 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynaMem: Online Dynamic Spatio-Semantic Memory for Open World Mobile Manipulation
Nov 07, 2024

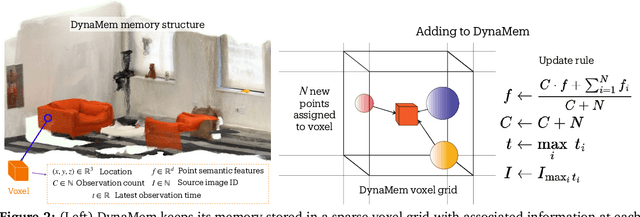
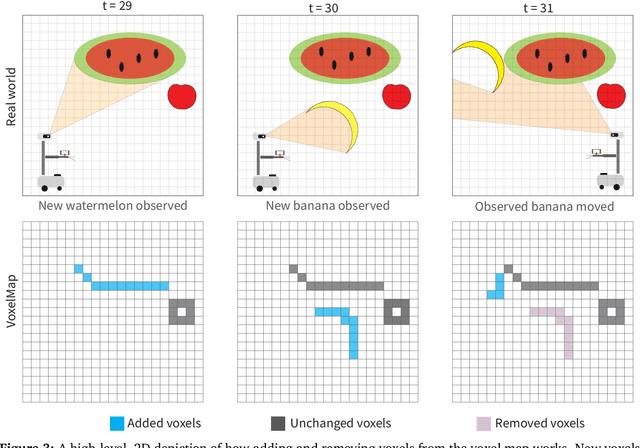
Significant progress has been made in open-vocabulary mobile manipulation, where the goal is for a robot to perform tasks in any environment given a natural language description. However, most current systems assume a static environment, which limits the system's applicability in real-world scenarios where environments frequently change due to human intervention or the robot's own actions. In this work, we present DynaMem, a new approach to open-world mobile manipulation that uses a dynamic spatio-semantic memory to represent a robot's environment. DynaMem constructs a 3D data structure to maintain a dynamic memory of point clouds, and answers open-vocabulary object localization queries using multimodal LLMs or open-vocabulary features generated by state-of-the-art vision-language models. Powered by DynaMem, our robots can explore novel environments, search for objects not found in memory, and continuously update the memory as objects move, appear, or disappear in the scene. We run extensive experiments on the Stretch SE3 robots in three real and nine offline scenes, and achieve an average pick-and-drop success rate of 70% on non-stationary objects, which is more than a 2x improvement over state-of-the-art static systems. Our code as well as our experiment and deployment videos are open sourced and can be found on our project website: https://dynamem.github.io/
Robot Utility Models: General Policies for Zero-Shot Deployment in New Environments
Sep 09, 2024Robot models, particularly those trained with large amounts of data, have recently shown a plethora of real-world manipulation and navigation capabilities. Several independent efforts have shown that given sufficient training data in an environment, robot policies can generalize to demonstrated variations in that environment. However, needing to finetune robot models to every new environment stands in stark contrast to models in language or vision that can be deployed zero-shot for open-world problems. In this work, we present Robot Utility Models (RUMs), a framework for training and deploying zero-shot robot policies that can directly generalize to new environments without any finetuning. To create RUMs efficiently, we develop new tools to quickly collect data for mobile manipulation tasks, integrate such data into a policy with multi-modal imitation learning, and deploy policies on-device on Hello Robot Stretch, a cheap commodity robot, with an external mLLM verifier for retrying. We train five such utility models for opening cabinet doors, opening drawers, picking up napkins, picking up paper bags, and reorienting fallen objects. Our system, on average, achieves 90% success rate in unseen, novel environments interacting with unseen objects. Moreover, the utility models can also succeed in different robot and camera set-ups with no further data, training, or fine-tuning. Primary among our lessons are the importance of training data over training algorithm and policy class, guidance about data scaling, necessity for diverse yet high-quality demonstrations, and a recipe for robot introspection and retrying to improve performance on individual environments. Our code, data, models, hardware designs, as well as our experiment and deployment videos are open sourced and can be found on our project website: https://robotutilitymodels.com
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
OPEN TEACH: A Versatile Teleoperation System for Robotic Manipulation
Mar 12, 2024


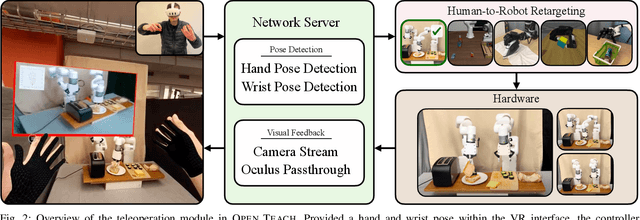
