 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRUKA: Rethinking the Design of Humanoid Hands with Learning
Apr 17, 2025Dexterous manipulation is a fundamental capability for robotic systems, yet progress has been limited by hardware trade-offs between precision, compactness, strength, and affordability. Existing control methods impose compromises on hand designs and applications. However, learning-based approaches present opportunities to rethink these trade-offs, particularly to address challenges with tendon-driven actuation and low-cost materials. This work presents RUKA, a tendon-driven humanoid hand that is compact, affordable, and capable. Made from 3D-printed parts and off-the-shelf components, RUKA has 5 fingers with 15 underactuated degrees of freedom enabling diverse human-like grasps. Its tendon-driven actuation allows powerful grasping in a compact, human-sized form factor. To address control challenges, we learn joint-to-actuator and fingertip-to-actuator models from motion-capture data collected by the MANUS glove, leveraging the hand's morphological accuracy. Extensive evaluations demonstrate RUKA's superior reachability, durability, and strength compared to other robotic hands. Teleoperation tasks further showcase RUKA's dexterous movements. The open-source design and assembly instructions of RUKA, code, and data are available at https://ruka-hand.github.io/.
Bridging the Human to Robot Dexterity Gap through Object-Oriented Rewards
Oct 30, 2024



Training robots directly from human videos is an emerging area in robotics and computer vision. While there has been notable progress with two-fingered grippers, learning autonomous tasks for multi-fingered robot hands in this way remains challenging. A key reason for this difficulty is that a policy trained on human hands may not directly transfer to a robot hand due to morphology differences. In this work, we present HuDOR, a technique that enables online fine-tuning of policies by directly computing rewards from human videos. Importantly, this reward function is built using object-oriented trajectories derived from off-the-shelf point trackers, providing meaningful learning signals despite the morphology gap and visual differences between human and robot hands. Given a single video of a human solving a task, such as gently opening a music box, HuDOR enables our four-fingered Allegro hand to learn the task with just an hour of online interaction. Our experiments across four tasks show that HuDOR achieves a 4x improvement over baselines. Code and videos are available on our website, https://object-rewards.github.io.
OPEN TEACH: A Versatile Teleoperation System for Robotic Manipulation
Mar 12, 2024


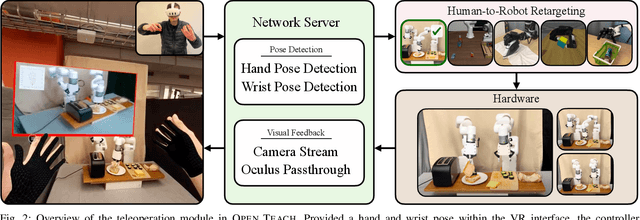
Open-sourced, user-friendly tools form the bedrock of scientific advancement across disciplines. The widespread adoption of data-driven learning has led to remarkable progress in multi-fingered dexterity, bimanual manipulation, and applications ranging from logistics to home robotics. However, existing data collection platforms are often proprietary, costly, or tailored to specific robotic morphologies. We present OPEN TEACH, a new teleoperation system leveraging VR headsets to immerse users in mixed reality for intuitive robot control. Built on the affordable Meta Quest 3, which costs $500, OPEN TEACH enables real-time control of various robots, including multi-fingered hands and bimanual arms, through an easy-to-use app. Using natural hand gestures and movements, users can manipulate robots at up to 90Hz with smooth visual feedback and interface widgets offering closeup environment views. We demonstrate the versatility of OPEN TEACH across 38 tasks on different robots. A comprehensive user study indicates significant improvement in teleoperation capability over the AnyTeleop framework. Further experiments exhibit that the collected data is compatible with policy learning on 10 dexterous and contact-rich manipulation tasks. Currently supporting Franka, xArm, Jaco, and Allegro platforms, OPEN TEACH is fully open-sourced to promote broader adoption. Videos are available at https://open-teach.github.io/.
See to Touch: Learning Tactile Dexterity through Visual Incentives
Sep 21, 2023



Equipping multi-fingered robots with tactile sensing is crucial for achieving the precise, contact-rich, and dexterous manipulation that humans excel at. However, relying solely on tactile sensing fails to provide adequate cues for reasoning about objects' spatial configurations, limiting the ability to correct errors and adapt to changing situations. In this paper, we present Tactile Adaptation from Visual Incentives (TAVI), a new framework that enhances tactile-based dexterity by optimizing dexterous policies using vision-based rewards. First, we use a contrastive-based objective to learn visual representations. Next, we construct a reward function using these visual representations through optimal-transport based matching on one human demonstration. Finally, we use online reinforcement learning on our robot to optimize tactile-based policies that maximize the visual reward. On six challenging tasks, such as peg pick-and-place, unstacking bowls, and flipping slender objects, TAVI achieves a success rate of 73% using our four-fingered Allegro robot hand. The increase in performance is 108% higher than policies using tactile and vision-based rewards and 135% higher than policies without tactile observational input. Robot videos are best viewed on our project website: https://see-to-touch.github.io/.
Dexterity from Touch: Self-Supervised Pre-Training of Tactile Representations with Robotic Play
Mar 21, 2023



Teaching dexterity to multi-fingered robots has been a longstanding challenge in robotics. Most prominent work in this area focuses on learning controllers or policies that either operate on visual observations or state estimates derived from vision. However, such methods perform poorly on fine-grained manipulation tasks that require reasoning about contact forces or about objects occluded by the hand itself. In this work, we present T-Dex, a new approach for tactile-based dexterity, that operates in two phases. In the first phase, we collect 2.5 hours of play data, which is used to train self-supervised tactile encoders. This is necessary to bring high-dimensional tactile readings to a lower-dimensional embedding. In the second phase, given a handful of demonstrations for a dexterous task, we learn non-parametric policies that combine the tactile observations with visual ones. Across five challenging dexterous tasks, we show that our tactile-based dexterity models outperform purely vision and torque-based models by an average of 1.7X. Finally, we provide a detailed analysis on factors critical to T-Dex including the importance of play data, architectures, and representation learning.