 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpert-Data Alignment Governs Generation Quality in Decentralized Diffusion Models
Feb 02, 2026Decentralized Diffusion Models (DDMs) route denoising through experts trained independently on disjoint data clusters, which can strongly disagree in their predictions. What governs the quality of generations in such systems? We present the first ever systematic investigation of this question. A priori, the expectation is that minimizing denoising trajectory sensitivity -- minimizing how perturbations amplify during sampling -- should govern generation quality. We demonstrate this hypothesis is incorrect: a stability-quality dissociation. Full ensemble routing, which combines all expert predictions at each step, achieves the most stable sampling dynamics and best numerical convergence while producing the worst generation quality (FID 47.9 vs. 22.6 for sparse Top-2 routing). Instead, we identify expert-data alignment as the governing principle: generation quality depends on routing inputs to experts whose training distribution covers the current denoising state. Across two distinct DDM systems, we validate expert-data alignment using (i) data-cluster distance analysis, confirming sparse routing selects experts with data clusters closest to the current denoising state, and (ii) per-expert analysis, showing selected experts produce more accurate predictions than non-selected ones, and (iii) expert disagreement analysis, showing quality degrades when experts disagree. For DDM deployment, our findings establish that routing should prioritize expert-data alignment over numerical stability metrics.
Contextual bandits with entropy-based human feedback
Feb 12, 2025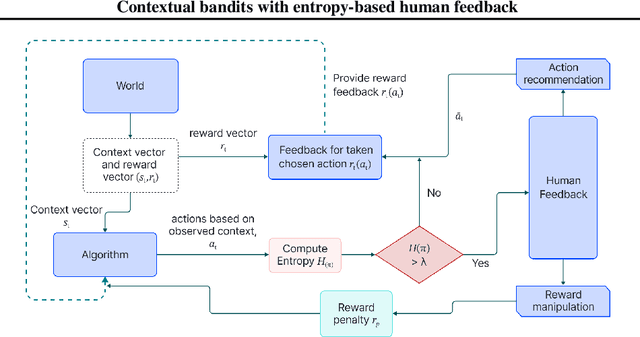
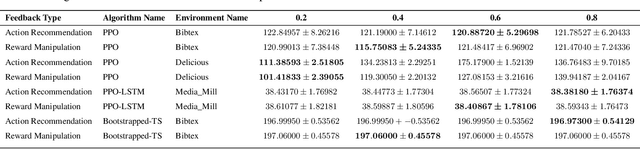
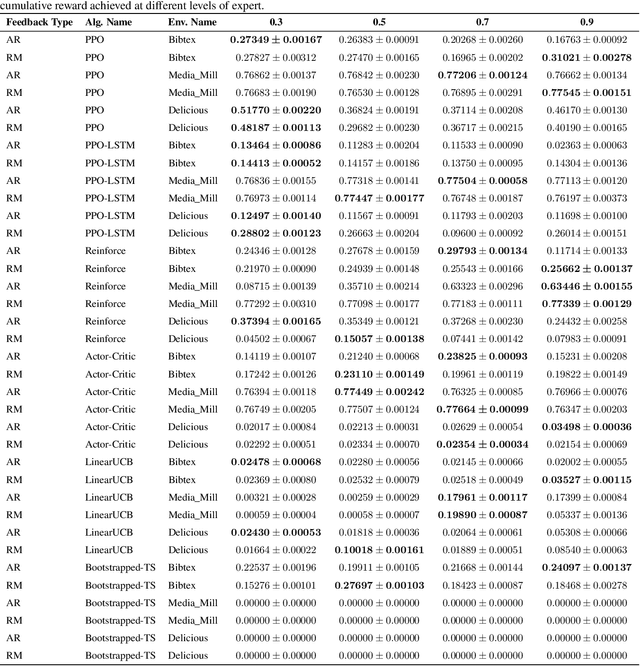
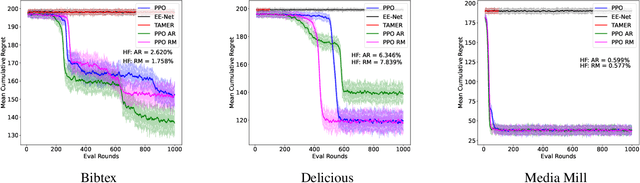
In recent years, preference-based human feedback mechanisms have become essential for enhancing model performance across diverse applications, including conversational AI systems such as ChatGPT. However, existing approaches often neglect critical aspects, such as model uncertainty and the variability in feedback quality. To address these challenges, we introduce an entropy-based human feedback framework for contextual bandits, which dynamically balances exploration and exploitation by soliciting expert feedback only when model entropy exceeds a predefined threshold. Our method is model-agnostic and can be seamlessly integrated with any contextual bandit agent employing stochastic policies. Through comprehensive experiments, we show that our approach achieves significant performance improvements while requiring minimal human feedback, even under conditions of suboptimal feedback quality. This work not only presents a novel strategy for feedback solicitation but also highlights the robustness and efficacy of incorporating human guidance into machine learning systems. Our code is publicly available: https://github.com/BorealisAI/CBHF
Generalizing Multi-Step Inverse Models for Representation Learning to Finite-Memory POMDPs
