 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRCBEVDet: Radar-camera Fusion in Bird's Eye View for 3D Object Detection
Mar 25, 2024



Three-dimensional object detection is one of the key tasks in autonomous driving. To reduce costs in practice, low-cost multi-view cameras for 3D object detection are proposed to replace the expansive LiDAR sensors. However, relying solely on cameras is difficult to achieve highly accurate and robust 3D object detection. An effective solution to this issue is combining multi-view cameras with the economical millimeter-wave radar sensor to achieve more reliable multi-modal 3D object detection. In this paper, we introduce RCBEVDet, a radar-camera fusion 3D object detection method in the bird's eye view (BEV). Specifically, we first design RadarBEVNet for radar BEV feature extraction. RadarBEVNet consists of a dual-stream radar backbone and a Radar Cross-Section (RCS) aware BEV encoder. In the dual-stream radar backbone, a point-based encoder and a transformer-based encoder are proposed to extract radar features, with an injection and extraction module to facilitate communication between the two encoders. The RCS-aware BEV encoder takes RCS as the object size prior to scattering the point feature in BEV. Besides, we present the Cross-Attention Multi-layer Fusion module to automatically align the multi-modal BEV feature from radar and camera with the deformable attention mechanism, and then fuse the feature with channel and spatial fusion layers. Experimental results show that RCBEVDet achieves new state-of-the-art radar-camera fusion results on nuScenes and view-of-delft (VoD) 3D object detection benchmarks. Furthermore, RCBEVDet achieves better 3D detection results than all real-time camera-only and radar-camera 3D object detectors with a faster inference speed at 21~28 FPS. The source code will be released at https://github.com/VDIGPKU/RCBEVDet.
From Pixel to Slide image: Polarization Modality-based Pathological Diagnosis Using Representation Learning
Jan 03, 2024



Thyroid cancer is the most common endocrine malignancy, and accurately distinguishing between benign and malignant thyroid tumors is crucial for developing effective treatment plans in clinical practice. Pathologically, thyroid tumors pose diagnostic challenges due to improper specimen sampling. In this study, we have designed a three-stage model using representation learning to integrate pixel-level and slice-level annotations for distinguishing thyroid tumors. This structure includes a pathology structure recognition method to predict structures related to thyroid tumors, an encoder-decoder network to extract pixel-level annotation information by learning the feature representations of image blocks, and an attention-based learning mechanism for the final classification task. This mechanism learns the importance of different image blocks in a pathological region, globally considering the information from each block. In the third stage, all information from the image blocks in a region is aggregated using attention mechanisms, followed by classification to determine the category of the region. Experimental results demonstrate that our proposed method can predict microscopic structures more accurately. After color-coding, the method achieves results on unstained pathology slides that approximate the quality of Hematoxylin and eosin staining, reducing the need for stained pathology slides. Furthermore, by leveraging the concept of indirect measurement and extracting polarized features from structures correlated with lesions, the proposed method can also classify samples where membrane structures cannot be obtained through sampling, providing a potential objective and highly accurate indirect diagnostic technique for thyroid tumors.
A Polarization and Radiomics Feature Fusion Network for the Classification of Hepatocellular Carcinoma and Intrahepatic Cholangiocarcinoma
Dec 27, 2023Classifying hepatocellular carcinoma (HCC) and intrahepatic cholangiocarcinoma (ICC) is a critical step in treatment selection and prognosis evaluation for patients with liver diseases. Traditional histopathological diagnosis poses challenges in this context. In this study, we introduce a novel polarization and radiomics feature fusion network, which combines polarization features obtained from Mueller matrix images of liver pathological samples with radiomics features derived from corresponding pathological images to classify HCC and ICC. Our fusion network integrates a two-tier fusion approach, comprising early feature-level fusion and late classification-level fusion. By harnessing the strengths of polarization imaging techniques and image feature-based machine learning, our proposed fusion network significantly enhances classification accuracy. Notably, even at reduced imaging resolutions, the fusion network maintains robust performance due to the additional information provided by polarization features, which may not align with human visual perception. Our experimental results underscore the potential of this fusion network as a powerful tool for computer-aided diagnosis of HCC and ICC, showcasing the benefits and prospects of integrating polarization imaging techniques into the current image-intensive digital pathological diagnosis. We aim to contribute this innovative approach to top-tier journals, offering fresh insights and valuable tools in the fields of medical imaging and cancer diagnosis. By introducing polarization imaging into liver cancer classification, we demonstrate its interdisciplinary potential in addressing challenges in medical image analysis, promising advancements in medical imaging and cancer diagnosis.
