 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Optimal Steering to Achieve Exact Fairness
Sep 19, 2025To fix the 'bias in, bias out' problem in fair machine learning, it is important to steer feature distributions of data or internal representations of Large Language Models (LLMs) to ideal ones that guarantee group-fair outcomes. Previous work on fair generative models and representation steering could greatly benefit from provable fairness guarantees on the model output. We define a distribution as ideal if the minimizer of any cost-sensitive risk on it is guaranteed to have exact group-fair outcomes (e.g., demographic parity, equal opportunity)-in other words, it has no fairness-utility trade-off. We formulate an optimization program for optimal steering by finding the nearest ideal distribution in KL-divergence, and provide efficient algorithms for it when the underlying distributions come from well-known parametric families (e.g., normal, log-normal). Empirically, our optimal steering techniques on both synthetic and real-world datasets improve fairness without diminishing utility (and sometimes even improve utility). We demonstrate affine steering of LLM representations to reduce bias in multi-class classification, e.g., occupation prediction from a short biography in Bios dataset (De-Arteaga et al.). Furthermore, we steer internal representations of LLMs towards desired outputs so that it works equally well across different groups.
Cascaded Diffusion Models for Neural Motion Planning
May 21, 2025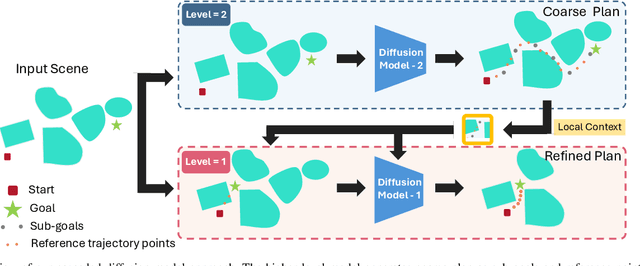

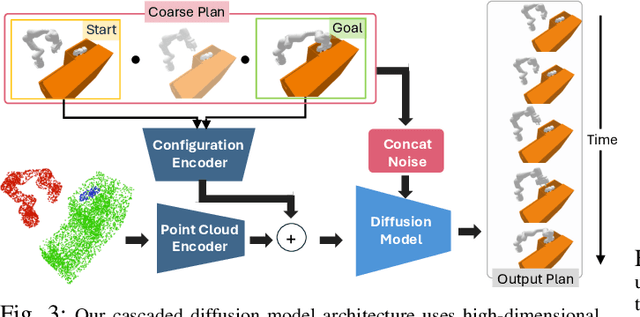
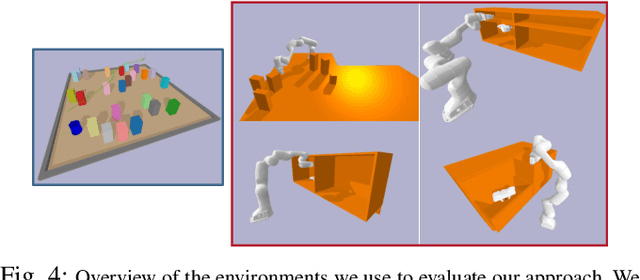
Robots in the real world need to perceive and move to goals in complex environments without collisions. Avoiding collisions is especially difficult when relying on sensor perception and when goals are among clutter. Diffusion policies and other generative models have shown strong performance in solving local planning problems, but often struggle at avoiding all of the subtle constraint violations that characterize truly challenging global motion planning problems. In this work, we propose an approach for learning global motion planning using diffusion policies, allowing the robot to generate full trajectories through complex scenes and reasoning about multiple obstacles along the path. Our approach uses cascaded hierarchical models which unify global prediction and local refinement together with online plan repair to ensure the trajectories are collision free. Our method outperforms (by ~5%) a wide variety of baselines on challenging tasks in multiple domains including navigation and manipulation.
