 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA-SLIP: Acoustic Sensing for Continuous In-hand Slip Estimation
Apr 09, 2026Reliable in-hand manipulation requires accurate real-time estimation of slip between a gripper and a grasped object. Existing tactile sensing approaches based on vision, capacitance, or force-torque measurements face fundamental trade-offs in form factor, durability, and their ability to jointly estimate slip direction and magnitude. We present A-SLIP, a multi-channel acoustic sensing system integrated into a parallel-jaw gripper for estimating continuous slip in the grasp plane. The A-SLIP sensor consists of piezoelectric microphones positioned behind a textured silicone contact pad to capture structured contact-induced vibrations. The A-SLIP model processes synchronized multi-channel audio as log-mel spectrograms using a lightweight convolutional network, jointly predicting the presence, direction, and magnitude of slip. Across experiments with robot- and externally induced slip conditions, the fine-tuned four-microphone configuration achieves a mean absolute directional error of 14.1 degrees, outperforms baselines by up to 12 percent in detection accuracy, and reduces directional error by 32 percent. Compared with single-microphone configurations, the multi-channel design reduces directional error by 64 percent and magnitude error by 68 percent, underscoring the importance of spatial acoustic sensing in resolving slip direction ambiguity. We further evaluate A-SLIP in closed-loop reactive control and find that it enables reliable, low-cost, real-time estimation of in-hand slip. Project videos and additional details are available at https://a-slip.github.io.
Functional Force-Aware Retargeting from Virtual Human Demos to Soft Robot Policies
Apr 01, 2026We introduce SoftAct, a framework for teaching soft robot hands to perform human-like manipulation skills by explicitly reasoning about contact forces. Leveraging immersive virtual reality, our system captures rich human demonstrations, including hand kinematics, object motion, dense contact patches, and detailed contact force information. Unlike conventional approaches that retarget human joint trajectories, SoftAct employs a two-stage, force-aware retargeting algorithm. The first stage attributes demonstrated contact forces to individual human fingers and allocates robot fingers proportionally, establishing a force-balanced mapping between human and robot hands. The second stage performs online retargeting by combining baseline end-effector pose tracking with geodesic-weighted contact refinements, using contact geometry and force magnitude to adjust robot fingertip targets in real time. This formulation enables soft robotic hands to reproduce the functional intent of human demonstrations while naturally accommodating extreme embodiment mismatch and nonlinear compliance. We evaluate SoftAct on a suite of contact-rich manipulation tasks using a custom non-anthropomorphic pneumatic soft robot hand. SoftAct's controller reduces fingertip trajectory tracking RMSE by up to 55 percent and reduces tracking variance by up to 69 percent compared to kinematic and learning-based baselines. At the policy level, SoftAct achieves consistently higher success in zero-shot real-world deployment and in simulation. These results demonstrate that explicitly modeling contact geometry and force distribution is essential for effective skill transfer to soft robotic hands, and cannot be recovered through kinematic imitation alone. Project videos and additional details are available at https://soft-act.github.io/.
SOFTMAP: Sim2Real Soft Robot Forward Modeling via Topological Mesh Alignment and Physics Prior
Mar 19, 2026While soft robot manipulators offer compelling advantages over rigid counterparts, including inherent compliance, safe human-robot interaction, and the ability to conform to complex geometries, accurate forward modeling from low-dimensional actuation commands remains an open challenge due to nonlinear material phenomena such as hysteresis and manufacturing variability. We present SOFTMAP, a sim-to-real learning framework for real-time 3D forward modeling of tendon-actuated soft finger manipulators. SOFTMAP combines four components: (1) As-Rigid-As-Possible (ARAP)-based topological alignment that projects simulated and real point clouds into a shared, topologically consistent vertex space; (2) a lightweight MLP forward model pretrained on simulation data to map servo commands to full 3D finger geometry; (3) a residual correction network trained on a small set of real observations to predict per-vertex displacement fields that compensate for sim-to-real discrepancies; and (4) a closed-form linear actuation calibration layer enabling real-time inference at 30 FPS. We evaluate SOFTMAP on both simulated and physical hardware, achieving state-of-the-art shape prediction accuracy with a Chamfer distance of 0.389 mm in simulation and 3.786 mm on hardware, millimeter-level fingertip trajectory tracking across multiple target paths, and a 36.5% improvement in teleoperation task success over the baseline. Our results show that SOFTMAP provides a data-efficient approach for 3D forward modeling and control of soft manipulators.