Learn from Yesterday: A Semi-Supervised Continual Learning Method for Supervision-Limited Text-to-SQL Task Streams
Nov 21, 2022



Conventional text-to-SQL studies are limited to a single task with a fixed-size training and test set. When confronted with a stream of tasks common in real-world applications, existing methods struggle with the problems of insufficient supervised data and high retraining costs. The former tends to cause overfitting on unseen databases for the new task, while the latter makes a full review of instances from past tasks impractical for the model, resulting in forgetting of learned SQL structures and database schemas. To address the problems, this paper proposes integrating semi-supervised learning (SSL) and continual learning (CL) in a stream of text-to-SQL tasks and offers two promising solutions in turn. The first solution Vanilla is to perform self-training, augmenting the supervised training data with predicted pseudo-labeled instances of the current task, while replacing the full volume retraining with episodic memory replay to balance the training efficiency with the performance of previous tasks. The improved solution SFNet takes advantage of the intrinsic connection between CL and SSL. It uses in-memory past information to help current SSL, while adding high-quality pseudo instances in memory to improve future replay. The experiments on two datasets shows that SFNet outperforms the widely-used SSL-only and CL-only baselines on multiple metrics.
HeteroQA: Learning towards Question-and-Answering through Multiple Information Sources via Heterogeneous Graph Modeling
Dec 27, 2021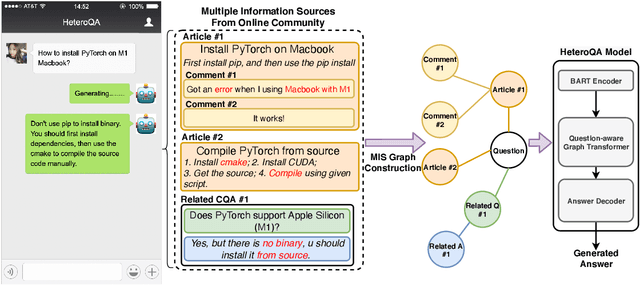

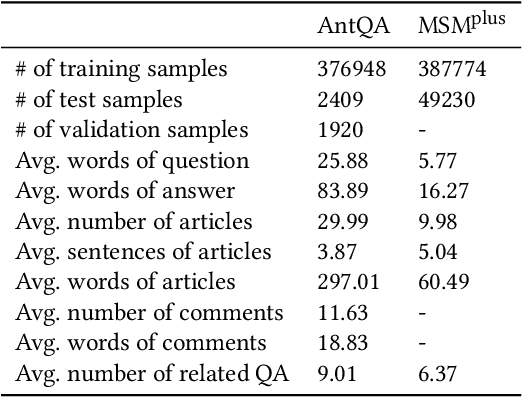
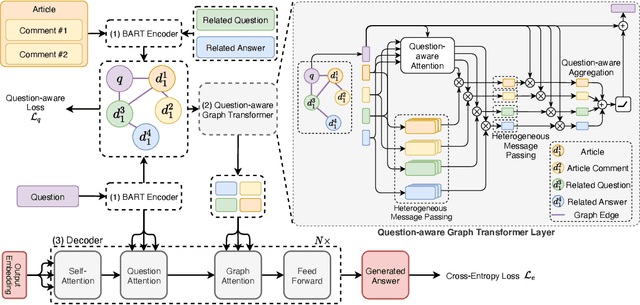
Community Question Answering (CQA) is a well-defined task that can be used in many scenarios, such as E-Commerce and online user community for special interests. In these communities, users can post articles, give comment, raise a question and answer it. These data form the heterogeneous information sources where each information source have their own special structure and context (comments attached to an article or related question with answers). Most of the CQA methods only incorporate articles or Wikipedia to extract knowledge and answer the user's question. However, various types of information sources in the community are not fully explored by these CQA methods and these multiple information sources (MIS) can provide more related knowledge to user's questions. Thus, we propose a question-aware heterogeneous graph transformer to incorporate the MIS in the user community to automatically generate the answer. To evaluate our proposed method, we conduct the experiments on two datasets: $\text{MSM}^{\text{plus}}$ the modified version of benchmark dataset MS-MARCO and the AntQA dataset which is the first large-scale CQA dataset with four types of MIS. Extensive experiments on two datasets show that our model outperforms all the baselines in terms of all the metrics.