Apr 22, 2024Discovering an informative, or agent-centric, state representation that encodes only the relevant information while discarding the irrelevant is a key challenge towards scaling reinforcement learning algorithms and efficiently applying them to downstream tasks. Prior works studied this problem in high-dimensional Markovian environments, when the current observation may be a complex object but is sufficient to decode the informative state. In this work, we consider the problem of discovering the agent-centric state in the more challenging high-dimensional non-Markovian setting, when the state can be decoded from a sequence of past observations. We establish that generalized inverse models can be adapted for learning agent-centric state representation for this task. Our results include asymptotic theory in the deterministic dynamics setting as well as counter-examples for alternative intuitive algorithms. We complement these findings with a thorough empirical study on the agent-centric state discovery abilities of the different alternatives we put forward. Particularly notable is our analysis of past actions, where we show that these can be a double-edged sword: making the algorithms more successful when used correctly and causing dramatic failure when used incorrectly.
PcLast: Discovering Plannable Continuous Latent States
Nov 06, 2023



Goal-conditioned planning benefits from learned low-dimensional representations of rich, high-dimensional observations. While compact latent representations, typically learned from variational autoencoders or inverse dynamics, enable goal-conditioned planning they ignore state affordances, thus hampering their sample-efficient planning capabilities. In this paper, we learn a representation that associates reachable states together for effective onward planning. We first learn a latent representation with multi-step inverse dynamics (to remove distracting information); and then transform this representation to associate reachable states together in $\ell_2$ space. Our proposals are rigorously tested in various simulation testbeds. Numerical results in reward-based and reward-free settings show significant improvements in sampling efficiency, and yields layered state abstractions that enable computationally efficient hierarchical planning.
AutoCast++: Enhancing World Event Prediction with Zero-shot Ranking-based Context Retrieval
Oct 03, 2023



Machine-based prediction of real-world events is garnering attention due to its potential for informed decision-making. Whereas traditional forecasting predominantly hinges on structured data like time-series, recent breakthroughs in language models enable predictions using unstructured text. In particular, (Zou et al., 2022) unveils AutoCast, a new benchmark that employs news articles for answering forecasting queries. Nevertheless, existing methods still trail behind human performance. The cornerstone of accurate forecasting, we argue, lies in identifying a concise, yet rich subset of news snippets from a vast corpus. With this motivation, we introduce AutoCast++, a zero-shot ranking-based context retrieval system, tailored to sift through expansive news document collections for event forecasting. Our approach first re-ranks articles based on zero-shot question-passage relevance, honing in on semantically pertinent news. Following this, the chosen articles are subjected to zero-shot summarization to attain succinct context. Leveraging a pre-trained language model, we conduct both the relevance evaluation and article summarization without needing domain-specific training. Notably, recent articles can sometimes be at odds with preceding ones due to new facts or unanticipated incidents, leading to fluctuating temporal dynamics. To tackle this, our re-ranking mechanism gives preference to more recent articles, and we further regularize the multi-passage representation learning to align with human forecaster responses made on different dates. Empirical results underscore marked improvements across multiple metrics, improving the performance for multiple-choice questions (MCQ) by 48% and true/false (TF) questions by up to 8%.
