 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoSceneGraph: Geometric Scene Graph Diffusion Model for Text-guided 3D Indoor Scene Synthesis
Nov 18, 2025Methods that synthesize indoor 3D scenes from text prompts have wide-ranging applications in film production, interior design, video games, virtual reality, and synthetic data generation for training embodied agents. Existing approaches typically either train generative models from scratch or leverage vision-language models (VLMs). While VLMs achieve strong performance, particularly for complex or open-ended prompts, smaller task-specific models remain necessary for deployment on resource-constrained devices such as extended reality (XR) glasses or mobile phones. However, many generative approaches that train from scratch overlook the inherent graph structure of indoor scenes, which can limit scene coherence and realism. Conversely, methods that incorporate scene graphs either demand a user-provided semantic graph, which is generally inconvenient and restrictive, or rely on ground-truth relationship annotations, limiting their capacity to capture more varied object interactions. To address these challenges, we introduce GeoSceneGraph, a method that synthesizes 3D scenes from text prompts by leveraging the graph structure and geometric symmetries of 3D scenes, without relying on predefined relationship classes. Despite not using ground-truth relationships, GeoSceneGraph achieves performance comparable to methods that do. Our model is built on equivariant graph neural networks (EGNNs), but existing EGNN approaches are typically limited to low-dimensional conditioning and are not designed to handle complex modalities such as text. We propose a simple and effective strategy for conditioning EGNNs on text features, and we validate our design through ablation studies.
Motion Analysis of Upper Limb and Hand in a Haptic Rotation Task
Nov 17, 2024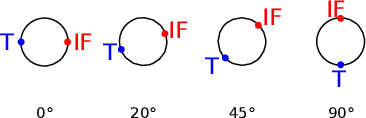
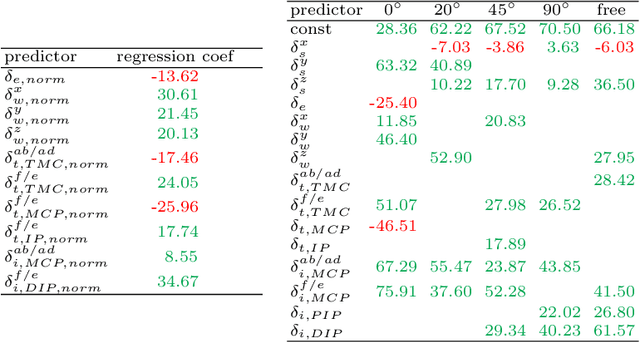
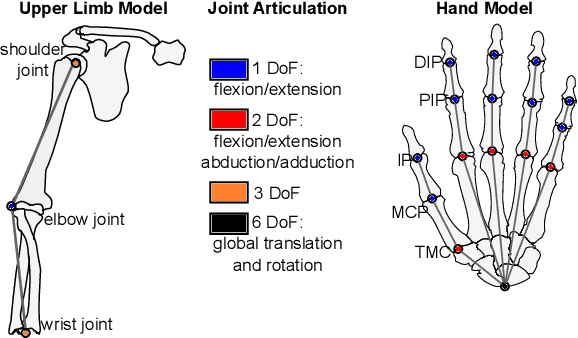
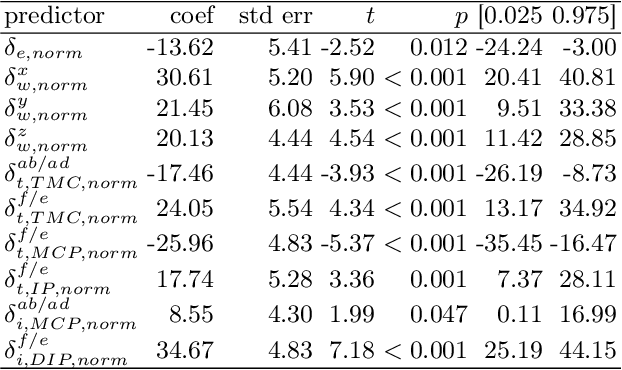
Humans seem to have a bias to overshoot when rotating a rotary knob blindfolded around a specified target angle (i.e. during haptic rotation). Whereas some influence factors that strengthen or weaken such an effect are already known, the underlying reasons for the overshoot are still unknown. This work approaches the topic of haptic rotations by analyzing a detailed recording of the movement. We propose an experimental framework and an approach to investigate which upper limb and hand joint movements contribute significantly to a haptic rotation task and to the angle overshoot based on the acquired data. With stepwise regression with backward elimination, we analyze a rotation around 90 degrees counterclockwise with two fingers under different grasping orientations. Our results showed that the wrist joint, the sideways finger movement in the proximal joints, and the distal finger joints contributed significantly to overshooting. This suggests that two phenomena are behind the overshooting: 1) The significant contribution of the wrist joint indicates a bias of a hand-centered egocentric reference frame. 2) Significant contribution of the finger joints indicates a rolling of the fingertips over the rotary knob surface and, thus, a change of contact point for which probably the human does not compensate.
Adaptive Kinematic Modeling for Improved Hand Posture Estimates Using a Haptic Glove
Nov 10, 2024



