 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScore Augmentation for Diffusion Models
Aug 11, 2025Diffusion models have achieved remarkable success in generative modeling. However, this study confirms the existence of overfitting in diffusion model training, particularly in data-limited regimes. To address this challenge, we propose Score Augmentation (ScoreAug), a novel data augmentation framework specifically designed for diffusion models. Unlike conventional augmentation approaches that operate on clean data, ScoreAug applies transformations to noisy data, aligning with the inherent denoising mechanism of diffusion. Crucially, ScoreAug further requires the denoiser to predict the augmentation of the original target. This design establishes an equivariant learning objective, enabling the denoiser to learn scores across varied denoising spaces, thereby realizing what we term score augmentation. We also theoretically analyze the relationship between scores in different spaces under general transformations. In experiments, we extensively validate ScoreAug on multiple benchmarks including CIFAR-10, FFHQ, AFHQv2, and ImageNet, with results demonstrating significant performance improvements over baselines. Notably, ScoreAug effectively mitigates overfitting across diverse scenarios, such as varying data scales and model capacities, while exhibiting stable convergence properties. Another advantage of ScoreAug over standard data augmentation lies in its ability to circumvent data leakage issues under certain conditions. Furthermore, we show that ScoreAug can be synergistically combined with traditional data augmentation techniques to achieve additional performance gains.
TrajFlow: Multi-modal Motion Prediction via Flow Matching
Jun 10, 2025Efficient and accurate motion prediction is crucial for ensuring safety and informed decision-making in autonomous driving, particularly under dynamic real-world conditions that necessitate multi-modal forecasts. We introduce TrajFlow, a novel flow matching-based motion prediction framework that addresses the scalability and efficiency challenges of existing generative trajectory prediction methods. Unlike conventional generative approaches that employ i.i.d. sampling and require multiple inference passes to capture diverse outcomes, TrajFlow predicts multiple plausible future trajectories in a single pass, significantly reducing computational overhead while maintaining coherence across predictions. Moreover, we propose a ranking loss based on the Plackett-Luce distribution to improve uncertainty estimation of predicted trajectories. Additionally, we design a self-conditioning training technique that reuses the model's own predictions to construct noisy inputs during a second forward pass, thereby improving generalization and accelerating inference. Extensive experiments on the large-scale Waymo Open Motion Dataset (WOMD) demonstrate that TrajFlow achieves state-of-the-art performance across various key metrics, underscoring its effectiveness for safety-critical autonomous driving applications. The code and other details are available on the project website https://traj-flow.github.io/.
StreamSplat: Towards Online Dynamic 3D Reconstruction from Uncalibrated Video Streams
Jun 10, 2025Real-time reconstruction of dynamic 3D scenes from uncalibrated video streams is crucial for numerous real-world applications. However, existing methods struggle to jointly address three key challenges: 1) processing uncalibrated inputs in real time, 2) accurately modeling dynamic scene evolution, and 3) maintaining long-term stability and computational efficiency. To this end, we introduce StreamSplat, the first fully feed-forward framework that transforms uncalibrated video streams of arbitrary length into dynamic 3D Gaussian Splatting (3DGS) representations in an online manner, capable of recovering scene dynamics from temporally local observations. We propose two key technical innovations: a probabilistic sampling mechanism in the static encoder for 3DGS position prediction, and a bidirectional deformation field in the dynamic decoder that enables robust and efficient dynamic modeling. Extensive experiments on static and dynamic benchmarks demonstrate that StreamSplat consistently outperforms prior works in both reconstruction quality and dynamic scene modeling, while uniquely supporting online reconstruction of arbitrarily long video streams. Code and models are available at https://github.com/nickwzk/StreamSplat.