3PoinTr: 3D Point Tracks for Robot Manipulation Pretraining from Casual Videos
Mar 09, 2026Data-efficient training of robust robot policies is the key to unlocking automation in a wide array of novel tasks. Current systems require large volumes of demonstrations to achieve robustness, which is impractical in many applications. Learning policies directly from human videos is a promising alternative that removes teleoperation costs, but it shifts the challenge toward overcoming the embodiment gap (differences in kinematics and strategies between robots and humans), often requiring restrictive and carefully choreographed human motions. We propose 3PoinTr, a method for pretraining robot policies from casual and unconstrained human videos, enabling learning from motions natural for humans. 3PoinTr uses a transformer architecture to predict 3D point tracks as an intermediate embodiment-agnostic representation. 3D point tracks encode goal specifications, scene geometry, and spatiotemporal relationships. We use a Perceiver IO architecture to extract a compact representation for sample-efficient behavior cloning, even when point tracks violate downstream embodiment-specific constraints. We conduct thorough evaluation on simulated and real-world tasks, and find that 3PoinTr achieves robust spatial generalization on diverse categories of manipulation tasks with only 20 action-labeled robot demonstrations. 3PoinTr outperforms the baselines, including behavior cloning methods, as well as prior methods for pretraining from human videos. We also provide evaluations of 3PoinTr's 3D point track predictions compared to an existing point track prediction baseline. We find that 3PoinTr produces more accurate and higher quality point tracks due to a lightweight yet expressive architecture built on a single transformer, in addition to a training formulation that preserves supervision of partially occluded points. Project page: https://adamhung60.github.io/3PoinTr/.
Dexterous Manipulation Policies from RGB Human Videos via 4D Hand-Object Trajectory Reconstruction
Feb 09, 2026Multi-finger robotic hand manipulation and grasping are challenging due to the high-dimensional action space and the difficulty of acquiring large-scale training data. Existing approaches largely rely on human teleoperation with wearable devices or specialized sensing equipment to capture hand-object interactions, which limits scalability. In this work, we propose VIDEOMANIP, a device-free framework that learns dexterous manipulation directly from RGB human videos. Leveraging recent advances in computer vision, VIDEOMANIP reconstructs explicit 4D robot-object trajectories from monocular videos by estimating human hand poses, object meshes, and retargets the reconstructed human motions to robotic hands for manipulation learning. To make the reconstructed robot data suitable for dexterous manipulation training, we introduce hand-object contact optimization with interaction-centric grasp modeling, as well as a demonstration synthesis strategy that generates diverse training trajectories from a single video, enabling generalizable policy learning without additional robot demonstrations. In simulation, the learned grasping model achieves a 70.25% success rate across 20 diverse objects using the Inspire Hand. In the real world, manipulation policies trained from RGB videos achieve an average 62.86% success rate across seven tasks using the LEAP Hand, outperforming retargeting-based methods by 15.87%. Project videos are available at videomanip.github.io.