Most commercially available haptic gloves compromise the accuracy of hand-posture measurements in favor of a simpler design with fewer sensors. While inaccurate posture data is often sufficient for the task at hand in biomedical settings such as VR-therapy-aided rehabilitation, measurements should be as precise as possible to digitally recreate hand postures as accurately as possible. With these applications in mind, we have added extra sensors to the commercially available Dexmo haptic glove by Dexta Robotics and applied kinematic models of the haptic glove and the user's hand to improve the accuracy of hand-posture measurements. In this work, we describe the augmentations and the kinematic modeling approach. Additionally, we present and discuss an evaluation of hand posture measurements as a proof of concept.
Generating Piano Practice Policy with a Gaussian Process
Jun 07, 2024

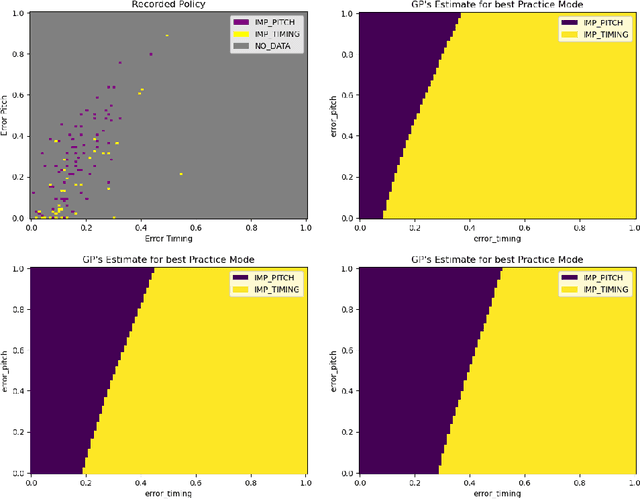
A typical process of learning to play a piece on a piano consists of a progression through a series of practice units that focus on individual dimensions of the skill, the so-called practice modes. Practice modes in learning to play music comprise a particularly large set of possibilities, such as hand coordination, posture, articulation, ability to read a music score, correct timing or pitch, etc. Self-guided practice is known to be suboptimal, and a model that schedules optimal practice to maximize a learner's progress still does not exist. Because we each learn differently and there are many choices for possible piano practice tasks and methods, the set of practice modes should be dynamically adapted to the human learner, a process typically guided by a teacher. However, having a human teacher guide individual practice is not always feasible since it is time-consuming, expensive, and often unavailable. In this work, we present a modeling framework to guide the human learner through the learning process by choosing the practice modes generated by a policy model. To this end, we present a computational architecture building on a Gaussian process that incorporates 1) the learner state, 2) a policy that selects a suitable practice mode, 3) performance evaluation, and 4) expert knowledge. The proposed policy model is trained to approximate the expert-learner interaction during a practice session. In our future work, we will test different Bayesian optimization techniques, e.g., different acquisition functions, and evaluate their effect on the learning progress.
Video Diffusion Models: A Survey
May 06, 2024
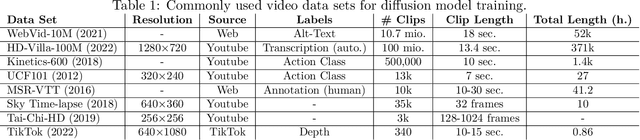
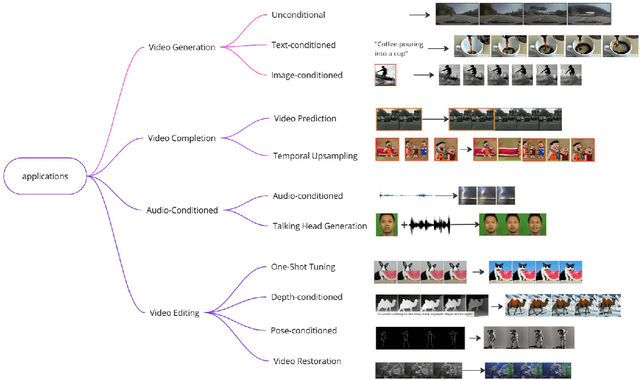