Open-sourced, user-friendly tools form the bedrock of scientific advancement across disciplines. The widespread adoption of data-driven learning has led to remarkable progress in multi-fingered dexterity, bimanual manipulation, and applications ranging from logistics to home robotics. However, existing data collection platforms are often proprietary, costly, or tailored to specific robotic morphologies. We present OPEN TEACH, a new teleoperation system leveraging VR headsets to immerse users in mixed reality for intuitive robot control. Built on the affordable Meta Quest 3, which costs $500, OPEN TEACH enables real-time control of various robots, including multi-fingered hands and bimanual arms, through an easy-to-use app. Using natural hand gestures and movements, users can manipulate robots at up to 90Hz with smooth visual feedback and interface widgets offering closeup environment views. We demonstrate the versatility of OPEN TEACH across 38 tasks on different robots. A comprehensive user study indicates significant improvement in teleoperation capability over the AnyTeleop framework. Further experiments exhibit that the collected data is compatible with policy learning on 10 dexterous and contact-rich manipulation tasks. Currently supporting Franka, xArm, Jaco, and Allegro platforms, OPEN TEACH is fully open-sourced to promote broader adoption. Videos are available at https://open-teach.github.io/.
On Bringing Robots Home
Nov 27, 2023Throughout history, we have successfully integrated various machines into our homes. Dishwashers, laundry machines, stand mixers, and robot vacuums are a few recent examples. However, these machines excel at performing only a single task effectively. The concept of a "generalist machine" in homes - a domestic assistant that can adapt and learn from our needs, all while remaining cost-effective - has long been a goal in robotics that has been steadily pursued for decades. In this work, we initiate a large-scale effort towards this goal by introducing Dobb-E, an affordable yet versatile general-purpose system for learning robotic manipulation within household settings. Dobb-E can learn a new task with only five minutes of a user showing it how to do it, thanks to a demonstration collection tool ("The Stick") we built out of cheap parts and iPhones. We use the Stick to collect 13 hours of data in 22 homes of New York City, and train Home Pretrained Representations (HPR). Then, in a novel home environment, with five minutes of demonstrations and fifteen minutes of adapting the HPR model, we show that Dobb-E can reliably solve the task on the Stretch, a mobile robot readily available on the market. Across roughly 30 days of experimentation in homes of New York City and surrounding areas, we test our system in 10 homes, with a total of 109 tasks in different environments, and finally achieve a success rate of 81%. Beyond success percentages, our experiments reveal a plethora of unique challenges absent or ignored in lab robotics. These range from effects of strong shadows, to variable demonstration quality by non-expert users. With the hope of accelerating research on home robots, and eventually seeing robot butlers in every home, we open-source Dobb-E software stack and models, our data, and our hardware designs at https://dobb-e.com
See to Touch: Learning Tactile Dexterity through Visual Incentives
Sep 21, 2023



Equipping multi-fingered robots with tactile sensing is crucial for achieving the precise, contact-rich, and dexterous manipulation that humans excel at. However, relying solely on tactile sensing fails to provide adequate cues for reasoning about objects' spatial configurations, limiting the ability to correct errors and adapt to changing situations. In this paper, we present Tactile Adaptation from Visual Incentives (TAVI), a new framework that enhances tactile-based dexterity by optimizing dexterous policies using vision-based rewards. First, we use a contrastive-based objective to learn visual representations. Next, we construct a reward function using these visual representations through optimal-transport based matching on one human demonstration. Finally, we use online reinforcement learning on our robot to optimize tactile-based policies that maximize the visual reward. On six challenging tasks, such as peg pick-and-place, unstacking bowls, and flipping slender objects, TAVI achieves a success rate of 73% using our four-fingered Allegro robot hand. The increase in performance is 108% higher than policies using tactile and vision-based rewards and 135% higher than policies without tactile observational input. Robot videos are best viewed on our project website: https://see-to-touch.github.io/.
