 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-GROP: Visually Grounded Robot Task and Motion Planning with Large Language Models
Nov 11, 2025Task planning and motion planning are two of the most important problems in robotics, where task planning methods help robots achieve high-level goals and motion planning methods maintain low-level feasibility. Task and motion planning (TAMP) methods interleave the two processes of task planning and motion planning to ensure goal achievement and motion feasibility. Within the TAMP context, we are concerned with the mobile manipulation (MoMa) of multiple objects, where it is necessary to interleave actions for navigation and manipulation. In particular, we aim to compute where and how each object should be placed given underspecified goals, such as ``set up dinner table with a fork, knife and plate.'' We leverage the rich common sense knowledge from large language models (LLMs), e.g., about how tableware is organized, to facilitate both task-level and motion-level planning. In addition, we use computer vision methods to learn a strategy for selecting base positions to facilitate MoMa behaviors, where the base position corresponds to the robot's ``footprint'' and orientation in its operating space. Altogether, this article provides a principled TAMP framework for MoMa tasks that accounts for common sense about object rearrangement and is adaptive to novel situations that include many objects that need to be moved. We performed quantitative experiments in both real-world settings and simulated environments. We evaluated the success rate and efficiency in completing long-horizon object rearrangement tasks. While the robot completed 84.4\% real-world object rearrangement trials, subjective human evaluations indicated that the robot's performance is still lower than experienced human waiters.
Cascaded Diffusion Models for Neural Motion Planning
May 21, 2025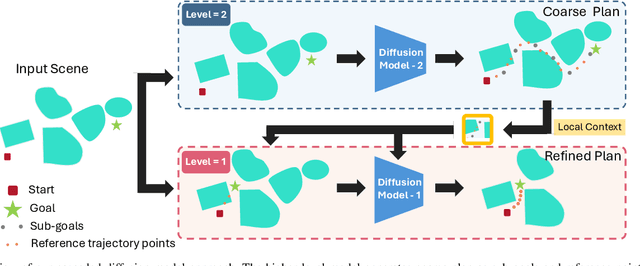

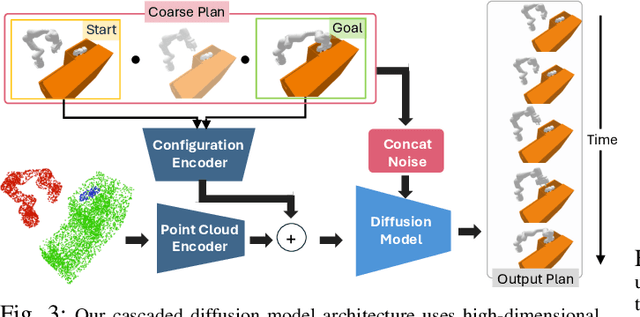
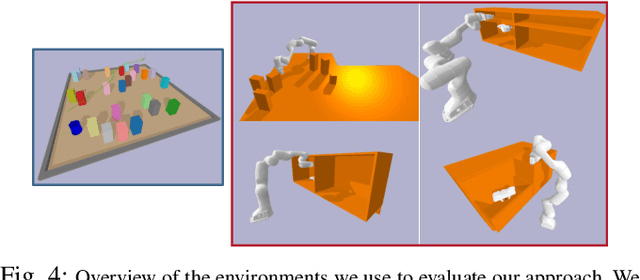
Robots in the real world need to perceive and move to goals in complex environments without collisions. Avoiding collisions is especially difficult when relying on sensor perception and when goals are among clutter. Diffusion policies and other generative models have shown strong performance in solving local planning problems, but often struggle at avoiding all of the subtle constraint violations that characterize truly challenging global motion planning problems. In this work, we propose an approach for learning global motion planning using diffusion policies, allowing the robot to generate full trajectories through complex scenes and reasoning about multiple obstacles along the path. Our approach uses cascaded hierarchical models which unify global prediction and local refinement together with online plan repair to ensure the trajectories are collision free. Our method outperforms (by ~5%) a wide variety of baselines on challenging tasks in multiple domains including navigation and manipulation.
