 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulation-Driven Evolutionary Motion Parameterization for Contact-Rich Granular Scooping with a Soft Conical Robotic Hand
Apr 07, 2026Tool-based scooping is vital in robot-assisted tasks, enabling interaction with objects of varying sizes, shapes, and material states. Recent studies have shown that flexible, reconfigurable soft robotic end-effectors can adapt their shape to maintain consistent contact with container surfaces during scooping, improving efficiency compared to rigid tools. These soft tools can adjust to varying container sizes and materials without requiring complex sensing or control. However, the inherent compliance and complex deformation behavior of soft robotics introduce significant control complexity that limits practical applications. To address this challenge, this paper presents the development of a physics-based simulation model of a deformable soft conical robotic hand that captures its passive reconfiguration dynamics and enables systematic trajectory optimization for scooping tasks. We propose a novel physics-based simulation approach that accurately models the soft tool's morphing behavior from flat sheets to adaptive conical structures, combined with an evolutionary strategy framework that automatically optimizes scooping trajectories without manual parameter tuning. We validate the optimized trajectories through both simulation and real-robot experiments. The results demonstrate strong generalization and successfully address a range of challenging tasks previously beyond the reach of existing approaches. Videos of our experiments are available online: https://sites.google.com/view/scoopsh
RieMind: Geometry-Grounded Spatial Agent for Scene Understanding
Mar 16, 2026Visual Language Models (VLMs) have increasingly become the main paradigm for understanding indoor scenes, but they still struggle with metric and spatial reasoning. Current approaches rely on end-to-end video understanding or large-scale spatial question answering fine-tuning, inherently coupling perception and reasoning. In this paper, we investigate whether decoupling perception and reasoning leads to improved spatial reasoning. We propose an agentic framework for static 3D indoor scene reasoning that grounds an LLM in an explicit 3D scene graph (3DSG). Rather than ingesting videos directly, each scene is represented as a persistent 3DSG constructed by a dedicated perception module. To isolate reasoning performance, we instantiate the 3DSG from ground-truth annotations. The agent interacts with the scene exclusively through structured geometric tools that expose fundamental properties such as object dimensions, distances, poses, and spatial relationships. The results we obtain on the static split of VSI-Bench provide an upper bound under ideal perceptual conditions on the spatial reasoning performance, and we find that it is significantly higher than previous works, by up to 16\%, without task specific fine-tuning. Compared to base VLMs, our agentic variant achieves significantly better performance, with average improvements between 33\% to 50\%. These findings indicate that explicit geometric grounding substantially improves spatial reasoning performance, and suggest that structured representations offer a compelling alternative to purely end-to-end visual reasoning.
GeodesicNVS: Probability Density Geodesic Flow Matching for Novel View Synthesis
Mar 01, 2026Recent advances in generative modeling have substantially enhanced novel view synthesis, yet maintaining consistency across viewpoints remains challenging. Diffusion-based models rely on stochastic noise-to-data transitions, which obscure deterministic structures and yield inconsistent view predictions. We propose a Data-to-Data Flow Matching framework that learns deterministic transformations directly between paired views, enhancing view-consistent synthesis through explicit data coupling. To further enhance geometric coherence, we introduce Probability Density Geodesic Flow Matching (PDG-FM), which constrains flow trajectories using geodesic interpolants derived from probability density metrics of pretrained diffusion models. Such alignment with high-density regions of the data manifold promotes more realistic interpolants between samples. Empirically, our method surpasses diffusion-based NVS baselines, demonstrating improved structural coherence and smoother transitions across views. These results highlight the advantages of incorporating data-dependent geometric regularization into deterministic flow matching for consistent novel view generation.
HierLoc: Hyperbolic Entity Embeddings for Hierarchical Visual Geolocation
Jan 30, 2026Visual geolocalization, the task of predicting where an image was taken, remains challenging due to global scale, visual ambiguity, and the inherently hierarchical structure of geography. Existing paradigms rely on either large-scale retrieval, which requires storing a large number of image embeddings, grid-based classifiers that ignore geographic continuity, or generative models that diffuse over space but struggle with fine detail. We introduce an entity-centric formulation of geolocation that replaces image-to-image retrieval with a compact hierarchy of geographic entities embedded in Hyperbolic space. Images are aligned directly to country, region, subregion, and city entities through Geo-Weighted Hyperbolic contrastive learning by directly incorporating haversine distance into the contrastive objective. This hierarchical design enables interpretable predictions and efficient inference with 240k entity embeddings instead of over 5 million image embeddings on the OSV5M benchmark, on which our method establishes a new state-of-the-art performance. Compared to the current methods in the literature, it reduces mean geodesic error by 19.5\%, while improving the fine-grained subregion accuracy by 43%. These results demonstrate that geometry-aware hierarchical embeddings provide a scalable and conceptually new alternative for global image geolocation.
