 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMolmoSpaces: A Large-Scale Open Ecosystem for Robot Navigation and Manipulation
Feb 11, 2026Deploying robots at scale demands robustness to the long tail of everyday situations. The countless variations in scene layout, object geometry, and task specifications that characterize real environments are vast and underrepresented in existing robot benchmarks. Measuring this level of generalization requires infrastructure at a scale and diversity that physical evaluation alone cannot provide. We introduce MolmoSpaces, a fully open ecosystem to support large-scale benchmarking of robot policies. MolmoSpaces consists of over 230k diverse indoor environments, ranging from handcrafted household scenes to procedurally generated multiroom houses, populated with 130k richly annotated object assets, including 48k manipulable objects with 42M stable grasps. Crucially, these environments are simulator-agnostic, supporting popular options such as MuJoCo, Isaac, and ManiSkill. The ecosystem supports the full spectrum of embodied tasks: static and mobile manipulation, navigation, and multiroom long-horizon tasks requiring coordinated perception, planning, and interaction across entire indoor environments. We also design MolmoSpaces-Bench, a benchmark suite of 8 tasks in which robots interact with our diverse scenes and richly annotated objects. Our experiments show MolmoSpaces-Bench exhibits strong sim-to-real correlation (R = 0.96, \r{ho} = 0.98), confirm newer and stronger zero-shot policies outperform earlier versions in our benchmarks, and identify key sensitivities to prompt phrasing, initial joint positions, and camera occlusion. Through MolmoSpaces and its open-source assets and tooling, we provide a foundation for scalable data generation, policy training, and benchmark creation for robot learning research.
YOR: Your Own Mobile Manipulator for Generalizable Robotics
Feb 11, 2026Recent advances in robot learning have generated significant interest in capable platforms that may eventually approach human-level competence. This interest, combined with the commoditization of actuators, has propelled growth in low-cost robotic platforms. However, the optimal form factor for mobile manipulation, especially on a budget, remains an open question. We introduce YOR, an open-source, low-cost mobile manipulator that integrates an omnidirectional base, a telescopic vertical lift, and two arms with grippers to achieve whole-body mobility and manipulation. Our design emphasizes modularity, ease of assembly using off-the-shelf components, and affordability, with a bill-of-materials cost under 10,000 USD. We demonstrate YOR's capability by completing tasks that require coordinated whole-body control, bimanual manipulation, and autonomous navigation. Overall, YOR offers competitive functionality for mobile manipulation research at a fraction of the cost of existing platforms. Project website: https://www.yourownrobot.ai/
Contact-Anchored Policies: Contact Conditioning Creates Strong Robot Utility Models
Feb 09, 2026The prevalent paradigm in robot learning attempts to generalize across environments, embodiments, and tasks with language prompts at runtime. A fundamental tension limits this approach: language is often too abstract to guide the concrete physical understanding required for robust manipulation. In this work, we introduce Contact-Anchored Policies (CAP), which replace language conditioning with points of physical contact in space. Simultaneously, we structure CAP as a library of modular utility models rather than a monolithic generalist policy. This factorization allows us to implement a real-to-sim iteration cycle: we build EgoGym, a lightweight simulation benchmark, to rapidly identify failure modes and refine our models and datasets prior to real-world deployment. We show that by conditioning on contact and iterating via simulation, CAP generalizes to novel environments and embodiments out of the box on three fundamental manipulation skills while using only 23 hours of demonstration data, and outperforms large, state-of-the-art VLAs in zero-shot evaluations by 56%. All model checkpoints, codebase, hardware, simulation, and datasets will be open-sourced. Project page: https://cap-policy.github.io/
DynaMem: Online Dynamic Spatio-Semantic Memory for Open World Mobile Manipulation
Nov 07, 2024

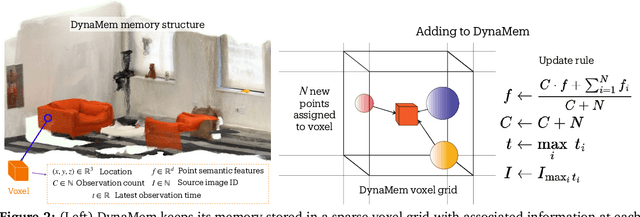
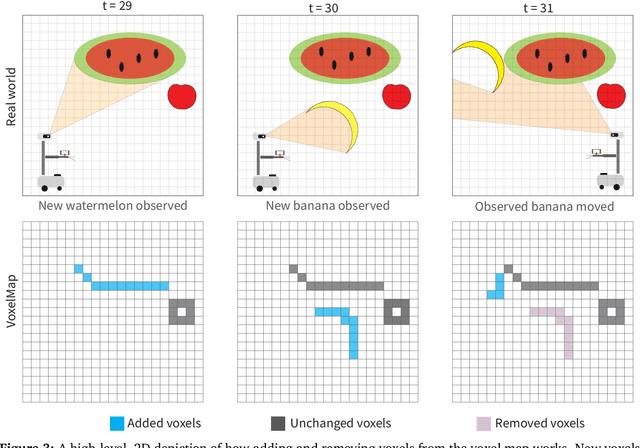