GraphEQA: Using 3D Semantic Scene Graphs for Real-time Embodied Question Answering
Dec 19, 2024



In Embodied Question Answering (EQA), agents must explore and develop a semantic understanding of an unseen environment in order to answer a situated question with confidence. This remains a challenging problem in robotics, due to the difficulties in obtaining useful semantic representations, updating these representations online, and leveraging prior world knowledge for efficient exploration and planning. Aiming to address these limitations, we propose GraphEQA, a novel approach that utilizes real-time 3D metric-semantic scene graphs (3DSGs) and task relevant images as multi-modal memory for grounding Vision-Language Models (VLMs) to perform EQA tasks in unseen environments. We employ a hierarchical planning approach that exploits the hierarchical nature of 3DSGs for structured planning and semantic-guided exploration. Through experiments in simulation on the HM-EQA dataset and in the real world in home and office environments, we demonstrate that our method outperforms key baselines by completing EQA tasks with higher success rates and fewer planning steps.
DynaMem: Online Dynamic Spatio-Semantic Memory for Open World Mobile Manipulation
Nov 07, 2024

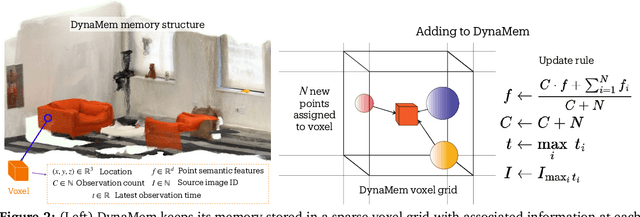
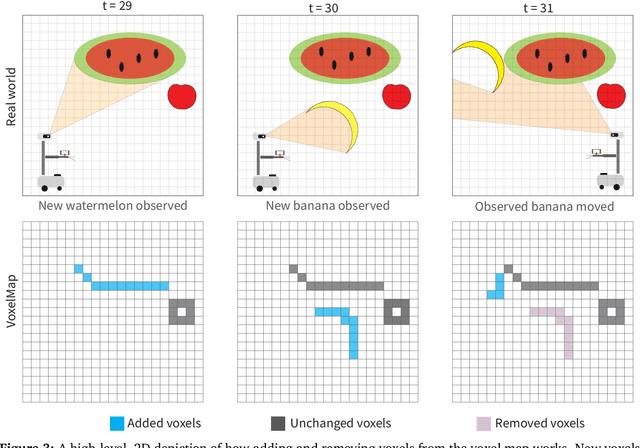
Significant progress has been made in open-vocabulary mobile manipulation, where the goal is for a robot to perform tasks in any environment given a natural language description. However, most current systems assume a static environment, which limits the system's applicability in real-world scenarios where environments frequently change due to human intervention or the robot's own actions. In this work, we present DynaMem, a new approach to open-world mobile manipulation that uses a dynamic spatio-semantic memory to represent a robot's environment. DynaMem constructs a 3D data structure to maintain a dynamic memory of point clouds, and answers open-vocabulary object localization queries using multimodal LLMs or open-vocabulary features generated by state-of-the-art vision-language models. Powered by DynaMem, our robots can explore novel environments, search for objects not found in memory, and continuously update the memory as objects move, appear, or disappear in the scene. We run extensive experiments on the Stretch SE3 robots in three real and nine offline scenes, and achieve an average pick-and-drop success rate of 70% on non-stationary objects, which is more than a 2x improvement over state-of-the-art static systems. Our code as well as our experiment and deployment videos are open sourced and can be found on our project website: https://dynamem.github.io/
Robot Utility Models: General Policies for Zero-Shot Deployment in New Environments
Sep 09, 2024Robot models, particularly those trained with large amounts of data, have recently shown a plethora of real-world manipulation and navigation capabilities. Several independent efforts have shown that given sufficient training data in an environment, robot policies can generalize to demonstrated variations in that environment. However, needing to finetune robot models to every new environment stands in stark contrast to models in language or vision that can be deployed zero-shot for open-world problems. In this work, we present Robot Utility Models (RUMs), a framework for training and deploying zero-shot robot policies that can directly generalize to new environments without any finetuning. To create RUMs efficiently, we develop new tools to quickly collect data for mobile manipulation tasks, integrate such data into a policy with multi-modal imitation learning, and deploy policies on-device on Hello Robot Stretch, a cheap commodity robot, with an external mLLM verifier for retrying. We train five such utility models for opening cabinet doors, opening drawers, picking up napkins, picking up paper bags, and reorienting fallen objects. Our system, on average, achieves 90% success rate in unseen, novel environments interacting with unseen objects. Moreover, the utility models can also succeed in different robot and camera set-ups with no further data, training, or fine-tuning. Primary among our lessons are the importance of training data over training algorithm and policy class, guidance about data scaling, necessity for diverse yet high-quality demonstrations, and a recipe for robot introspection and retrying to improve performance on individual environments. Our code, data, models, hardware designs, as well as our experiment and deployment videos are open sourced and can be found on our project website: https://robotutilitymodels.com