Adversarial Game-Theoretic Algorithm for Dexterous Grasp Synthesis
Nov 08, 2025For many complex tasks, multi-finger robot hands are poised to revolutionize how we interact with the world, but reliably grasping objects remains a significant challenge. We focus on the problem of synthesizing grasps for multi-finger robot hands that, given a target object's geometry and pose, computes a hand configuration. Existing approaches often struggle to produce reliable grasps that sufficiently constrain object motion, leading to instability under disturbances and failed grasps. A key reason is that during grasp generation, they typically focus on resisting a single wrench, while ignoring the object's potential for adversarial movements, such as escaping. We propose a new grasp-synthesis approach that explicitly captures and leverages the adversarial object motion in grasp generation by formulating the problem as a two-player game. One player controls the robot to generate feasible grasp configurations, while the other adversarially controls the object to seek motions that attempt to escape from the grasp. Simulation experiments on various robot platforms and target objects show that our approach achieves a success rate of 75.78%, up to 19.61% higher than the state-of-the-art baseline. The two-player game mechanism improves the grasping success rate by 27.40% over the method without the game formulation. Our approach requires only 0.28-1.04 seconds on average to generate a grasp configuration, depending on the robot platform, making it suitable for real-world deployment. In real-world experiments, our approach achieves an average success rate of 85.0% on ShadowHand and 87.5% on LeapHand, which confirms its feasibility and effectiveness in real robot setups.
ORB: Operating Room Bot, Automating Operating Room Logistics through Mobile Manipulation
Sep 19, 2025
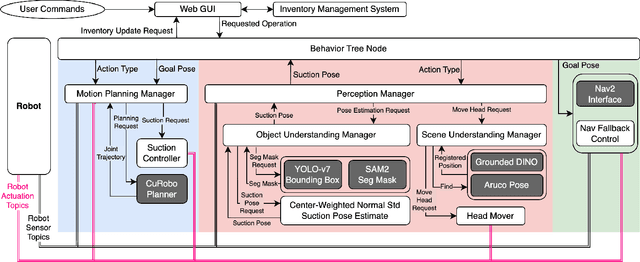


Efficiently delivering items to an ongoing surgery in a hospital operating room can be a matter of life or death. In modern hospital settings, delivery robots have successfully transported bulk items between rooms and floors. However, automating item-level operating room logistics presents unique challenges in perception, efficiency, and maintaining sterility. We propose the Operating Room Bot (ORB), a robot framework to automate logistics tasks in hospital operating rooms (OR). ORB leverages a robust, hierarchical behavior tree (BT) architecture to integrate diverse functionalities of object recognition, scene interpretation, and GPU-accelerated motion planning. The contributions of this paper include: (1) a modular software architecture facilitating robust mobile manipulation through behavior trees; (2) a novel real-time object recognition pipeline integrating YOLOv7, Segment Anything Model 2 (SAM2), and Grounded DINO; (3) the adaptation of the cuRobo parallelized trajectory optimization framework to real-time, collision-free mobile manipulation; and (4) empirical validation demonstrating an 80% success rate in OR supply retrieval and a 96% success rate in restocking operations. These contributions establish ORB as a reliable and adaptable system for autonomous OR logistics.
Hearing the Slide: Acoustic-Guided Constraint Learning for Fast Non-Prehensile Transport
Jun 10, 2025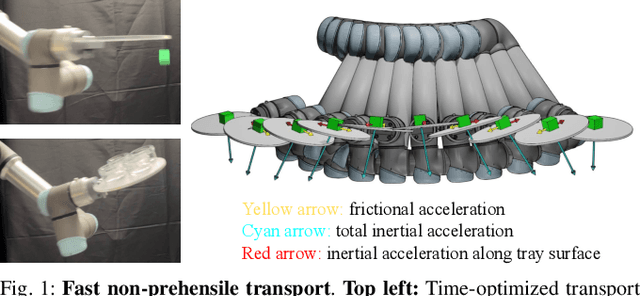
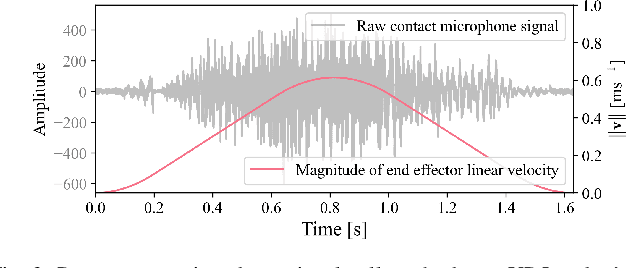
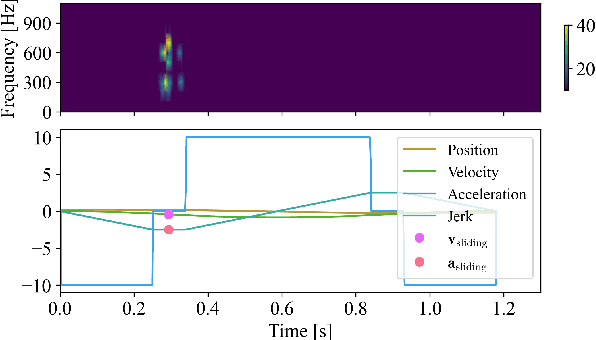