Significant progress has been made in open-vocabulary mobile manipulation, where the goal is for a robot to perform tasks in any environment given a natural language description. However, most current systems assume a static environment, which limits the system's applicability in real-world scenarios where environments frequently change due to human intervention or the robot's own actions. In this work, we present DynaMem, a new approach to open-world mobile manipulation that uses a dynamic spatio-semantic memory to represent a robot's environment. DynaMem constructs a 3D data structure to maintain a dynamic memory of point clouds, and answers open-vocabulary object localization queries using multimodal LLMs or open-vocabulary features generated by state-of-the-art vision-language models. Powered by DynaMem, our robots can explore novel environments, search for objects not found in memory, and continuously update the memory as objects move, appear, or disappear in the scene. We run extensive experiments on the Stretch SE3 robots in three real and nine offline scenes, and achieve an average pick-and-drop success rate of 70% on non-stationary objects, which is more than a 2x improvement over state-of-the-art static systems. Our code as well as our experiment and deployment videos are open sourced and can be found on our project website: https://dynamem.github.io/
Robot Utility Models: General Policies for Zero-Shot Deployment in New Environments
Sep 09, 2024Robot models, particularly those trained with large amounts of data, have recently shown a plethora of real-world manipulation and navigation capabilities. Several independent efforts have shown that given sufficient training data in an environment, robot policies can generalize to demonstrated variations in that environment. However, needing to finetune robot models to every new environment stands in stark contrast to models in language or vision that can be deployed zero-shot for open-world problems. In this work, we present Robot Utility Models (RUMs), a framework for training and deploying zero-shot robot policies that can directly generalize to new environments without any finetuning. To create RUMs efficiently, we develop new tools to quickly collect data for mobile manipulation tasks, integrate such data into a policy with multi-modal imitation learning, and deploy policies on-device on Hello Robot Stretch, a cheap commodity robot, with an external mLLM verifier for retrying. We train five such utility models for opening cabinet doors, opening drawers, picking up napkins, picking up paper bags, and reorienting fallen objects. Our system, on average, achieves 90% success rate in unseen, novel environments interacting with unseen objects. Moreover, the utility models can also succeed in different robot and camera set-ups with no further data, training, or fine-tuning. Primary among our lessons are the importance of training data over training algorithm and policy class, guidance about data scaling, necessity for diverse yet high-quality demonstrations, and a recipe for robot introspection and retrying to improve performance on individual environments. Our code, data, models, hardware designs, as well as our experiment and deployment videos are open sourced and can be found on our project website: https://robotutilitymodels.com
Behavior Generation with Latent Actions
Mar 05, 2024



Generative modeling of complex behaviors from labeled datasets has been a longstanding problem in decision making. Unlike language or image generation, decision making requires modeling actions - continuous-valued vectors that are multimodal in their distribution, potentially drawn from uncurated sources, where generation errors can compound in sequential prediction. A recent class of models called Behavior Transformers (BeT) addresses this by discretizing actions using k-means clustering to capture different modes. However, k-means struggles to scale for high-dimensional action spaces or long sequences, and lacks gradient information, and thus BeT suffers in modeling long-range actions. In this work, we present Vector-Quantized Behavior Transformer (VQ-BeT), a versatile model for behavior generation that handles multimodal action prediction, conditional generation, and partial observations. VQ-BeT augments BeT by tokenizing continuous actions with a hierarchical vector quantization module. Across seven environments including simulated manipulation, autonomous driving, and robotics, VQ-BeT improves on state-of-the-art models such as BeT and Diffusion Policies. Importantly, we demonstrate VQ-BeT's improved ability to capture behavior modes while accelerating inference speed 5x over Diffusion Policies. Videos and code can be found https://sjlee.cc/vq-bet
OK-Robot: What Really Matters in Integrating Open-Knowledge Models for Robotics
Jan 22, 2024


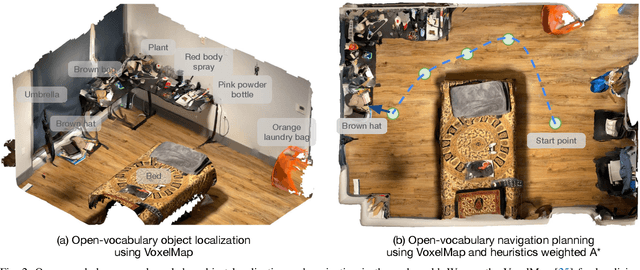