S+PAGE: A Speaker and Position-Aware Graph Neural Network Model for Emotion Recognition in Conversation
Dec 23, 2021


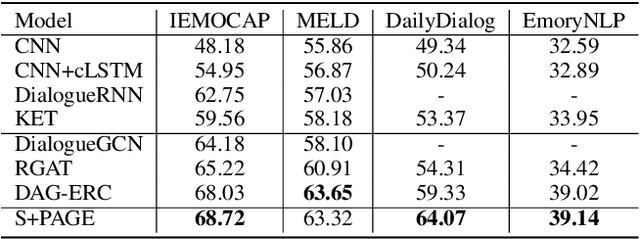
Emotion recognition in conversation (ERC) has attracted much attention in recent years for its necessity in widespread applications. Existing ERC methods mostly model the self and inter-speaker context separately, posing a major issue for lacking enough interaction between them. In this paper, we propose a novel Speaker and Position-Aware Graph neural network model for ERC (S+PAGE), which contains three stages to combine the benefits of both Transformer and relational graph convolution network (R-GCN) for better contextual modeling. Firstly, a two-stream conversational Transformer is presented to extract the coarse self and inter-speaker contextual features for each utterance. Then, a speaker and position-aware conversation graph is constructed, and we propose an enhanced R-GCN model, called PAG, to refine the coarse features guided by a relative positional encoding. Finally, both of the features from the former two stages are input into a conditional random field layer to model the emotion transfer.
Relation Aware Semi-autoregressive Semantic Parsing for NL2SQL
Aug 02, 2021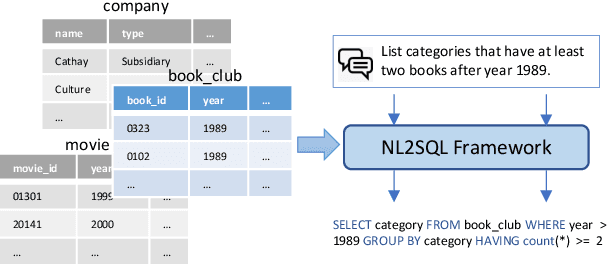
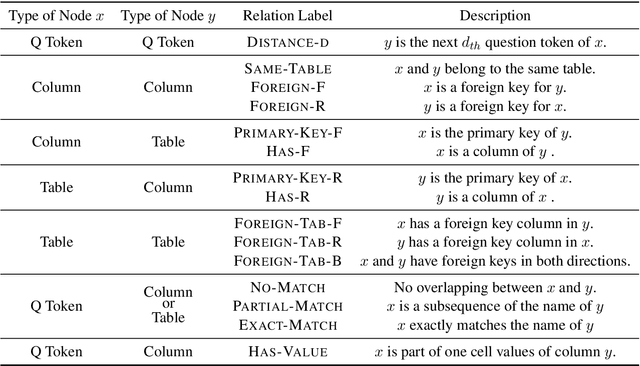
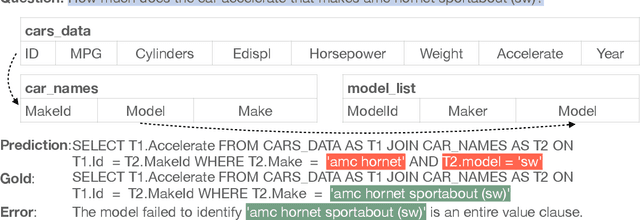
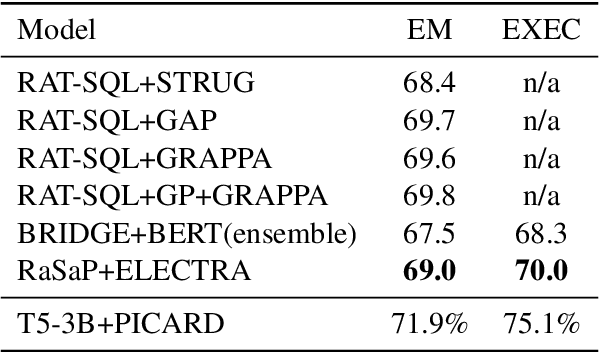
Natural language to SQL (NL2SQL) aims to parse a natural language with a given database into a SQL query, which widely appears in practical Internet applications. Jointly encode database schema and question utterance is a difficult but important task in NL2SQL. One solution is to treat the input as a heterogeneous graph. However, it failed to learn good word representation in question utterance. Learning better word representation is important for constructing a well-designed NL2SQL system. To solve the challenging task, we present a Relation aware Semi-autogressive Semantic Parsing (\MODN) ~framework, which is more adaptable for NL2SQL. It first learns relation embedding over the schema entities and question words with predefined schema relations with ELECTRA and relation aware transformer layer as backbone. Then we decode the query SQL with a semi-autoregressive parser and predefined SQL syntax. From empirical results and case study, our model shows its effectiveness in learning better word representation in NL2SQL.
