 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDexMachina: Functional Retargeting for Bimanual Dexterous Manipulation
May 30, 2025We study the problem of functional retargeting: learning dexterous manipulation policies to track object states from human hand-object demonstrations. We focus on long-horizon, bimanual tasks with articulated objects, which is challenging due to large action space, spatiotemporal discontinuities, and embodiment gap between human and robot hands. We propose DexMachina, a novel curriculum-based algorithm: the key idea is to use virtual object controllers with decaying strength: an object is first driven automatically towards its target states, such that the policy can gradually learn to take over under motion and contact guidance. We release a simulation benchmark with a diverse set of tasks and dexterous hands, and show that DexMachina significantly outperforms baseline methods. Our algorithm and benchmark enable a functional comparison for hardware designs, and we present key findings informed by quantitative and qualitative results. With the recent surge in dexterous hand development, we hope this work will provide a useful platform for identifying desirable hardware capabilities and lower the barrier for contributing to future research. Videos and more at https://project-dexmachina.github.io/
Semantically Controllable Augmentations for Generalizable Robot Learning
Sep 02, 2024



Generalization to unseen real-world scenarios for robot manipulation requires exposure to diverse datasets during training. However, collecting large real-world datasets is intractable due to high operational costs. For robot learning to generalize despite these challenges, it is essential to leverage sources of data or priors beyond the robot's direct experience. In this work, we posit that image-text generative models, which are pre-trained on large corpora of web-scraped data, can serve as such a data source. These generative models encompass a broad range of real-world scenarios beyond a robot's direct experience and can synthesize novel synthetic experiences that expose robotic agents to additional world priors aiding real-world generalization at no extra cost. In particular, our approach leverages pre-trained generative models as an effective tool for data augmentation. We propose a generative augmentation framework for semantically controllable augmentations and rapidly multiplying robot datasets while inducing rich variations that enable real-world generalization. Based on diverse augmentations of robot data, we show how scalable robot manipulation policies can be trained and deployed both in simulation and in unseen real-world environments such as kitchens and table-tops. By demonstrating the effectiveness of image-text generative models in diverse real-world robotic applications, our generative augmentation framework provides a scalable and efficient path for boosting generalization in robot learning at no extra human cost.
Real2Code: Reconstruct Articulated Objects via Code Generation
Jun 12, 2024



We present Real2Code, a novel approach to reconstructing articulated objects via code generation. Given visual observations of an object, we first reconstruct its part geometry using an image segmentation model and a shape completion model. We then represent the object parts with oriented bounding boxes, which are input to a fine-tuned large language model (LLM) to predict joint articulation as code. By leveraging pre-trained vision and language models, our approach scales elegantly with the number of articulated parts, and generalizes from synthetic training data to real world objects in unstructured environments. Experimental results demonstrate that Real2Code significantly outperforms previous state-of-the-art in reconstruction accuracy, and is the first approach to extrapolate beyond objects' structural complexity in the training set, and reconstructs objects with up to 10 articulated parts. When incorporated with a stereo reconstruction model, Real2Code also generalizes to real world objects from a handful of multi-view RGB images, without the need for depth or camera information.
MD-Splatting: Learning Metric Deformation from 4D Gaussians in Highly Deformable Scenes
Nov 30, 2023