Dexterity from Touch: Self-Supervised Pre-Training of Tactile Representations with Robotic Play
Mar 21, 2023



Teaching dexterity to multi-fingered robots has been a longstanding challenge in robotics. Most prominent work in this area focuses on learning controllers or policies that either operate on visual observations or state estimates derived from vision. However, such methods perform poorly on fine-grained manipulation tasks that require reasoning about contact forces or about objects occluded by the hand itself. In this work, we present T-Dex, a new approach for tactile-based dexterity, that operates in two phases. In the first phase, we collect 2.5 hours of play data, which is used to train self-supervised tactile encoders. This is necessary to bring high-dimensional tactile readings to a lower-dimensional embedding. In the second phase, given a handful of demonstrations for a dexterous task, we learn non-parametric policies that combine the tactile observations with visual ones. Across five challenging dexterous tasks, we show that our tactile-based dexterity models outperform purely vision and torque-based models by an average of 1.7X. Finally, we provide a detailed analysis on factors critical to T-Dex including the importance of play data, architectures, and representation learning.
Navigating to Objects in the Real World
Dec 02, 2022Semantic navigation is necessary to deploy mobile robots in uncontrolled environments like our homes, schools, and hospitals. Many learning-based approaches have been proposed in response to the lack of semantic understanding of the classical pipeline for spatial navigation, which builds a geometric map using depth sensors and plans to reach point goals. Broadly, end-to-end learning approaches reactively map sensor inputs to actions with deep neural networks, while modular learning approaches enrich the classical pipeline with learning-based semantic sensing and exploration. But learned visual navigation policies have predominantly been evaluated in simulation. How well do different classes of methods work on a robot? We present a large-scale empirical study of semantic visual navigation methods comparing representative methods from classical, modular, and end-to-end learning approaches across six homes with no prior experience, maps, or instrumentation. We find that modular learning works well in the real world, attaining a 90% success rate. In contrast, end-to-end learning does not, dropping from 77% simulation to 23% real-world success rate due to a large image domain gap between simulation and reality. For practitioners, we show that modular learning is a reliable approach to navigate to objects: modularity and abstraction in policy design enable Sim-to-Real transfer. For researchers, we identify two key issues that prevent today's simulators from being reliable evaluation benchmarks - (A) a large Sim-to-Real gap in images and (B) a disconnect between simulation and real-world error modes - and propose concrete steps forward.
Holo-Dex: Teaching Dexterity with Immersive Mixed Reality
Oct 12, 2022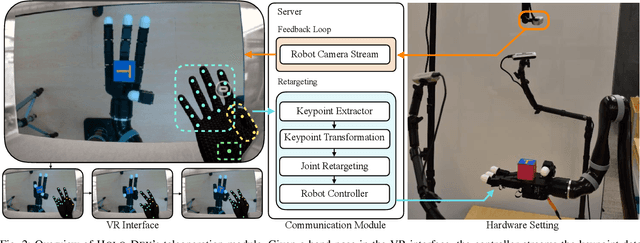



A fundamental challenge in teaching robots is to provide an effective interface for human teachers to demonstrate useful skills to a robot. This challenge is exacerbated in dexterous manipulation, where teaching high-dimensional, contact-rich behaviors often require esoteric teleoperation tools. In this work, we present Holo-Dex, a framework for dexterous manipulation that places a teacher in an immersive mixed reality through commodity VR headsets. The high-fidelity hand pose estimator onboard the headset is used to teleoperate the robot and collect demonstrations for a variety of general-purpose dexterous tasks. Given these demonstrations, we use powerful feature learning combined with non-parametric imitation to train dexterous skills. Our experiments on six common dexterous tasks, including in-hand rotation, spinning, and bottle opening, indicate that Holo-Dex can both collect high-quality demonstration data and train skills in a matter of hours. Finally, we find that our trained skills can exhibit generalization on objects not seen in training. Videos of Holo-Dex are available at https://holo-dex.github.io.