Tsetlin Machine for Solving Contextual Bandit Problems
Feb 04, 2022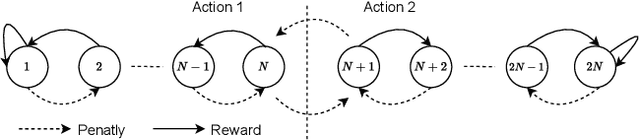
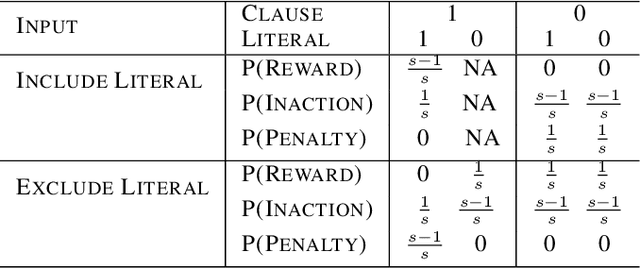
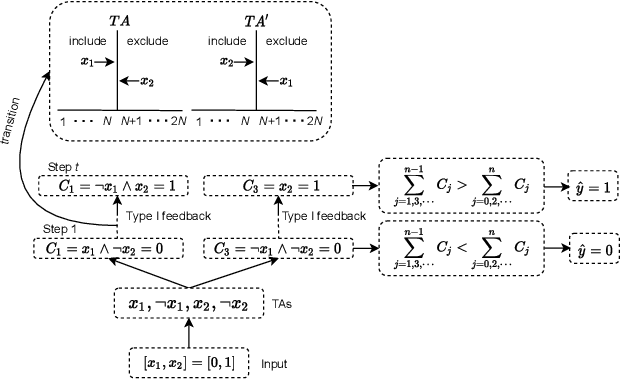
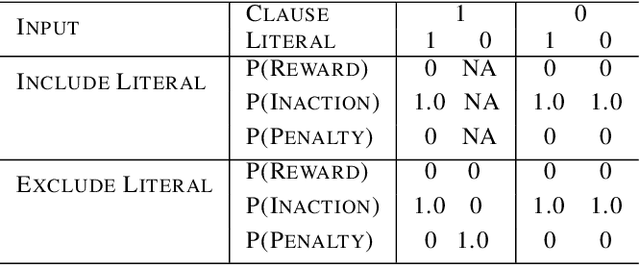
This paper introduces an interpretable contextual bandit algorithm using Tsetlin Machines, which solves complex pattern recognition tasks using propositional logic. The proposed bandit learning algorithm relies on straightforward bit manipulation, thus simplifying computation and interpretation. We then present a mechanism for performing Thompson sampling with Tsetlin Machine, given its non-parametric nature. Our empirical analysis shows that Tsetlin Machine as a base contextual bandit learner outperforms other popular base learners on eight out of nine datasets. We further analyze the interpretability of our learner, investigating how arms are selected based on propositional expressions that model the context.