DegustaBot: Zero-Shot Visual Preference Estimation for Personalized Multi-Object Rearrangement
Jul 11, 2024De gustibus non est disputandum ("there is no accounting for others' tastes") is a common Latin maxim describing how many solutions in life are determined by people's personal preferences. Many household tasks, in particular, can only be considered fully successful when they account for personal preferences such as the visual aesthetic of the scene. For example, setting a table could be optimized by arranging utensils according to traditional rules of Western table setting decorum, without considering the color, shape, or material of each object, but this may not be a completely satisfying solution for a given person. Toward this end, we present DegustaBot, an algorithm for visual preference learning that solves household multi-object rearrangement tasks according to personal preference. To do this, we use internet-scale pre-trained vision-and-language foundation models (VLMs) with novel zero-shot visual prompting techniques. To evaluate our method, we collect a large dataset of naturalistic personal preferences in a simulated table-setting task, and conduct a user study in order to develop two novel metrics for determining success based on personal preference. This is a challenging problem and we find that 50% of our model's predictions are likely to be found acceptable by at least 20% of people.
HACMan++: Spatially-Grounded Motion Primitives for Manipulation
Jul 11, 2024



Although end-to-end robot learning has shown some success for robot manipulation, the learned policies are often not sufficiently robust to variations in object pose or geometry. To improve the policy generalization, we introduce spatially-grounded parameterized motion primitives in our method HACMan++. Specifically, we propose an action representation consisting of three components: what primitive type (such as grasp or push) to execute, where the primitive will be grounded (e.g. where the gripper will make contact with the world), and how the primitive motion is executed, such as parameters specifying the push direction or grasp orientation. These three components define a novel discrete-continuous action space for reinforcement learning. Our framework enables robot agents to learn to chain diverse motion primitives together and select appropriate primitive parameters to complete long-horizon manipulation tasks. By grounding the primitives on a spatial location in the environment, our method is able to effectively generalize across object shape and pose variations. Our approach significantly outperforms existing methods, particularly in complex scenarios demanding both high-level sequential reasoning and object generalization. With zero-shot sim-to-real transfer, our policy succeeds in challenging real-world manipulation tasks, with generalization to unseen objects. Videos can be found on the project website: https://sgmp-rss2024.github.io.
Towards Open-World Mobile Manipulation in Homes: Lessons from the Neurips 2023 HomeRobot Open Vocabulary Mobile Manipulation Challenge
Jul 09, 2024



In order to develop robots that can effectively serve as versatile and capable home assistants, it is crucial for them to reliably perceive and interact with a wide variety of objects across diverse environments. To this end, we proposed Open Vocabulary Mobile Manipulation as a key benchmark task for robotics: finding any object in a novel environment and placing it on any receptacle surface within that environment. We organized a NeurIPS 2023 competition featuring both simulation and real-world components to evaluate solutions to this task. Our baselines on the most challenging version of this task, using real perception in simulation, achieved only an 0.8% success rate; by the end of the competition, the best participants achieved an 10.8\% success rate, a 13x improvement. We observed that the most successful teams employed a variety of methods, yet two common threads emerged among the best solutions: enhancing error detection and recovery, and improving the integration of perception with decision-making processes. In this paper, we detail the results and methodologies used, both in simulation and real-world settings. We discuss the lessons learned and their implications for future research. Additionally, we compare performance in real and simulated environments, emphasizing the necessity for robust generalization to novel settings.