CLIP-Fields: Weakly Supervised Semantic Fields for Robotic Memory
Oct 11, 2022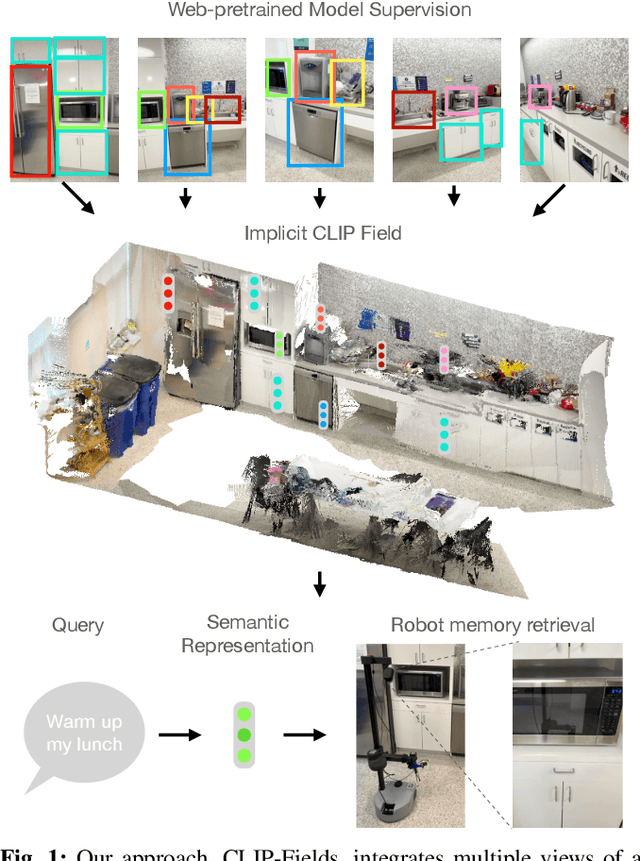
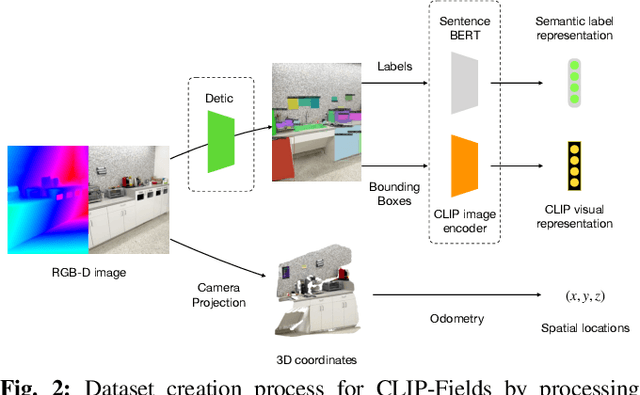
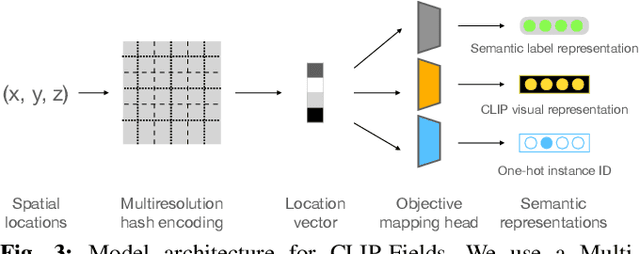
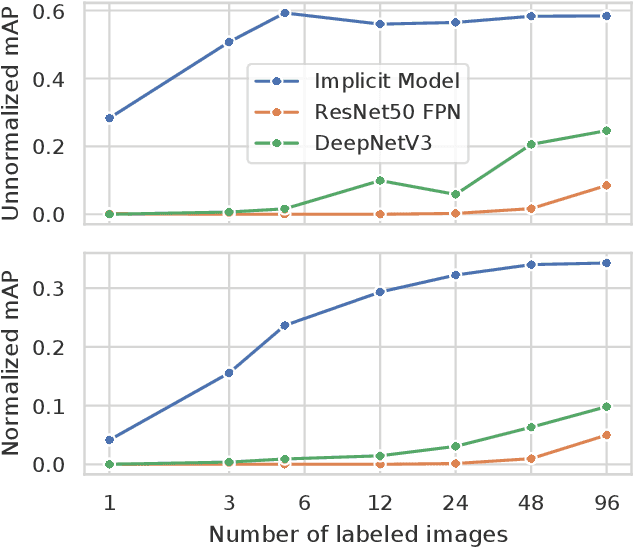
We propose CLIP-Fields, an implicit scene model that can be trained with no direct human supervision. This model learns a mapping from spatial locations to semantic embedding vectors. The mapping can then be used for a variety of tasks, such as segmentation, instance identification, semantic search over space, and view localization. Most importantly, the mapping can be trained with supervision coming only from web-image and web-text trained models such as CLIP, Detic, and Sentence-BERT. When compared to baselines like Mask-RCNN, our method outperforms on few-shot instance identification or semantic segmentation on the HM3D dataset with only a fraction of the examples. Finally, we show that using CLIP-Fields as a scene memory, robots can perform semantic navigation in real-world environments. Our code and demonstrations are available here: https://mahis.life/clip-fields/