Gemini Robotics: Bringing AI into the Physical World
Mar 25, 2025Recent advancements in large multimodal models have led to the emergence of remarkable generalist capabilities in digital domains, yet their translation to physical agents such as robots remains a significant challenge. This report introduces a new family of AI models purposefully designed for robotics and built upon the foundation of Gemini 2.0. We present Gemini Robotics, an advanced Vision-Language-Action (VLA) generalist model capable of directly controlling robots. Gemini Robotics executes smooth and reactive movements to tackle a wide range of complex manipulation tasks while also being robust to variations in object types and positions, handling unseen environments as well as following diverse, open vocabulary instructions. We show that with additional fine-tuning, Gemini Robotics can be specialized to new capabilities including solving long-horizon, highly dexterous tasks, learning new short-horizon tasks from as few as 100 demonstrations and adapting to completely novel robot embodiments. This is made possible because Gemini Robotics builds on top of the Gemini Robotics-ER model, the second model we introduce in this work. Gemini Robotics-ER (Embodied Reasoning) extends Gemini's multimodal reasoning capabilities into the physical world, with enhanced spatial and temporal understanding. This enables capabilities relevant to robotics including object detection, pointing, trajectory and grasp prediction, as well as multi-view correspondence and 3D bounding box predictions. We show how this novel combination can support a variety of robotics applications. We also discuss and address important safety considerations related to this new class of robotics foundation models. The Gemini Robotics family marks a substantial step towards developing general-purpose robots that realizes AI's potential in the physical world.
Predictive Red Teaming: Breaking Policies Without Breaking Robots
Feb 10, 2025Visuomotor policies trained via imitation learning are capable of performing challenging manipulation tasks, but are often extremely brittle to lighting, visual distractors, and object locations. These vulnerabilities can depend unpredictably on the specifics of training, and are challenging to expose without time-consuming and expensive hardware evaluations. We propose the problem of predictive red teaming: discovering vulnerabilities of a policy with respect to environmental factors, and predicting the corresponding performance degradation without hardware evaluations in off-nominal scenarios. In order to achieve this, we develop RoboART: an automated red teaming (ART) pipeline that (1) modifies nominal observations using generative image editing to vary different environmental factors, and (2) predicts performance under each variation using a policy-specific anomaly detector executed on edited observations. Experiments across 500+ hardware trials in twelve off-nominal conditions for visuomotor diffusion policies demonstrate that RoboART predicts performance degradation with high accuracy (less than 0.19 average difference between predicted and real success rates). We also demonstrate how predictive red teaming enables targeted data collection: fine-tuning with data collected under conditions predicted to be adverse boosts baseline performance by 2-7x.
Learning the RoPEs: Better 2D and 3D Position Encodings with STRING
Feb 04, 2025



We introduce STRING: Separable Translationally Invariant Position Encodings. STRING extends Rotary Position Encodings, a recently proposed and widely used algorithm in large language models, via a unifying theoretical framework. Importantly, STRING still provides exact translation invariance, including token coordinates of arbitrary dimensionality, whilst maintaining a low computational footprint. These properties are especially important in robotics, where efficient 3D token representation is key. We integrate STRING into Vision Transformers with RGB(-D) inputs (color plus optional depth), showing substantial gains, e.g. in open-vocabulary object detection and for robotics controllers. We complement our experiments with a rigorous mathematical analysis, proving the universality of our methods.
Gen-AI for User Safety: A Survey
Nov 22, 2024Machine Learning and data mining techniques (i.e. supervised and unsupervised techniques) are used across domains to detect user safety violations. Examples include classifiers used to detect whether an email is spam or a web-page is requesting bank login information. However, existing ML/DM classifiers are limited in their ability to understand natural languages w.r.t the context and nuances. The aforementioned challenges are overcome with the arrival of Gen-AI techniques, along with their inherent ability w.r.t translation between languages, fine-tuning between various tasks and domains. In this manuscript, we provide a comprehensive overview of the various work done while using Gen-AI techniques w.r.t user safety. In particular, we first provide the various domains (e.g. phishing, malware, content moderation, counterfeit, physical safety) across which Gen-AI techniques have been applied. Next, we provide how Gen-AI techniques can be used in conjunction with various data modalities i.e. text, images, videos, audio, executable binaries to detect violations of user-safety. Further, also provide an overview of how Gen-AI techniques can be used in an adversarial setting. We believe that this work represents the first summarization of Gen-AI techniques for user-safety.
