 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGIFT: Generalizing Intent for Flexible Test-Time Rewards
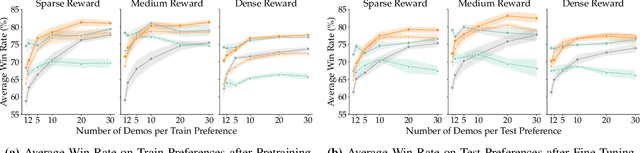
Mar 23, 2026Robots learn reward functions from user demonstrations, but these rewards often fail to generalize to new environments. This failure occurs because learned rewards latch onto spurious correlations in training data rather than the underlying human intent that demonstrations represent. Existing methods leverage visual or semantic similarity to improve robustness, yet these surface-level cues often diverge from what humans actually care about. We present Generalizing Intent for Flexible Test-Time Rewards (GIFT), a framework that grounds reward generalization in human intent rather than surface cues. GIFT leverages language models to infer high-level intent from user demonstrations by contrasting preferred with non-preferred behaviors. At deployment, GIFT maps novel test states to behaviorally equivalent training states via intent-conditioned similarity, enabling learned rewards to generalize across distribution shifts without retraining. We evaluate GIFT on tabletop manipulation tasks with new objects and layouts. Across four simulated tasks with over 50 unseen objects, GIFT consistently outperforms visual and semantic similarity baselines in test-time pairwise win rate and state-alignment F1 score. Real-world experiments on a 7-DoF Franka Panda robot demonstrate that GIFT reliably transfers to physical settings. Further discussion can be found at https://mit-clear-lab.github.io/GIFT/
Improving through Interaction: Searching Behavioral Representation Spaces with CMA-ES-IG
Mar 09, 2026Robots that interact with humans must adapt to individual users' preferences to operate effectively in human-centered environments. An intuitive and effective technique to learn non-expert users' preferences is through rankings of robot behaviors, e.g., trajectories, gestures, or voices. Existing techniques primarily focus on generating queries that optimize preference learning outcomes, such as sample efficiency or final preference estimation accuracy. However, the focus on outcome overlooks key user expectations in the process of providing these rankings, which can negatively impact users' adoption of robotic systems. This work proposes the Covariance Matrix Adaptation Evolution Strategies with Information Gain (CMA-ES-IG) algorithm. CMA-ES-IG explicitly incorporates user experience considerations into the preference learning process by suggesting perceptually distinct and informative trajectories for users to rank. We demonstrate these benefits through both simulated studies and real-robot experiments. CMA-ES-IG, compared to state-of-the-art alternatives, (1) scales more effectively to higher-dimensional preference spaces, (2) maintains computational tractability for high-dimensional problems, (3) is robust to noisy or inconsistent user feedback, and (4) is preferred by non-expert users in identifying their preferred robot behaviors. This project's code is available at github.com/interaction-lab/CMA-ES-IG
Masked IRL: LLM-Guided Reward Disambiguation from Demonstrations and Language
Nov 18, 2025


Robots can adapt to user preferences by learning reward functions from demonstrations, but with limited data, reward models often overfit to spurious correlations and fail to generalize. This happens because demonstrations show robots how to do a task but not what matters for that task, causing the model to focus on irrelevant state details. Natural language can more directly specify what the robot should focus on, and, in principle, disambiguate between many reward functions consistent with the demonstrations. However, existing language-conditioned reward learning methods typically treat instructions as simple conditioning signals, without fully exploiting their potential to resolve ambiguity. Moreover, real instructions are often ambiguous themselves, so naive conditioning is unreliable. Our key insight is that these two input types carry complementary information: demonstrations show how to act, while language specifies what is important. We propose Masked Inverse Reinforcement Learning (Masked IRL), a framework that uses large language models (LLMs) to combine the strengths of both input types. Masked IRL infers state-relevance masks from language instructions and enforces invariance to irrelevant state components. When instructions are ambiguous, it uses LLM reasoning to clarify them in the context of the demonstrations. In simulation and on a real robot, Masked IRL outperforms prior language-conditioned IRL methods by up to 15% while using up to 4.7 times less data, demonstrating improved sample-efficiency, generalization, and robustness to ambiguous language. Project page: https://MIT-CLEAR-Lab.github.io/Masked-IRL and Code: https://github.com/MIT-CLEAR-Lab/Masked-IRL
The Current State of AI Bias Bounties: An Overview of Existing Programmes and Research
Oct 02, 2025