Approximate information state for approximate planning and reinforcement learning in partially observed systems
Oct 17, 2020
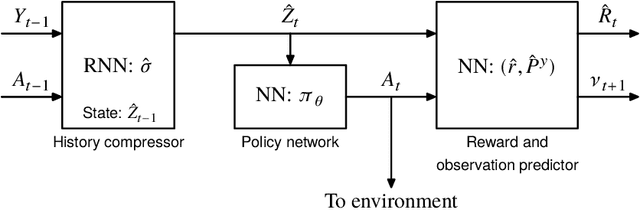
We propose a theoretical framework for approximate planning and learning in partially observed systems. Our framework is based on the fundamental notion of information state. We provide two equivalent definitions of information state---i) a function of history which is sufficient to compute the expected reward and predict its next value; ii) equivalently, a function of the history which can be recursively updated and is sufficient to compute the expected reward and predict the next observation. An information state always leads to a dynamic programming decomposition. Our key result is to show that if a function of the history (called approximate information state (AIS)) approximately satisfies the properties of the information state, then there is a corresponding approximate dynamic program. We show that the policy computed using this is approximately optimal with bounded loss of optimality. We show that several approximations in state, observation and action spaces in literature can be viewed as instances of AIS. In some of these cases, we obtain tighter bounds. A salient feature of AIS is that it can be learnt from data. We present AIS based multi-time scale policy gradient algorithms. and detailed numerical experiments with low, moderate and high dimensional environments.
Doubly Robust Off-Policy Actor-Critic Algorithms for Reinforcement Learning
Dec 11, 2019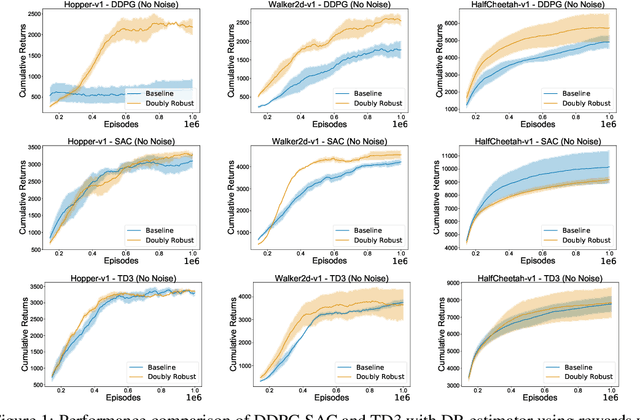
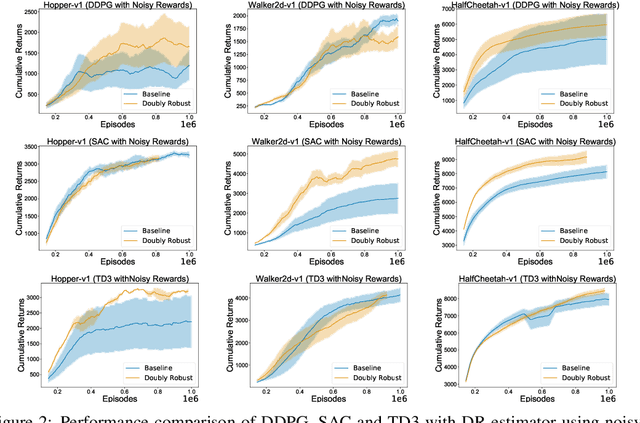
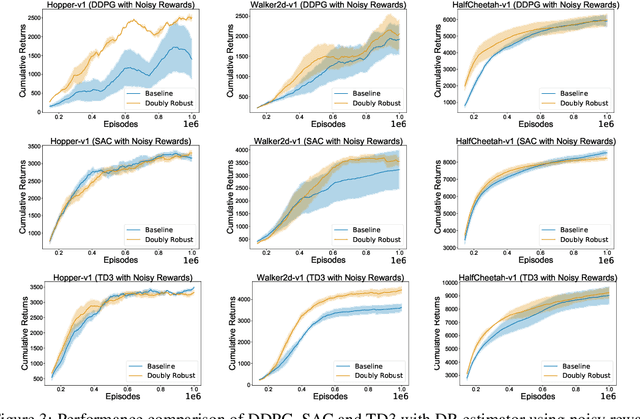
We study the problem of off-policy critic evaluation in several variants of value-based off-policy actor-critic algorithms. Off-policy actor-critic algorithms require an off-policy critic evaluation step, to estimate the value of the new policy after every policy gradient update. Despite enormous success of off-policy policy gradients on control tasks, existing general methods suffer from high variance and instability, partly because the policy improvement depends on gradient of the estimated value function. In this work, we present a new way of off-policy policy evaluation in actor-critic, based on the doubly robust estimators. We extend the doubly robust estimator from off-policy policy evaluation (OPE) to actor-critic algorithms that consist of a reward estimator performance model. We find that doubly robust estimation of the critic can significantly improve performance in continuous control tasks. Furthermore, in cases where the reward function is stochastic that can lead to high variance, doubly robust critic estimation can improve performance under corrupted, stochastic reward signals, indicating its usefulness for robust and safe reinforcement learning.
