 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizing Multi-Step Inverse Models for Representation Learning to Finite-Memory POMDPs
Apr 22, 2024Discovering an informative, or agent-centric, state representation that encodes only the relevant information while discarding the irrelevant is a key challenge towards scaling reinforcement learning algorithms and efficiently applying them to downstream tasks. Prior works studied this problem in high-dimensional Markovian environments, when the current observation may be a complex object but is sufficient to decode the informative state. In this work, we consider the problem of discovering the agent-centric state in the more challenging high-dimensional non-Markovian setting, when the state can be decoded from a sequence of past observations. We establish that generalized inverse models can be adapted for learning agent-centric state representation for this task. Our results include asymptotic theory in the deterministic dynamics setting as well as counter-examples for alternative intuitive algorithms. We complement these findings with a thorough empirical study on the agent-centric state discovery abilities of the different alternatives we put forward. Particularly notable is our analysis of past actions, where we show that these can be a double-edged sword: making the algorithms more successful when used correctly and causing dramatic failure when used incorrectly.
FourCastNeXt: Improving FourCastNet Training with Limited Compute
Jan 10, 2024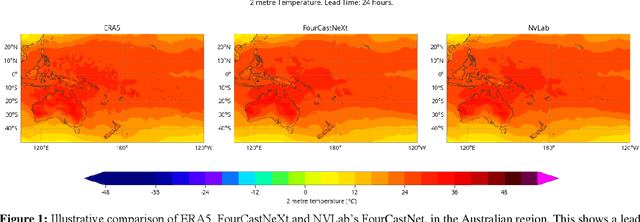

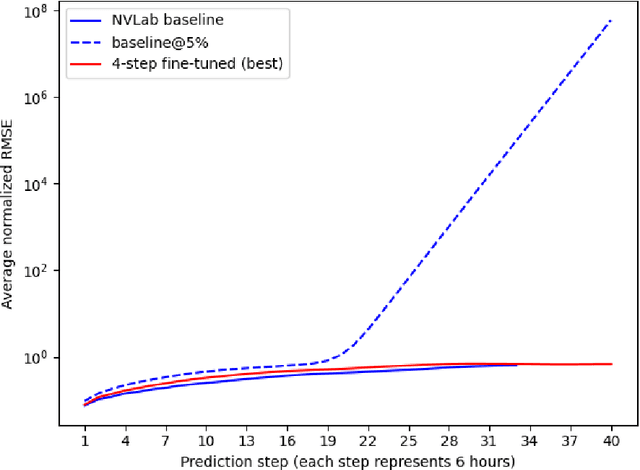
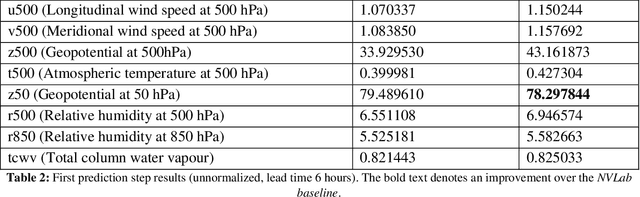
Recently, the FourCastNet Neural Earth System Model (NESM) has shown impressive results on predicting various atmospheric variables, trained on the ERA5 reanalysis dataset. While FourCastNet enjoys quasi-linear time and memory complexity in sequence length compared to quadratic complexity in vanilla transformers, training FourCastNet on ERA5 from scratch still requires large amount of compute resources, which is expensive or even inaccessible to most researchers. In this work, we will show improved methods that can train FourCastNet using only 1% of the compute required by the baseline, while maintaining model performance or par or even better than the baseline.
PcLast: Discovering Plannable Continuous Latent States
Nov 06, 2023



Goal-conditioned planning benefits from learned low-dimensional representations of rich, high-dimensional observations. While compact latent representations, typically learned from variational autoencoders or inverse dynamics, enable goal-conditioned planning they ignore state affordances, thus hampering their sample-efficient planning capabilities. In this paper, we learn a representation that associates reachable states together for effective onward planning. We first learn a latent representation with multi-step inverse dynamics (to remove distracting information); and then transform this representation to associate reachable states together in $\ell_2$ space. Our proposals are rigorously tested in various simulation testbeds. Numerical results in reward-based and reward-free settings show significant improvements in sampling efficiency, and yields layered state abstractions that enable computationally efficient hierarchical planning.
See to Touch: Learning Tactile Dexterity through Visual Incentives
Sep 21, 2023