Neural MJD: Neural Non-Stationary Merton Jump Diffusion for Time Series Prediction
Jun 05, 2025While deep learning methods have achieved strong performance in time series prediction, their black-box nature and inability to explicitly model underlying stochastic processes often limit their generalization to non-stationary data, especially in the presence of abrupt changes. In this work, we introduce Neural MJD, a neural network based non-stationary Merton jump diffusion (MJD) model. Our model explicitly formulates forecasting as a stochastic differential equation (SDE) simulation problem, combining a time-inhomogeneous It\^o diffusion to capture non-stationary stochastic dynamics with a time-inhomogeneous compound Poisson process to model abrupt jumps. To enable tractable learning, we introduce a likelihood truncation mechanism that caps the number of jumps within small time intervals and provide a theoretical error bound for this approximation. Additionally, we propose an Euler-Maruyama with restart solver, which achieves a provably lower error bound in estimating expected states and reduced variance compared to the standard solver. Experiments on both synthetic and real-world datasets demonstrate that Neural MJD consistently outperforms state-of-the-art deep learning and statistical learning methods.
RETRO SYNFLOW: Discrete Flow Matching for Accurate and Diverse Single-Step Retrosynthesis
Jun 04, 2025A fundamental problem in organic chemistry is identifying and predicting the series of reactions that synthesize a desired target product molecule. Due to the combinatorial nature of the chemical search space, single-step reactant prediction -- i.e. single-step retrosynthesis -- remains challenging even for existing state-of-the-art template-free generative approaches to produce an accurate yet diverse set of feasible reactions. In this paper, we model single-step retrosynthesis planning and introduce RETRO SYNFLOW (RSF) a discrete flow-matching framework that builds a Markov bridge between the prescribed target product molecule and the reactant molecule. In contrast to past approaches, RSF employs a reaction center identification step to produce intermediate structures known as synthons as a more informative source distribution for the discrete flow. To further enhance diversity and feasibility of generated samples, we employ Feynman-Kac steering with Sequential Monte Carlo based resampling to steer promising generations at inference using a new reward oracle that relies on a forward-synthesis model. Empirically, we demonstrate \nameshort achieves $60.0 \%$ top-1 accuracy, which outperforms the previous SOTA by $20 \%$. We also substantiate the benefits of steering at inference and demonstrate that FK-steering improves top-$5$ round-trip accuracy by $19 \%$ over prior template-free SOTA methods, all while preserving competitive top-$k$ accuracy results.
MoFlow: One-Step Flow Matching for Human Trajectory Forecasting via Implicit Maximum Likelihood Estimation based Distillation
Mar 13, 2025In this paper, we address the problem of human trajectory forecasting, which aims to predict the inherently multi-modal future movements of humans based on their past trajectories and other contextual cues. We propose a novel motion prediction conditional flow matching model, termed MoFlow, to predict K-shot future trajectories for all agents in a given scene. We design a novel flow matching loss function that not only ensures at least one of the $K$ sets of future trajectories is accurate but also encourages all $K$ sets of future trajectories to be diverse and plausible. Furthermore, by leveraging the implicit maximum likelihood estimation (IMLE), we propose a novel distillation method for flow models that only requires samples from the teacher model. Extensive experiments on the real-world datasets, including SportVU NBA games, ETH-UCY, and SDD, demonstrate that both our teacher flow model and the IMLE-distilled student model achieve state-of-the-art performance. These models can generate diverse trajectories that are physically and socially plausible. Moreover, our one-step student model is $\textbf{100}$ times faster than the teacher flow model during sampling. The code, model, and data are available at our project page: https://moflow-imle.github.io
Coordinated Spectral Efficiency Prediction for Real-World 5G CoMP Systems
Aug 14, 2024Coordinated multipoint (CoMP) systems incur substantial resource consumption due to the management of backhaul links and the coordination among various base stations (BSs). Accurate prediction of coordinated spectral efficiency (CSE) can guide the optimization of network parameters, resulting in enhanced resource utilization efficiency. However, characterizing the CSE is intractable due to the inherent complexity of the CoMP channel model and the diversity of the 5G dynamic network environment, which poses a great challenge for CSE prediction in real-world 5G CoMP systems. To address this challenge, in this letter, we propose a data-driven model-assisted approach. Initially, we leverage domain knowledge to preprocess the collected raw data, thereby creating a well-informed dataset. Within this dataset, we explicitly define the target variable and the input feature space relevant to channel statistics for CSE prediction. Subsequently, a residual-based network model is built to capture the high-dimensional non-linear mapping function from the channel statistics to the CSE. The effectiveness of the proposed approach is validated by experimental results on real-world data.