Remarkable progress has been made in recent years in the fields of vision, language, and robotics. We now have vision models capable of recognizing objects based on language queries, navigation systems that can effectively control mobile systems, and grasping models that can handle a wide range of objects. Despite these advancements, general-purpose applications of robotics still lag behind, even though they rely on these fundamental capabilities of recognition, navigation, and grasping. In this paper, we adopt a systems-first approach to develop a new Open Knowledge-based robotics framework called OK-Robot. By combining Vision-Language Models (VLMs) for object detection, navigation primitives for movement, and grasping primitives for object manipulation, OK-Robot offers a integrated solution for pick-and-drop operations without requiring any training. To evaluate its performance, we run OK-Robot in 10 real-world home environments. The results demonstrate that OK-Robot achieves a 58.5% success rate in open-ended pick-and-drop tasks, representing a new state-of-the-art in Open Vocabulary Mobile Manipulation (OVMM) with nearly 1.8x the performance of prior work. On cleaner, uncluttered environments, OK-Robot's performance increases to 82%. However, the most important insight gained from OK-Robot is the critical role of nuanced details when combining Open Knowledge systems like VLMs with robotic modules. Videos of our experiments are available on our website: https://ok-robot.github.io
On Bringing Robots Home
Nov 27, 2023Throughout history, we have successfully integrated various machines into our homes. Dishwashers, laundry machines, stand mixers, and robot vacuums are a few recent examples. However, these machines excel at performing only a single task effectively. The concept of a "generalist machine" in homes - a domestic assistant that can adapt and learn from our needs, all while remaining cost-effective - has long been a goal in robotics that has been steadily pursued for decades. In this work, we initiate a large-scale effort towards this goal by introducing Dobb-E, an affordable yet versatile general-purpose system for learning robotic manipulation within household settings. Dobb-E can learn a new task with only five minutes of a user showing it how to do it, thanks to a demonstration collection tool ("The Stick") we built out of cheap parts and iPhones. We use the Stick to collect 13 hours of data in 22 homes of New York City, and train Home Pretrained Representations (HPR). Then, in a novel home environment, with five minutes of demonstrations and fifteen minutes of adapting the HPR model, we show that Dobb-E can reliably solve the task on the Stretch, a mobile robot readily available on the market. Across roughly 30 days of experimentation in homes of New York City and surrounding areas, we test our system in 10 homes, with a total of 109 tasks in different environments, and finally achieve a success rate of 81%. Beyond success percentages, our experiments reveal a plethora of unique challenges absent or ignored in lab robotics. These range from effects of strong shadows, to variable demonstration quality by non-expert users. With the hope of accelerating research on home robots, and eventually seeing robot butlers in every home, we open-source Dobb-E software stack and models, our data, and our hardware designs at https://dobb-e.com
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
From Play to Policy: Conditional Behavior Generation from Uncurated Robot Data
Oct 19, 2022


While large-scale sequence modeling from offline data has led to impressive performance gains in natural language and image generation, directly translating such ideas to robotics has been challenging. One critical reason for this is that uncurated robot demonstration data, i.e. play data, collected from non-expert human demonstrators are often noisy, diverse, and distributionally multi-modal. This makes extracting useful, task-centric behaviors from such data a difficult generative modeling problem. In this work, we present Conditional Behavior Transformers (C-BeT), a method that combines the multi-modal generation ability of Behavior Transformer with future-conditioned goal specification. On a suite of simulated benchmark tasks, we find that C-BeT improves upon prior state-of-the-art work in learning from play data by an average of 45.7%. Further, we demonstrate for the first time that useful task-centric behaviors can be learned on a real-world robot purely from play data without any task labels or reward information. Robot videos are best viewed on our project website: https://play-to-policy.github.io