Current bias evaluation methods rarely engage with communities impacted by AI systems. Inspired by bug bounties, bias bounties have been proposed as a reward-based method that involves communities in AI bias detection by asking users of AI systems to report biases they encounter when interacting with such systems. In the absence of a state-of-the-art review, this survey aimed to identify and analyse existing AI bias bounty programmes and to present academic literature on bias bounties. Google, Google Scholar, PhilPapers, and IEEE Xplore were searched, and five bias bounty programmes, as well as five research publications, were identified. All bias bounties were organised by U.S.-based organisations as time-limited contests, with public participation in four programmes and prize pools ranging from 7,000 to 24,000 USD. The five research publications included a report on the application of bug bounties to algorithmic harms, an article addressing Twitter's bias bounty, a proposal for bias bounties as an institutional mechanism to increase AI scrutiny, a workshop discussing bias bounties from queer perspectives, and an algorithmic framework for bias bounties. We argue that reducing the technical requirements to enter bounty programmes is important to include those without coding experience. Given the limited adoption of bias bounties, future efforts should explore the transferability of the best practices from bug bounties and examine how such programmes can be designed to be sensitive to underrepresented groups while lowering adoption barriers for organisations.
HRIBench: Benchmarking Vision-Language Models for Real-Time Human Perception in Human-Robot Interaction
Jun 25, 2025Real-time human perception is crucial for effective human-robot interaction (HRI). Large vision-language models (VLMs) offer promising generalizable perceptual capabilities but often suffer from high latency, which negatively impacts user experience and limits VLM applicability in real-world scenarios. To systematically study VLM capabilities in human perception for HRI and performance-latency trade-offs, we introduce HRIBench, a visual question-answering (VQA) benchmark designed to evaluate VLMs across a diverse set of human perceptual tasks critical for HRI. HRIBench covers five key domains: (1) non-verbal cue understanding, (2) verbal instruction understanding, (3) human-robot object relationship understanding, (4) social navigation, and (5) person identification. To construct HRIBench, we collected data from real-world HRI environments to curate questions for non-verbal cue understanding, and leveraged publicly available datasets for the remaining four domains. We curated 200 VQA questions for each domain, resulting in a total of 1000 questions for HRIBench. We then conducted a comprehensive evaluation of both state-of-the-art closed-source and open-source VLMs (N=11) on HRIBench. Our results show that, despite their generalizability, current VLMs still struggle with core perceptual capabilities essential for HRI. Moreover, none of the models within our experiments demonstrated a satisfactory performance-latency trade-off suitable for real-time deployment, underscoring the need for future research on developing smaller, low-latency VLMs with improved human perception capabilities. HRIBench and our results can be found in this Github repository: https://github.com/interaction-lab/HRIBench.
Modeling Personalized Difficulty of Rehabilitation Exercises Using Causal Trees
May 07, 2025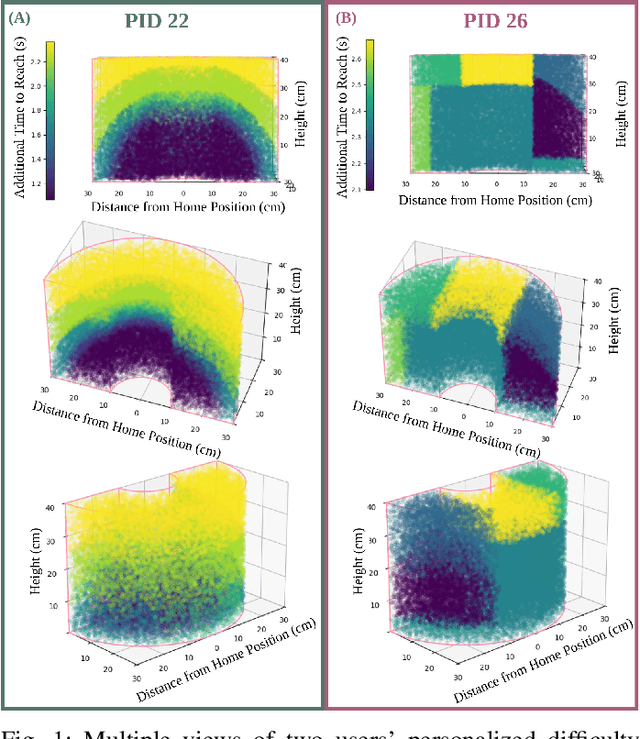