Diffusion generative models have recently become a robust technique for producing and modifying coherent, high-quality video. This survey offers a systematic overview of critical elements of diffusion models for video generation, covering applications, architectural choices, and the modeling of temporal dynamics. Recent advancements in the field are summarized and grouped into development trends. The survey concludes with an overview of remaining challenges and an outlook on the future of the field. Website: https://github.com/ndrwmlnk/Awesome-Video-Diffusion-Models
Lane Segmentation Refinement with Diffusion Models
May 01, 2024



The lane graph is a key component for building high-definition (HD) maps and crucial for downstream tasks such as autonomous driving or navigation planning. Previously, He et al. (2022) explored the extraction of the lane-level graph from aerial imagery utilizing a segmentation based approach. However, segmentation networks struggle to achieve perfect segmentation masks resulting in inaccurate lane graph extraction. We explore additional enhancements to refine this segmentation-based approach and extend it with a diffusion probabilistic model (DPM) component. This combination further improves the GEO F1 and TOPO F1 scores, which are crucial indicators of the quality of a lane graph, in the undirected graph in non-intersection areas. We conduct experiments on a publicly available dataset, demonstrating that our method outperforms the previous approach, particularly in enhancing the connectivity of such a graph, as measured by the TOPO F1 score. Moreover, we perform ablation studies on the individual components of our method to understand their contribution and evaluate their effectiveness.
Benchmarks for Physical Reasoning AI
Dec 17, 2023



Physical reasoning is a crucial aspect in the development of general AI systems, given that human learning starts with interacting with the physical world before progressing to more complex concepts. Although researchers have studied and assessed the physical reasoning of AI approaches through various specific benchmarks, there is no comprehensive approach to evaluating and measuring progress. Therefore, we aim to offer an overview of existing benchmarks and their solution approaches and propose a unified perspective for measuring the physical reasoning capacity of AI systems. We select benchmarks that are designed to test algorithmic performance in physical reasoning tasks. While each of the selected benchmarks poses a unique challenge, their ensemble provides a comprehensive proving ground for an AI generalist agent with a measurable skill level for various physical reasoning concepts. This gives an advantage to such an ensemble of benchmarks over other holistic benchmarks that aim to simulate the real world by intertwining its complexity and many concepts. We group the presented set of physical reasoning benchmarks into subcategories so that more narrow generalist AI agents can be tested first on these groups.
Bio-Inspired Grasping Controller for Sensorized 2-DoF Grippers
Nov 13, 2023We present a holistic grasping controller, combining free-space position control and in-contact force-control for reliable grasping given uncertain object pose estimates. Employing tactile fingertip sensors, undesired object displacement during grasping is minimized by pausing the finger closing motion for individual joints on first contact until force-closure is established. While holding an object, the controller is compliant with external forces to avoid high internal object forces and prevent object damage. Gravity as an external force is explicitly considered and compensated for, thus preventing gravity-induced object drift. We evaluate the controller in two experiments on the TIAGo robot and its parallel-jaw gripper proving the effectiveness of the approach for robust grasping and minimizing object displacement. In a series of ablation studies, we demonstrate the utility of the individual controller components.
Towards Transferring Tactile-based Continuous Force Control Policies from Simulation to Robot
Nov 13, 2023



The advent of tactile sensors in robotics has sparked many ideas on how robots can leverage direct contact measurements of their environment interactions to improve manipulation tasks. An important line of research in this regard is that of grasp force control, which aims to manipulate objects safely by limiting the amount of force exerted on the object. While prior works have either hand-modeled their force controllers, employed model-based approaches, or have not shown sim-to-real transfer, we propose a model-free deep reinforcement learning approach trained in simulation and then transferred to the robot without further fine-tuning. We therefore present a simulation environment that produces realistic normal forces, which we use to train continuous force control policies. An evaluation in which we compare against a baseline and perform an ablation study shows that our approach outperforms the hand-modeled baseline and that our proposed inductive bias and domain randomization facilitate sim-to-real transfer. Code, models, and supplementary videos are available on https://sites.google.com/view/rl-force-ctrl
Shape complexity estimation using VAE
Apr 05, 2023



In this paper, we compare methods for estimating the complexity of two-dimensional shapes and introduce a method that exploits reconstruction loss of Variational Autoencoders with different sizes of latent vectors. Although complexity of a shape is not a well defined attribute, different aspects of it can be estimated. We demonstrate that our methods captures some aspects of shape complexity. Code and training details will be publicly available.