Fréchet Video Motion Distance: A Metric for Evaluating Motion Consistency in Videos
Jul 23, 2024
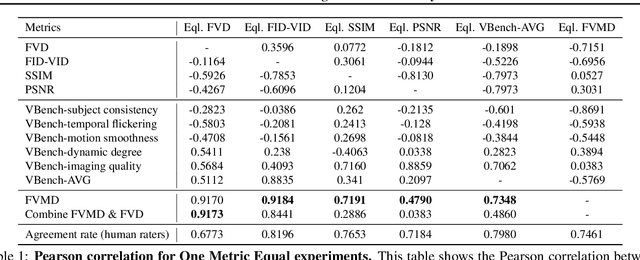
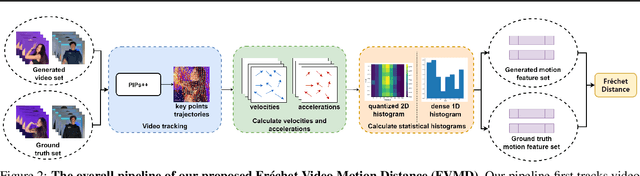
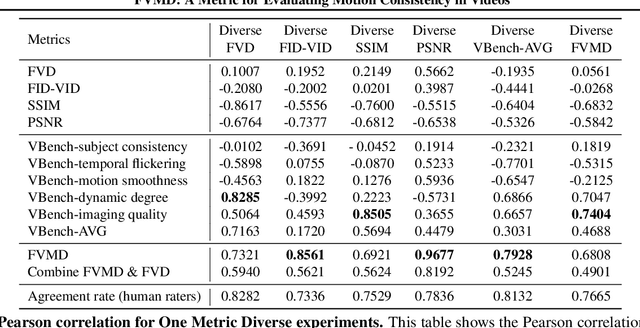
Significant advancements have been made in video generative models recently. Unlike image generation, video generation presents greater challenges, requiring not only generating high-quality frames but also ensuring temporal consistency across these frames. Despite the impressive progress, research on metrics for evaluating the quality of generated videos, especially concerning temporal and motion consistency, remains underexplored. To bridge this research gap, we propose Fr\'echet Video Motion Distance (FVMD) metric, which focuses on evaluating motion consistency in video generation. Specifically, we design explicit motion features based on key point tracking, and then measure the similarity between these features via the Fr\'echet distance. We conduct sensitivity analysis by injecting noise into real videos to verify the effectiveness of FVMD. Further, we carry out a large-scale human study, demonstrating that our metric effectively detects temporal noise and aligns better with human perceptions of generated video quality than existing metrics. Additionally, our motion features can consistently improve the performance of Video Quality Assessment (VQA) models, indicating that our approach is also applicable to unary video quality evaluation. Code is available at https://github.com/ljh0v0/FMD-frechet-motion-distance.
4DHands: Reconstructing Interactive Hands in 4D with Transformers
May 31, 2024In this paper, we introduce 4DHands, a robust approach to recovering interactive hand meshes and their relative movement from monocular inputs. Our approach addresses two major limitations of previous methods: lacking a unified solution for handling various hand image inputs and neglecting the positional relationship of two hands within images. To overcome these challenges, we develop a transformer-based architecture with novel tokenization and feature fusion strategies. Specifically, we propose a Relation-aware Two-Hand Tokenization (RAT) method to embed positional relation information into the hand tokens. In this way, our network can handle both single-hand and two-hand inputs and explicitly leverage relative hand positions, facilitating the reconstruction of intricate hand interactions in real-world scenarios. As such tokenization indicates the relative relationship of two hands, it also supports more effective feature fusion. To this end, we further develop a Spatio-temporal Interaction Reasoning (SIR) module to fuse hand tokens in 4D with attention and decode them into 3D hand meshes and relative temporal movements. The efficacy of our approach is validated on several benchmark datasets. The results on in-the-wild videos and real-world scenarios demonstrate the superior performances of our approach for interactive hand reconstruction. More video results can be found on the project page: https://4dhands.github.io.