SeaD: End-to-end Text-to-SQL Generation with Schema-aware Denoising
May 17, 2021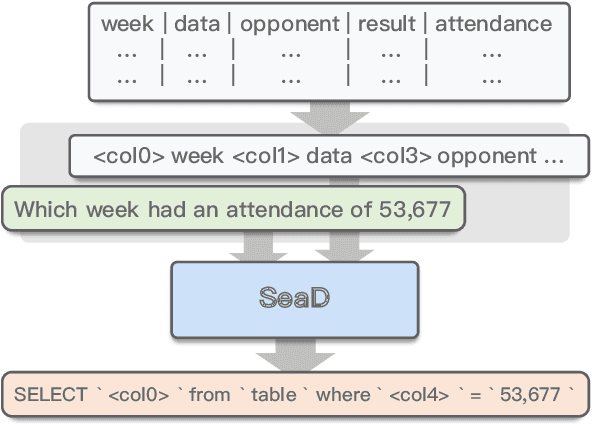
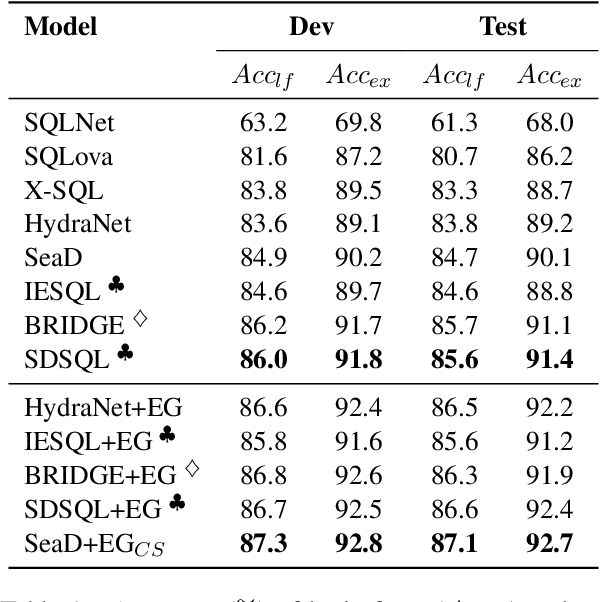

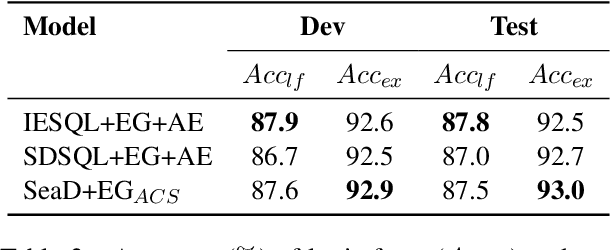
In text-to-SQL task, seq-to-seq models often lead to sub-optimal performance due to limitations in their architecture. In this paper, we present a simple yet effective approach that adapts transformer-based seq-to-seq model to robust text-to-SQL generation. Instead of inducing constraint to decoder or reformat the task as slot-filling, we propose to train seq-to-seq model with Schema aware Denoising (SeaD), which consists of two denoising objectives that train model to either recover input or predict output from two novel erosion and shuffle noises. These denoising objectives acts as the auxiliary tasks for better modeling the structural data in S2S generation. In addition, we improve and propose a clause-sensitive execution guided (EG) decoding strategy to overcome the limitation of EG decoding for generative model. The experiments show that the proposed method improves the performance of seq-to-seq model in both schema linking and grammar correctness and establishes new state-of-the-art on WikiSQL benchmark. The results indicate that the capacity of vanilla seq-to-seq architecture for text-to-SQL may have been under-estimated.