Accurate 3D tracking in highly deformable scenes with occlusions and shadows can facilitate new applications in robotics, augmented reality, and generative AI. However, tracking under these conditions is extremely challenging due to the ambiguity that arises with large deformations, shadows, and occlusions. We introduce MD-Splatting, an approach for simultaneous 3D tracking and novel view synthesis, using video captures of a dynamic scene from various camera poses. MD-Splatting builds on recent advances in Gaussian splatting, a method that learns the properties of a large number of Gaussians for state-of-the-art and fast novel view synthesis. MD-Splatting learns a deformation function to project a set of Gaussians with non-metric, thus canonical, properties into metric space. The deformation function uses a neural-voxel encoding and a multilayer perceptron (MLP) to infer Gaussian position, rotation, and a shadow scalar. We enforce physics-inspired regularization terms based on local rigidity, conservation of momentum, and isometry, which leads to trajectories with smaller trajectory errors. MD-Splatting achieves high-quality 3D tracking on highly deformable scenes with shadows and occlusions. Compared to state-of-the-art, we improve 3D tracking by an average of 23.9 %, while simultaneously achieving high-quality novel view synthesis. With sufficient texture such as in scene 6, MD-Splatting achieves a median tracking error of 3.39 mm on a cloth of 1 x 1 meters in size. Project website: https://md-splatting.github.io/.
RoCo: Dialectic Multi-Robot Collaboration with Large Language Models
Jul 10, 2023We propose a novel approach to multi-robot collaboration that harnesses the power of pre-trained large language models (LLMs) for both high-level communication and low-level path planning. Robots are equipped with LLMs to discuss and collectively reason task strategies. They then generate sub-task plans and task space waypoint paths, which are used by a multi-arm motion planner to accelerate trajectory planning. We also provide feedback from the environment, such as collision checking, and prompt the LLM agents to improve their plan and waypoints in-context. For evaluation, we introduce RoCoBench, a 6-task benchmark covering a wide range of multi-robot collaboration scenarios, accompanied by a text-only dataset for agent representation and reasoning. We experimentally demonstrate the effectiveness of our approach -- it achieves high success rates across all tasks in RoCoBench and adapts to variations in task semantics. Our dialog setup offers high interpretability and flexibility -- in real world experiments, we show RoCo easily incorporates human-in-the-loop, where a user can communicate and collaborate with a robot agent to complete tasks together. See project website https://project-roco.github.io for videos and code.
CACTI: A Framework for Scalable Multi-Task Multi-Scene Visual Imitation Learning
Dec 12, 2022Developing robots that are capable of many skills and generalization to unseen scenarios requires progress on two fronts: efficient collection of large and diverse datasets, and training of high-capacity policies on the collected data. While large datasets have propelled progress in other fields like computer vision and natural language processing, collecting data of comparable scale is particularly challenging for physical systems like robotics. In this work, we propose a framework to bridge this gap and better scale up robot learning, under the lens of multi-task, multi-scene robot manipulation in kitchen environments. Our framework, named CACTI, has four stages that separately handle data collection, data augmentation, visual representation learning, and imitation policy training. In the CACTI framework, we highlight the benefit of adapting state-of-the-art models for image generation as part of the augmentation stage, and the significant improvement of training efficiency by using pretrained out-of-domain visual representations at the compression stage. Experimentally, we demonstrate that 1) on a real robot setup, CACTI enables efficient training of a single policy capable of 10 manipulation tasks involving kitchen objects, and robust to varying layouts of distractor objects; 2) in a simulated kitchen environment, CACTI trains a single policy on 18 semantic tasks across up to 50 layout variations per task. The simulation task benchmark and augmented datasets in both real and simulated environments will be released to facilitate future research.
On the Effectiveness of Fine-tuning Versus Meta-reinforcement Learning
Jun 07, 2022



Intelligent agents should have the ability to leverage knowledge from previously learned tasks in order to learn new ones quickly and efficiently. Meta-learning approaches have emerged as a popular solution to achieve this. However, meta-reinforcement learning (meta-RL) algorithms have thus far been restricted to simple environments with narrow task distributions. Moreover, the paradigm of pretraining followed by fine-tuning to adapt to new tasks has emerged as a simple yet effective solution in supervised and self-supervised learning. This calls into question the benefits of meta-learning approaches also in reinforcement learning, which typically come at the cost of high complexity. We hence investigate meta-RL approaches in a variety of vision-based benchmarks, including Procgen, RLBench, and Atari, where evaluations are made on completely novel tasks. Our findings show that when meta-learning approaches are evaluated on different tasks (rather than different variations of the same task), multi-task pretraining with fine-tuning on new tasks performs equally as well, or better, than meta-pretraining with meta test-time adaptation. This is encouraging for future research, as multi-task pretraining tends to be simpler and computationally cheaper than meta-RL. From these findings, we advocate for evaluating future meta-RL methods on more challenging tasks and including multi-task pretraining with fine-tuning as a simple, yet strong baseline.
Towards More Generalizable One-shot Visual Imitation Learning
Oct 26, 2021