GeoSceneGraph: Geometric Scene Graph Diffusion Model for Text-guided 3D Indoor Scene Synthesis
Nov 18, 2025Methods that synthesize indoor 3D scenes from text prompts have wide-ranging applications in film production, interior design, video games, virtual reality, and synthetic data generation for training embodied agents. Existing approaches typically either train generative models from scratch or leverage vision-language models (VLMs). While VLMs achieve strong performance, particularly for complex or open-ended prompts, smaller task-specific models remain necessary for deployment on resource-constrained devices such as extended reality (XR) glasses or mobile phones. However, many generative approaches that train from scratch overlook the inherent graph structure of indoor scenes, which can limit scene coherence and realism. Conversely, methods that incorporate scene graphs either demand a user-provided semantic graph, which is generally inconvenient and restrictive, or rely on ground-truth relationship annotations, limiting their capacity to capture more varied object interactions. To address these challenges, we introduce GeoSceneGraph, a method that synthesizes 3D scenes from text prompts by leveraging the graph structure and geometric symmetries of 3D scenes, without relying on predefined relationship classes. Despite not using ground-truth relationships, GeoSceneGraph achieves performance comparable to methods that do. Our model is built on equivariant graph neural networks (EGNNs), but existing EGNN approaches are typically limited to low-dimensional conditioning and are not designed to handle complex modalities such as text. We propose a simple and effective strategy for conditioning EGNNs on text features, and we validate our design through ablation studies.
LADB: Latent Aligned Diffusion Bridges for Semi-Supervised Domain Translation
Sep 10, 2025Diffusion models excel at generating high-quality outputs but face challenges in data-scarce domains, where exhaustive retraining or costly paired data are often required. To address these limitations, we propose Latent Aligned Diffusion Bridges (LADB), a semi-supervised framework for sample-to-sample translation that effectively bridges domain gaps using partially paired data. By aligning source and target distributions within a shared latent space, LADB seamlessly integrates pretrained source-domain diffusion models with a target-domain Latent Aligned Diffusion Model (LADM), trained on partially paired latent representations. This approach enables deterministic domain mapping without the need for full supervision. Compared to unpaired methods, which often lack controllability, and fully paired approaches that require large, domain-specific datasets, LADB strikes a balance between fidelity and diversity by leveraging a mixture of paired and unpaired latent-target couplings. Our experimental results demonstrate superior performance in depth-to-image translation under partial supervision. Furthermore, we extend LADB to handle multi-source translation (from depth maps and segmentation masks) and multi-target translation in a class-conditioned style transfer task, showcasing its versatility in handling diverse and heterogeneous use cases. Ultimately, we present LADB as a scalable and versatile solution for real-world domain translation, particularly in scenarios where data annotation is costly or incomplete.
Learning Dual-Arm Coordination for Grasping Large Flat Objects
Apr 04, 2025



Grasping large flat objects, such as books or keyboards lying horizontally, presents significant challenges for single-arm robotic systems, often requiring extra actions like pushing objects against walls or moving them to the edge of a surface to facilitate grasping. In contrast, dual-arm manipulation, inspired by human dexterity, offers a more refined solution by directly coordinating both arms to lift and grasp the object without the need for complex repositioning. In this paper, we propose a model-free deep reinforcement learning (DRL) framework to enable dual-arm coordination for grasping large flat objects. We utilize a large-scale grasp pose detection model as a backbone to extract high-dimensional features from input images, which are then used as the state representation in a reinforcement learning (RL) model. A CNN-based Proximal Policy Optimization (PPO) algorithm with shared Actor-Critic layers is employed to learn coordinated dual-arm grasp actions. The system is trained and tested in Isaac Gym and deployed to real robots. Experimental results demonstrate that our policy can effectively grasp large flat objects without requiring additional maneuvers. Furthermore, the policy exhibits strong generalization capabilities, successfully handling unseen objects. Importantly, it can be directly transferred to real robots without fine-tuning, consistently outperforming baseline methods.
Stick to Facts: Towards Fidelity-oriented Product Description Generation
Mar 12, 2025Different from other text generation tasks, in product description generation, it is of vital importance to generate faithful descriptions that stick to the product attribute information. However, little attention has been paid to this problem. To bridge this gap, we propose a model named Fidelity-oriented Product Description Generator (FPDG). FPDG takes the entity label of each word into account, since the product attribute information is always conveyed by entity words. Specifically, we first propose a Recurrent Neural Network (RNN) decoder based on the Entity-label-guided Long Short-Term Memory (ELSTM) cell, taking both the embedding and the entity label of each word as input. Second, we establish a keyword memory that stores the entity labels as keys and keywords as values, allowing FPDG to attend to keywords by attending to their entity labels. Experiments conducted on a large-scale real-world product description dataset show that our model achieves state-of-the-art performance in terms of both traditional generation metrics and human evaluations. Specifically, FPDG increases the fidelity of the generated descriptions by 25%.
