks in autonomous driving. To reduce costs in practice, low-cost multi-view cameras for 3D object detection are proposed to replace the expansive LiDAR sensors. However, relying solely on cameras is difficult to achieve highly accurate and robust 3D object detection. An effective solution to this issue is combining multi-view cameras with the economical millimeter-wave radar sensor to achieve more reliable multi-modal 3D object detection. In this paper, we introduce RCBEVDet, a radar-camera fusion 3D object detection method in the bird's eye view (BEV). Specifically, we first design RadarBEVNet for radar BEV feature extraction. RadarBEVNet consists of a dual-stream radar backbone and a Radar Cross-Section (RCS) aware BEV encoder. In the dual-stream radar backbone, a point-based encoder and a transformer-based encoder are proposed to extract radar features, with an injection and extraction module to facilitate communication between the two encoders. The RCS-aware BEV encoder takes RCS as the object size prior to scattering the point feature in BEV. Besides, we present the Cross-Attention Multi-layer Fusion module to automatically align the multi-modal BEV feature from radar and camera with the deformable attention mechanism, and then fuse the feature with channel and spatial fusion layers. Experimental results show that RCBEVDet achieves new state-of-the-art radar-camera fusion results on nuScenes and view-of-delft (VoD) 3D object detection benchmarks. Furthermore, RCBEVDet achieves better 3D detection results than all real-time camera-only and radar-camera 3D object detectors with a faster inference speed at 21~28 FPS. The source code will be released at https://github.com/VDIGPKU/RCBEVDet.