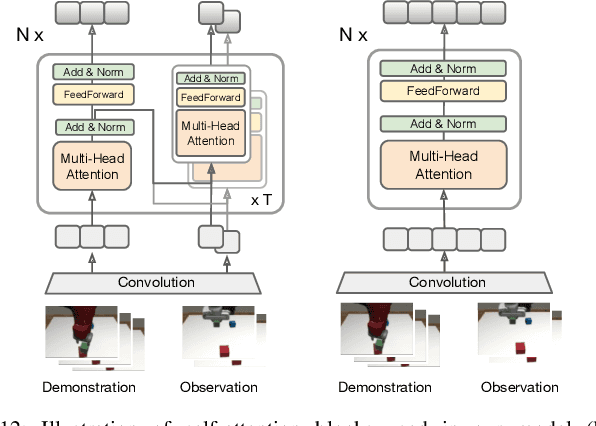

A general-purpose robot should be able to master a wide range of tasks and quickly learn a novel one by leveraging past experiences. One-shot imitation learning (OSIL) approaches this goal by training an agent with (pairs of) expert demonstrations, such that at test time, it can directly execute a new task from just one demonstration. However, so far this framework has been limited to training on many variations of one task, and testing on other unseen but similar variations of the same task. In this work, we push for a higher level of generalization ability by investigating a more ambitious multi-task setup. We introduce a diverse suite of vision-based robot manipulation tasks, consisting of 7 tasks, a total of 61 variations, and a continuum of instances within each variation. For consistency and comparison purposes, we first train and evaluate single-task agents (as done in prior few-shot imitation work). We then study the multi-task setting, where multi-task training is followed by (i) one-shot imitation on variations within the training tasks, (ii) one-shot imitation on new tasks, and (iii) fine-tuning on new tasks. Prior state-of-the-art, while performing well within some single tasks, struggles in these harder multi-task settings. To address these limitations, we propose MOSAIC (Multi-task One-Shot Imitation with self-Attention and Contrastive learning), which integrates a self-attention model architecture and a temporal contrastive module to enable better task disambiguation and more robust representation learning. Our experiments show that MOSAIC outperforms prior state of the art in learning efficiency, final performance, and learns a multi-task policy with promising generalization ability via fine-tuning on novel tasks.
DCUR: Data Curriculum for Teaching via Samples with Reinforcement Learning
Sep 15, 2021
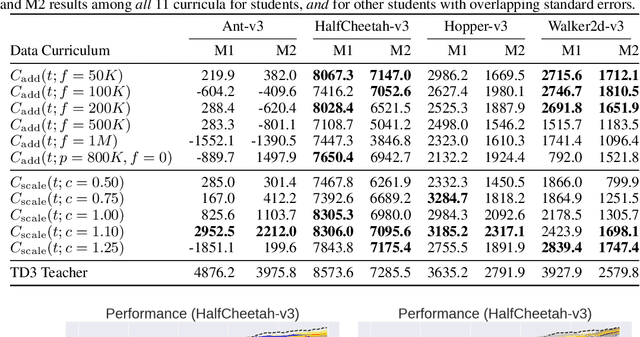
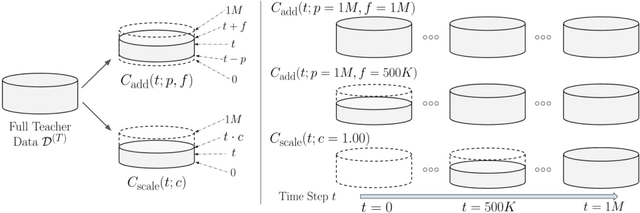

Deep reinforcement learning (RL) has shown great empirical successes, but suffers from brittleness and sample inefficiency. A potential remedy is to use a previously-trained policy as a source of supervision. In this work, we refer to these policies as teachers and study how to transfer their expertise to new student policies by focusing on data usage. We propose a framework, Data CUrriculum for Reinforcement learning (DCUR), which first trains teachers using online deep RL, and stores the logged environment interaction history. Then, students learn by running either offline RL or by using teacher data in combination with a small amount of self-generated data. DCUR's central idea involves defining a class of data curricula which, as a function of training time, limits the student to sampling from a fixed subset of the full teacher data. We test teachers and students using state-of-the-art deep RL algorithms across a variety of data curricula. Results suggest that the choice of data curricula significantly impacts student learning, and that it is beneficial to limit the data during early training stages while gradually letting the data availability grow over time. We identify when the student can learn offline and match teacher performance without relying on specialized offline RL algorithms. Furthermore, we show that collecting a small fraction of online data provides complementary benefits with the data curriculum. Supplementary material is available at https://tinyurl.com/teach-dcur.