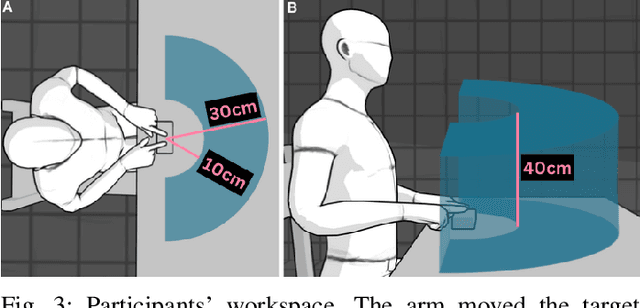
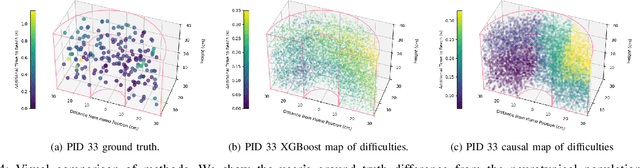
Rehabilitation robots are often used in game-like interactions for rehabilitation to increase a person's motivation to complete rehabilitation exercises. By adjusting exercise difficulty for a specific user throughout the exercise interaction, robots can maximize both the user's rehabilitation outcomes and the their motivation throughout the exercise. Previous approaches have assumed exercises have generic difficulty values that apply to all users equally, however, we identified that stroke survivors have varied and unique perceptions of exercise difficulty. For example, some stroke survivors found reaching vertically more difficult than reaching farther but lower while others found reaching farther more challenging than reaching vertically. In this paper, we formulate a causal tree-based method to calculate exercise difficulty based on the user's performance. We find that this approach accurately models exercise difficulty and provides a readily interpretable model of why that exercise is difficult for both users and caretakers.
Soft and Compliant Contact-Rich Hair Manipulation and Care
Jan 05, 2025



Hair care robots can help address labor shortages in elderly care while enabling those with limited mobility to maintain their hair-related identity. We present MOE-Hair, a soft robot system that performs three hair-care tasks: head patting, finger combing, and hair grasping. The system features a tendon-driven soft robot end-effector (MOE) with a wrist-mounted RGBD camera, leveraging both mechanical compliance for safety and visual force sensing through deformation. In testing with a force-sensorized mannequin head, MOE achieved comparable hair-grasping effectiveness while applying significantly less force than rigid grippers. Our novel force estimation method combines visual deformation data and tendon tensions from actuators to infer applied forces, reducing sensing errors by up to 60.1% and 20.3% compared to actuator current load-only and depth image-only baselines, respectively. A user study with 12 participants demonstrated statistically significant preferences for MOE-Hair over a baseline system in terms of comfort, effectiveness, and appropriate force application. These results demonstrate the unique advantages of soft robots in contact-rich hair-care tasks, while highlighting the importance of precise force control despite the inherent compliance of the system.
Contrastive Learning from Exploratory Actions: Leveraging Natural Interactions for Preference Elicitation
Jan 02, 2025



People have a variety of preferences for how robots behave. To understand and reason about these preferences, robots aim to learn a reward function that describes how aligned robot behaviors are with a user's preferences. Good representations of a robot's behavior can significantly reduce the time and effort required for a user to teach the robot their preferences. Specifying these representations -- what "features" of the robot's behavior matter to users -- remains a difficult problem; Features learned from raw data lack semantic meaning and features learned from user data require users to engage in tedious labeling processes. Our key insight is that users tasked with customizing a robot are intrinsically motivated to produce labels through exploratory search; they explore behaviors that they find interesting and ignore behaviors that are irrelevant. To harness this novel data source of exploratory actions, we propose contrastive learning from exploratory actions (CLEA) to learn trajectory features that are aligned with features that users care about. We learned CLEA features from exploratory actions users performed in an open-ended signal design activity (N=25) with a Kuri robot, and evaluated CLEA features through a second user study with a different set of users (N=42). CLEA features outperformed self-supervised features when eliciting user preferences over four metrics: completeness, simplicity, minimality, and explainability.
Improving User Experience in Preference-Based Optimization of Reward Functions for Assistive Robots
Nov 17, 2024



Assistive robots interact with humans and must adapt to different users' preferences to be effective. An easy and effective technique to learn non-expert users' preferences is through rankings of robot behaviors, for example, robot movement trajectories or gestures. Existing techniques focus on generating trajectories for users to rank that maximize the outcome of the preference learning process. However, the generated trajectories do not appear to reflect the user's preference over repeated interactions. In this work, we design an algorithm to generate trajectories for users to rank that we call Covariance Matrix Adaptation Evolution Strategies with Information Gain (CMA-ES-IG). CMA-ES-IG prioritizes the user's experience of the preference learning process. We show that users find our algorithm more intuitive and easier to use than previous approaches across both physical and social robot tasks. This project's code is hosted at github.com/interaction-lab/CMA-ES-IG
Inclusion in Assistive Haircare Robotics: Practical and Ethical Considerations in Hair Manipulation
Nov 07, 2024
Robot haircare systems could provide a controlled and personalized environment that is respectful of an individual's sensitivities and may offer a comfortable experience. We argue that because of hair and hairstyles' often unique importance in defining and expressing an individual's identity, we should approach the development of assistive robot haircare systems carefully while considering various practical and ethical concerns and risks. In this work, we specifically list and discuss the consideration of hair type, expression of the individual's preferred identity, cost accessibility of the system, culturally-aware robot strategies, and the associated societal risks. Finally, we discuss the planned studies that will allow us to better understand and address the concerns and considerations we outlined in this work through interactions with both haircare experts and end-users. Through these practical and ethical considerations, this work seeks to systematically organize and provide guidance for the development of inclusive and ethical robot haircare systems.