Equipping multi-fingered robots with tactile sensing is crucial for achieving the precise, contact-rich, and dexterous manipulation that humans excel at. However, relying solely on tactile sensing fails to provide adequate cues for reasoning about objects' spatial configurations, limiting the ability to correct errors and adapt to changing situations. In this paper, we present Tactile Adaptation from Visual Incentives (TAVI), a new framework that enhances tactile-based dexterity by optimizing dexterous policies using vision-based rewards. First, we use a contrastive-based objective to learn visual representations. Next, we construct a reward function using these visual representations through optimal-transport based matching on one human demonstration. Finally, we use online reinforcement learning on our robot to optimize tactile-based policies that maximize the visual reward. On six challenging tasks, such as peg pick-and-place, unstacking bowls, and flipping slender objects, TAVI achieves a success rate of 73% using our four-fingered Allegro robot hand. The increase in performance is 108% higher than policies using tactile and vision-based rewards and 135% higher than policies without tactile observational input. Robot videos are best viewed on our project website: https://see-to-touch.github.io/.
Dexterity from Touch: Self-Supervised Pre-Training of Tactile Representations with Robotic Play
Mar 21, 2023



Teaching dexterity to multi-fingered robots has been a longstanding challenge in robotics. Most prominent work in this area focuses on learning controllers or policies that either operate on visual observations or state estimates derived from vision. However, such methods perform poorly on fine-grained manipulation tasks that require reasoning about contact forces or about objects occluded by the hand itself. In this work, we present T-Dex, a new approach for tactile-based dexterity, that operates in two phases. In the first phase, we collect 2.5 hours of play data, which is used to train self-supervised tactile encoders. This is necessary to bring high-dimensional tactile readings to a lower-dimensional embedding. In the second phase, given a handful of demonstrations for a dexterous task, we learn non-parametric policies that combine the tactile observations with visual ones. Across five challenging dexterous tasks, we show that our tactile-based dexterity models outperform purely vision and torque-based models by an average of 1.7X. Finally, we provide a detailed analysis on factors critical to T-Dex including the importance of play data, architectures, and representation learning.
Dexterous Imitation Made Easy: A Learning-Based Framework for Efficient Dexterous Manipulation
Mar 24, 2022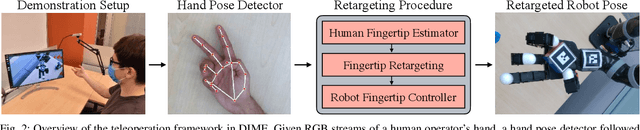



Optimizing behaviors for dexterous manipulation has been a longstanding challenge in robotics, with a variety of methods from model-based control to model-free reinforcement learning having been previously explored in literature. Perhaps one of the most powerful techniques to learn complex manipulation strategies is imitation learning. However, collecting and learning from demonstrations in dexterous manipulation is quite challenging. The complex, high-dimensional action-space involved with multi-finger control often leads to poor sample efficiency of learning-based methods. In this work, we propose 'Dexterous Imitation Made Easy' (DIME) a new imitation learning framework for dexterous manipulation. DIME only requires a single RGB camera to observe a human operator and teleoperate our robotic hand. Once demonstrations are collected, DIME employs standard imitation learning methods to train dexterous manipulation policies. On both simulation and real robot benchmarks we demonstrate that DIME can be used to solve complex, in-hand manipulation tasks such as 'flipping', 'spinning', and 'rotating' objects with the Allegro hand. Our framework along with pre-collected demonstrations is publicly available at https://nyu-robot-learning.github.io/dime.
Context is Everything: Implicit Identification for Dynamics Adaptation
Mar 10, 2022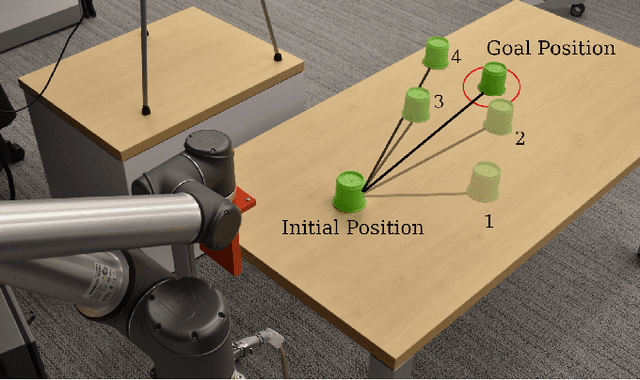
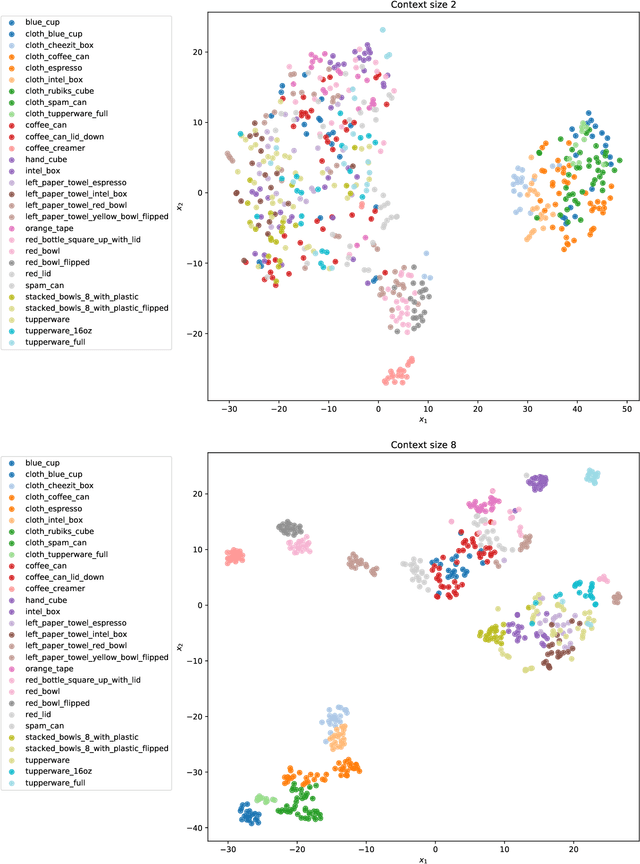
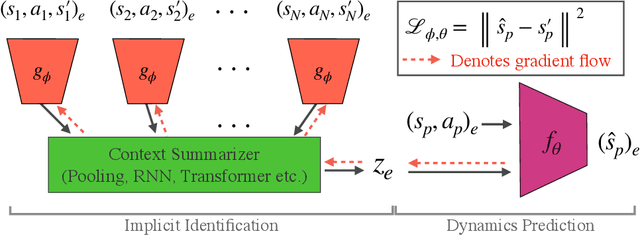