Learning Dual-Arm Push and Grasp Synergy in Dense Clutter
Dec 05, 2024



Robotic grasping in densely cluttered environments is challenging due to scarce collision-free grasp affordances. Non-prehensile actions can increase feasible grasps in cluttered environments, but most research focuses on single-arm rather than dual-arm manipulation. Policies from single-arm systems fail to fully leverage the advantages of dual-arm coordination. We propose a target-oriented hierarchical deep reinforcement learning (DRL) framework that learns dual-arm push-grasp synergy for grasping objects to enhance dexterous manipulation in dense clutter. Our framework maps visual observations to actions via a pre-trained deep learning backbone and a novel CNN-based DRL model, trained with Proximal Policy Optimization (PPO), to develop a dual-arm push-grasp strategy. The backbone enhances feature mapping in densely cluttered environments. A novel fuzzy-based reward function is introduced to accelerate efficient strategy learning. Our system is developed and trained in Isaac Gym and then tested in simulations and on a real robot. Experimental results show that our framework effectively maps visual data to dual push-grasp motions, enabling the dual-arm system to grasp target objects in complex environments. Compared to other methods, our approach generates 6-DoF grasp candidates and enables dual-arm push actions, mimicking human behavior. Results show that our method efficiently completes tasks in densely cluttered environments. https://sites.google.com/view/pg4da/home
BezierFormer: A Unified Architecture for 2D and 3D Lane Detection
Apr 25, 2024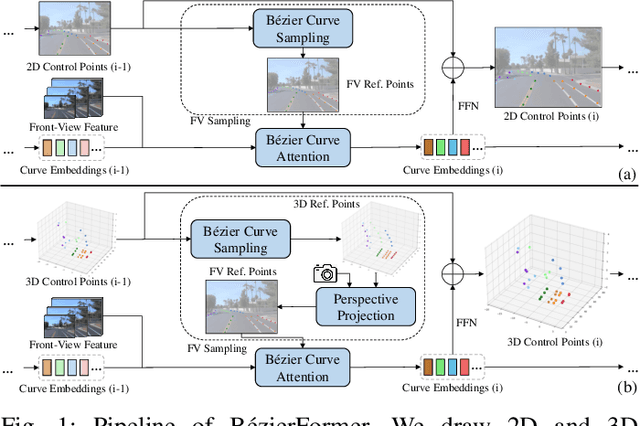
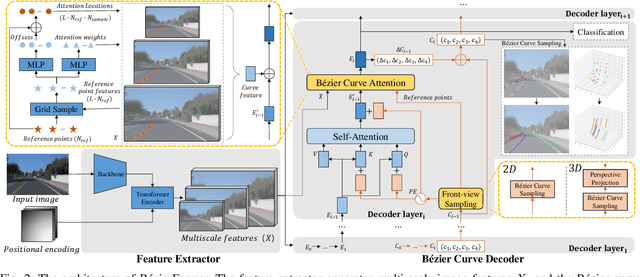
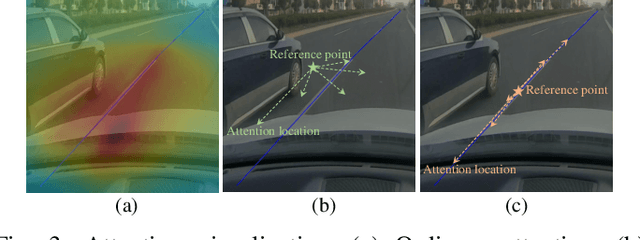

Lane detection has made significant progress in recent years, but there is not a unified architecture for its two sub-tasks: 2D lane detection and 3D lane detection. To fill this gap, we introduce B\'{e}zierFormer, a unified 2D and 3D lane detection architecture based on B\'{e}zier curve lane representation. B\'{e}zierFormer formulate queries as B\'{e}zier control points and incorporate a novel B\'{e}zier curve attention mechanism. This attention mechanism enables comprehensive and accurate feature extraction for slender lane curves via sampling and fusing multiple reference points on each curve. In addition, we propose a novel Chamfer IoU-based loss which is more suitable for the B\'{e}zier control points regression. The state-of-the-art performance of B\'{e}zierFormer on widely-used 2D and 3D lane detection benchmarks verifies its effectiveness and suggests the worthiness of further exploration.