Harnessing the power of longitudinal medical imaging for eye disease prognosis using Transformer-based sequence modeling
May 14, 2024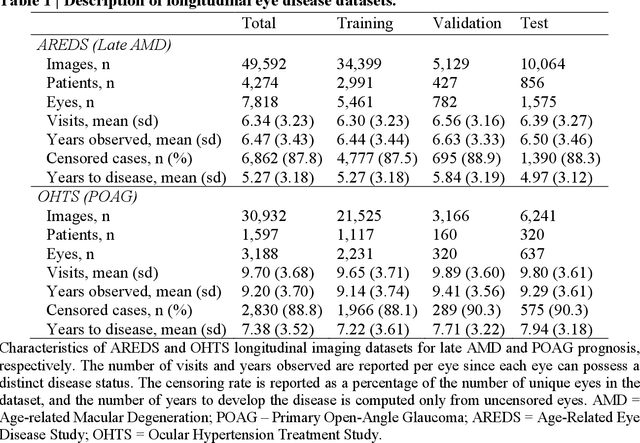
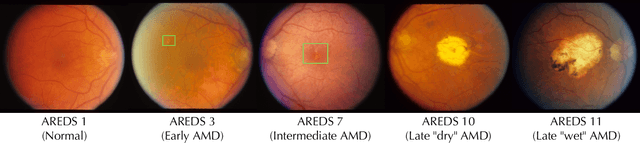
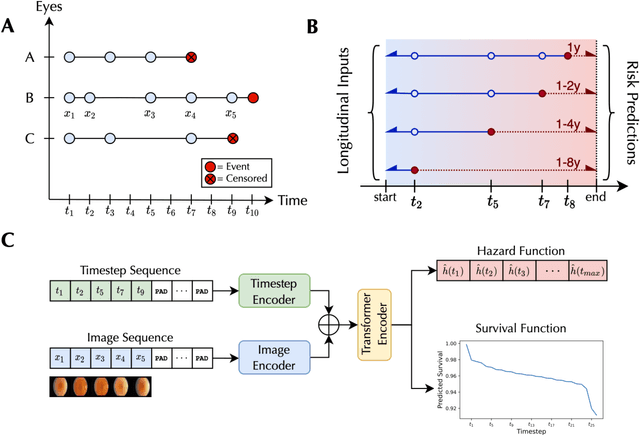
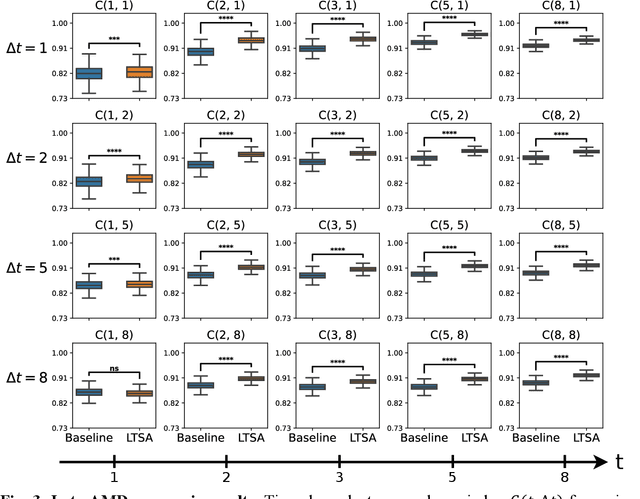
Deep learning has enabled breakthroughs in automated diagnosis from medical imaging, with many successful applications in ophthalmology. However, standard medical image classification approaches only assess disease presence at the time of acquisition, neglecting the common clinical setting of longitudinal imaging. For slow, progressive eye diseases like age-related macular degeneration (AMD) and primary open-angle glaucoma (POAG), patients undergo repeated imaging over time to track disease progression and forecasting the future risk of developing disease is critical to properly plan treatment. Our proposed Longitudinal Transformer for Survival Analysis (LTSA) enables dynamic disease prognosis from longitudinal medical imaging, modeling the time to disease from sequences of fundus photography images captured over long, irregular time periods. Using longitudinal imaging data from the Age-Related Eye Disease Study (AREDS) and Ocular Hypertension Treatment Study (OHTS), LTSA significantly outperformed a single-image baseline in 19/20 head-to-head comparisons on late AMD prognosis and 18/20 comparisons on POAG prognosis. A temporal attention analysis also suggested that, while the most recent image is typically the most influential, prior imaging still provides additional prognostic value.