Understanding environment dynamics is necessary for robots to act safely and optimally in the world. In realistic scenarios, dynamics are non-stationary and the causal variables such as environment parameters cannot necessarily be precisely measured or inferred, even during training. We propose Implicit Identification for Dynamics Adaptation (IIDA), a simple method to allow predictive models to adapt to changing environment dynamics. IIDA assumes no access to the true variations in the world and instead implicitly infers properties of the environment from a small amount of contextual data. We demonstrate IIDA's ability to perform well in unseen environments through a suite of simulated experiments on MuJoCo environments and a real robot dynamic sliding task. In general, IIDA significantly reduces model error and results in higher task performance over commonly used methods. Our code and robot videos are at https://bennevans.github.io/iida/
BAM: Bayes with Adaptive Memory
Feb 08, 2022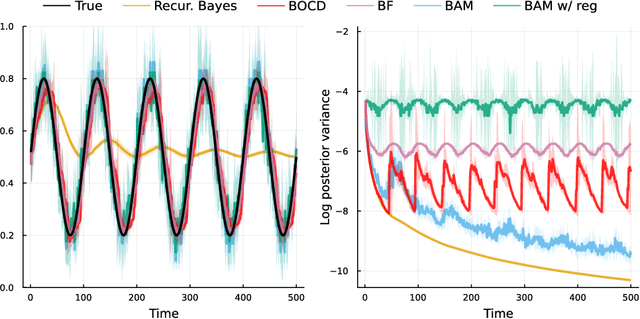
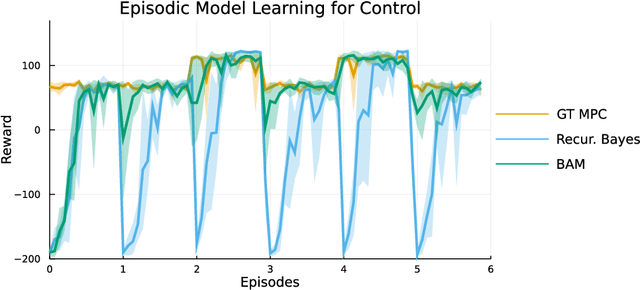
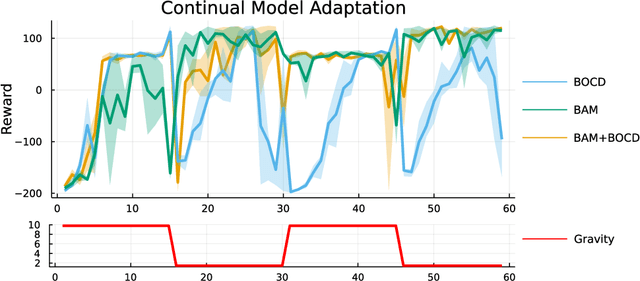
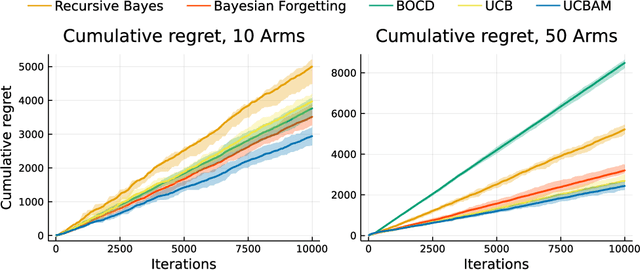
Online learning via Bayes' theorem allows new data to be continuously integrated into an agent's current beliefs. However, a naive application of Bayesian methods in non stationary environments leads to slow adaptation and results in state estimates that may converge confidently to the wrong parameter value. A common solution when learning in changing environments is to discard/downweight past data; however, this simple mechanism of "forgetting" fails to account for the fact that many real-world environments involve revisiting similar states. We propose a new framework, Bayes with Adaptive Memory (BAM), that takes advantage of past experience by allowing the agent to choose which past observations to remember and which to forget. We demonstrate that BAM generalizes many popular Bayesian update rules for non-stationary environments. Through a variety of experiments, we demonstrate the ability of BAM to continuously adapt in an ever-changing world.
It's the Journey Not the Destination: Building Genetic Algorithms Practitioners Can Trust
Oct 13, 2020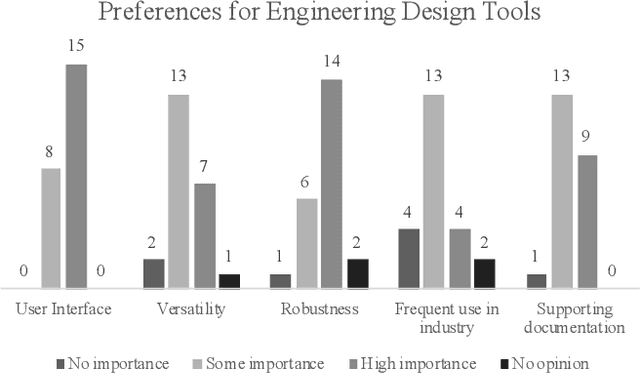