Bootstrapping Linear Models for Fast Online Adaptation in Human-Agent Collaboration
Apr 16, 2024Agents that assist people need to have well-initialized policies that can adapt quickly to align with their partners' reward functions. Initializing policies to maximize performance with unknown partners can be achieved by bootstrapping nonlinear models using imitation learning over large, offline datasets. Such policies can require prohibitive computation to fine-tune in-situ and therefore may miss critical run-time information about a partner's reward function as expressed through their immediate behavior. In contrast, online logistic regression using low-capacity models performs rapid inference and fine-tuning updates and thus can make effective use of immediate in-task behavior for reward function alignment. However, these low-capacity models cannot be bootstrapped as effectively by offline datasets and thus have poor initializations. We propose BLR-HAC, Bootstrapped Logistic Regression for Human Agent Collaboration, which bootstraps large nonlinear models to learn the parameters of a low-capacity model which then uses online logistic regression for updates during collaboration. We test BLR-HAC in a simulated surface rearrangement task and demonstrate that it achieves higher zero-shot accuracy than shallow methods and takes far less computation to adapt online while still achieving similar performance to fine-tuned, large nonlinear models. For code, please see our project page https://sites.google.com/view/blr-hac.
Real-World Robot Applications of Foundation Models: A Review
Feb 08, 2024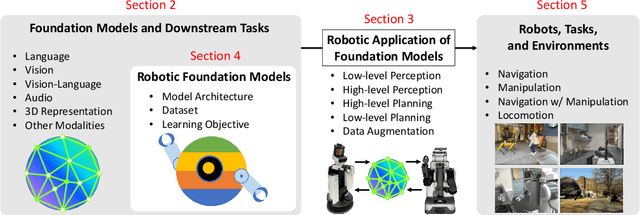
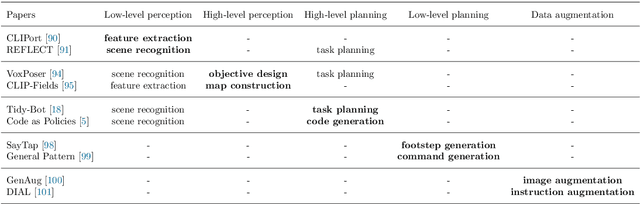
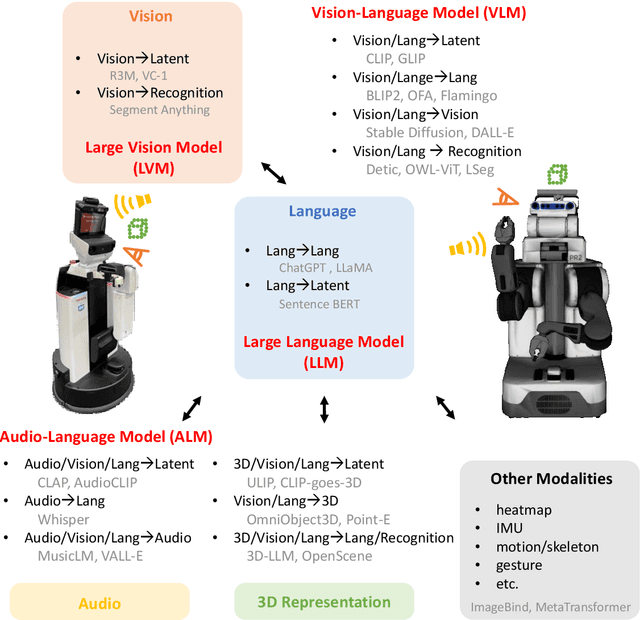
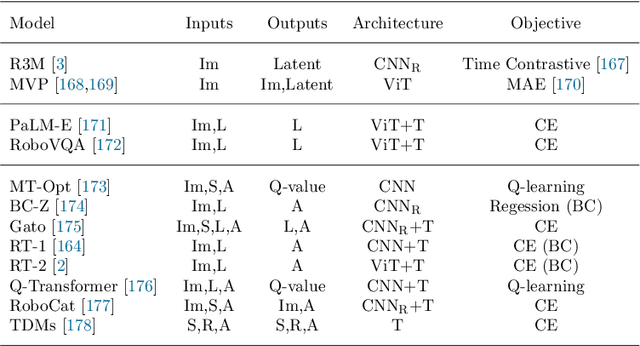
Recent developments in foundation models, like Large Language Models (LLMs) and Vision-Language Models (VLMs), trained on extensive data, facilitate flexible application across different tasks and modalities. Their impact spans various fields, including healthcare, education, and robotics. This paper provides an overview of the practical application of foundation models in real-world robotics, with a primary emphasis on the replacement of specific components within existing robot systems. The summary encompasses the perspective of input-output relationships in foundation models, as well as their role in perception, motion planning, and control within the field of robotics. This paper concludes with a discussion of future challenges and implications for practical robot applications.