Entropy Regularization with Discounted Future State Distribution in Policy Gradient Methods
Dec 11, 2019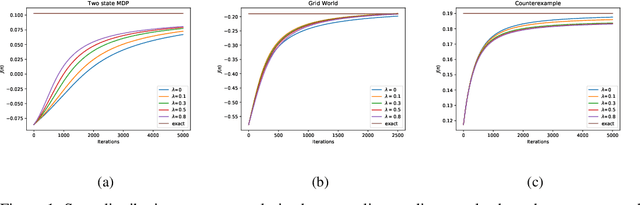
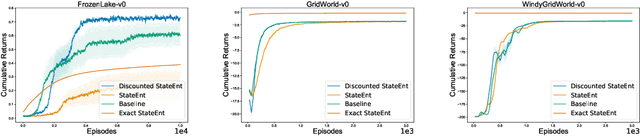
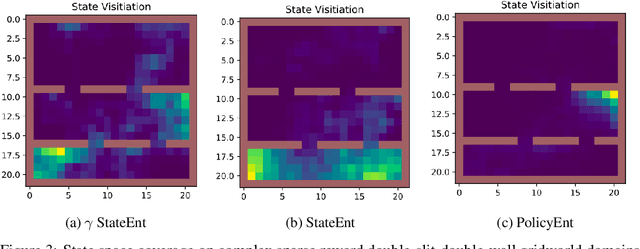
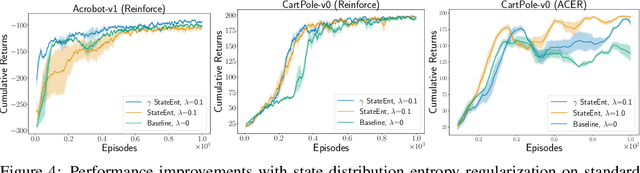
The policy gradient theorem is defined based on an objective with respect to the initial distribution over states. In the discounted case, this results in policies that are optimal for one distribution over initial states, but may not be uniformly optimal for others, no matter where the agent starts from. Furthermore, to obtain unbiased gradient estimates, the starting point of the policy gradient estimator requires sampling states from a normalized discounted weighting of states. However, the difficulty of estimating the normalized discounted weighting of states, or the stationary state distribution, is quite well-known. Additionally, the large sample complexity of policy gradient methods is often attributed to insufficient exploration, and to remedy this, it is often assumed that the restart distribution provides sufficient exploration in these algorithms. In this work, we propose exploration in policy gradient methods based on maximizing entropy of the discounted future state distribution. The key contribution of our work includes providing a practically feasible algorithm to estimate the normalized discounted weighting of states, i.e, the \textit{discounted future state distribution}. We propose that exploration can be achieved by entropy regularization with the discounted state distribution in policy gradients, where a metric for maximal coverage of the state space can be based on the entropy of the induced state distribution. The proposed approach can be considered as a three time-scale algorithm and under some mild technical conditions, we prove its convergence to a locally optimal policy. Experimentally, we demonstrate usefulness of regularization with the discounted future state distribution in terms of increased state space coverage and faster learning on a range of complex tasks.