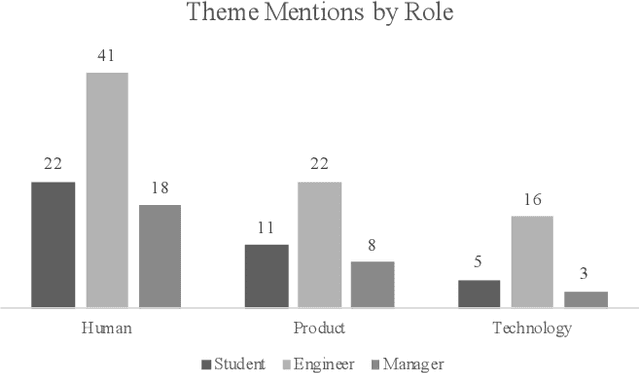

Genetic algorithms have been developed for decades by researchers in academia and perform well in engineering applications, yet their uptake in industry remains limited. In order to understand why this is the case, the opinions of users of engineering design tools were gathered. The results from a survey showing the attitudes of engineers and students with design experience with respect to optimisation algorithms are presented. A survey was designed to answer two research questions: To what extent is there a pre-existing sentiment (negative or positive) among students, engineers, and managers towards genetic algorithm-based design? and What are the requirements of practitioners with regards to design optimisation and the design optimisation process? A total of 23 participants (N = 23) took part in the 3-part mixed methods survey. Thematic analysis was conducted on the open-ended questions. A common thread throughout participants responses is that there is a question of trust towards genetic algorithms within industry. Perhaps surprising is that the key to gaining this trust is not producing good results, but creating algorithms which explain the process they take in reaching a result. Participants have expressed a desire to continue to remain in the design loop. This is at odds with the motivation of a portion of the genetic algorithms community of removing humans from the loop. It is clear we need to take a different approach to increase industrial uptake. Based on this, the following recommendations have been made to increase their use in industry: an increase of transparency and explainability of genetic algorithms, an increased focus on user experience, better communication between developers and engineers, and visualising algorithm behaviour.