Semantically Controllable Augmentations for Generalizable Robot Learning
Sep 02, 2024



Generalization to unseen real-world scenarios for robot manipulation requires exposure to diverse datasets during training. However, collecting large real-world datasets is intractable due to high operational costs. For robot learning to generalize despite these challenges, it is essential to leverage sources of data or priors beyond the robot's direct experience. In this work, we posit that image-text generative models, which are pre-trained on large corpora of web-scraped data, can serve as such a data source. These generative models encompass a broad range of real-world scenarios beyond a robot's direct experience and can synthesize novel synthetic experiences that expose robotic agents to additional world priors aiding real-world generalization at no extra cost. In particular, our approach leverages pre-trained generative models as an effective tool for data augmentation. We propose a generative augmentation framework for semantically controllable augmentations and rapidly multiplying robot datasets while inducing rich variations that enable real-world generalization. Based on diverse augmentations of robot data, we show how scalable robot manipulation policies can be trained and deployed both in simulation and in unseen real-world environments such as kitchens and table-tops. By demonstrating the effectiveness of image-text generative models in diverse real-world robotic applications, our generative augmentation framework provides a scalable and efficient path for boosting generalization in robot learning at no extra human cost.
MResT: Multi-Resolution Sensing for Real-Time Control with Vision-Language Models
Jan 25, 2024Leveraging sensing modalities across diverse spatial and temporal resolutions can improve performance of robotic manipulation tasks. Multi-spatial resolution sensing provides hierarchical information captured at different spatial scales and enables both coarse and precise motions. Simultaneously multi-temporal resolution sensing enables the agent to exhibit high reactivity and real-time control. In this work, we propose a framework, MResT (Multi-Resolution Transformer), for learning generalizable language-conditioned multi-task policies that utilize sensing at different spatial and temporal resolutions using networks of varying capacities to effectively perform real time control of precise and reactive tasks. We leverage off-the-shelf pretrained vision-language models to operate on low-frequency global features along with small non-pretrained models to adapt to high frequency local feedback. Through extensive experiments in 3 domains (coarse, precise and dynamic manipulation tasks), we show that our approach significantly improves (2X on average) over recent multi-task baselines. Further, our approach generalizes well to visual and geometric variations in target objects and to varying interaction forces.
How Far Can Fairness Constraints Help Recover From Biased Data?
Dec 16, 2023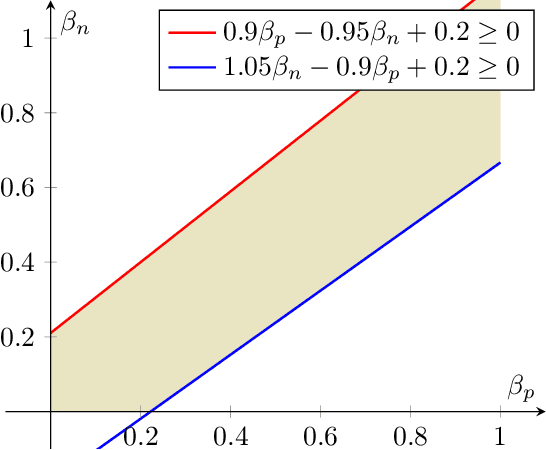
Blum & Stangl (2019) propose a data bias model to simulate under-representation and label bias in underprivileged population. For a stylized data distribution with i.i.d. label noise, under certain simple conditions on the bias parameters, they show that fair classification with equal opportunity constraints even on extremely biased distribution can recover an optimally accurate and fair classifier on the original distribution. Although their distribution is stylized, their result is interesting because it demonstrates that fairness constraints can implicitly rectify data bias and simultaneously overcome a perceived fairness-accuracy trade-off. In this paper, we give an alternate proof of their result using threshold-based characterization of optimal fair classifiers. Moreover, we show that their conditions on the bias parameters are both necessary and sufficient for their recovery result. Our technique is arguably more flexible, as it readily extends to more general distributions, e.g., when the labels in the original distribution have Massart noise instead of i.i.d. noise. Finally, we prove that for any data distribution, if the optimally accurate classifier in a hypothesis class is fair and robust, then it can be recovered through fair classification on the biased distribution, whenever the bias parameters satisfy certain simple conditions.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.