Object transport tasks are fundamental in robotic automation, emphasizing the importance of efficient and secure methods for moving objects. Non-prehensile transport can significantly improve transport efficiency, as it enables handling multiple objects simultaneously and accommodating objects unsuitable for parallel-jaw or suction grasps. Existing approaches incorporate constraints based on the Coulomb friction model, which is imprecise during fast motions where inherent mechanical vibrations occur. Imprecise constraints can cause transported objects to slide or even fall off the tray. To address this limitation, we propose a novel method to learn a friction model using acoustic sensing that maps a tray's motion profile to a dynamically conditioned friction coefficient. This learned model enables an optimization-based motion planner to adjust the friction constraint at each control step according to the planned motion at that step. In experiments, we generate time-optimized trajectories for a UR5e robot to transport various objects with constraints using both the standard Coulomb friction model and the learned friction model. Results suggest that the learned friction model reduces object displacement by up to 86.0% compared to the baseline, highlighting the effectiveness of acoustic sensing in learning real-world friction constraints.
RaySt3R: Predicting Novel Depth Maps for Zero-Shot Object Completion
Jun 05, 20253D shape completion has broad applications in robotics, digital twin reconstruction, and extended reality (XR). Although recent advances in 3D object and scene completion have achieved impressive results, existing methods lack 3D consistency, are computationally expensive, and struggle to capture sharp object boundaries. Our work (RaySt3R) addresses these limitations by recasting 3D shape completion as a novel view synthesis problem. Specifically, given a single RGB-D image and a novel viewpoint (encoded as a collection of query rays), we train a feedforward transformer to predict depth maps, object masks, and per-pixel confidence scores for those query rays. RaySt3R fuses these predictions across multiple query views to reconstruct complete 3D shapes. We evaluate RaySt3R on synthetic and real-world datasets, and observe it achieves state-of-the-art performance, outperforming the baselines on all datasets by up to 44% in 3D chamfer distance. Project page: https://rayst3r.github.io
Web2Grasp: Learning Functional Grasps from Web Images of Hand-Object Interactions
May 07, 2025Functional grasp is essential for enabling dexterous multi-finger robot hands to manipulate objects effectively. However, most prior work either focuses on power grasping, which simply involves holding an object still, or relies on costly teleoperated robot demonstrations to teach robots how to grasp each object functionally. Instead, we propose extracting human grasp information from web images since they depict natural and functional object interactions, thereby bypassing the need for curated demonstrations. We reconstruct human hand-object interaction (HOI) 3D meshes from RGB images, retarget the human hand to multi-finger robot hands, and align the noisy object mesh with its accurate 3D shape. We show that these relatively low-quality HOI data from inexpensive web sources can effectively train a functional grasping model. To further expand the grasp dataset for seen and unseen objects, we use the initially-trained grasping policy with web data in the IsaacGym simulator to generate physically feasible grasps while preserving functionality. We train the grasping model on 10 object categories and evaluate it on 9 unseen objects, including challenging items such as syringes, pens, spray bottles, and tongs, which are underrepresented in existing datasets. The model trained on the web HOI dataset, achieving a 75.8% success rate on seen objects and 61.8% across all objects in simulation, with a 6.7% improvement in success rate and a 1.8x increase in functionality ratings over baselines. Simulator-augmented data further boosts performance from 61.8% to 83.4%. The sim-to-real transfer to the LEAP Hand achieves a 85% success rate. Project website is at: https://webgrasp.github.io/.