 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Week, In-Class Deployments of Telepresence Robots With Four Homebound K-12 Students: Benefits, Challenges, and Recommendations
May 19, 2026Missing significant amounts of school during K-12 education is known to put students' cognitive and social development at risk. Alternatives such as home instruction and online learning are common, but lack sufficient interaction with peers and teachers in the classroom. Mobile remote presence systems, or telepresence robots, are promising for homebound students because they provide embodiment and mobility in addition to the real-time participation offered by video conferencing technologies. Research is needed, however, for telepresence robots to meet the complex needs of homebound students participating remotely in the K-12 classroom context. We present findings from four multi-week deployments with homebound K-12 students attending classes via telepresence robots. The homebound students' experiences were documented in a total of 15 interviews and analyzed qualitatively as case studies. The homebound student participants and their deployment contexts differed from one another along multiple dimensions, and while some benefits of mobile remote attendance were enjoyed by all participants, each participant also experienced unique benefits. Some challenges with hearing, seeing, and moving the robot around the classroom warranted improvements to the design of the telepresence system. Other challenges suggested priorities for managing a classroom deployment, such as ensuring that the remote student is included in classroom activities, accountable to the teacher, and treated with respect by classmates. Based on insights from the study, we make recommendations for real-world deployment procedures in similar contexts.
A metric for characterizing the arm nonuse workspace in poststroke individuals using a robot arm
Jan 13, 2024An over-reliance on the less-affected limb for functional tasks at the expense of the paretic limb and in spite of recovered capacity is an often-observed phenomenon in survivors of hemispheric stroke. The difference between capacity for use and actual spontaneous use is referred to as arm nonuse. Obtaining an ecologically valid evaluation of arm nonuse is challenging because it requires the observation of spontaneous arm choice for different tasks, which can easily be influenced by instructions, presumed expectations, and awareness that one is being tested. To better quantify arm nonuse, we developed the Bimanual Arm Reaching Test with a Robot (BARTR) for quantitatively assessing arm nonuse in chronic stroke survivors. The BARTR is an instrument that utilizes a robot arm as a means of remote and unbiased data collection of nuanced spatial data for clinical evaluations of arm nonuse. This approach shows promise for determining the efficacy of interventions designed to reduce paretic arm nonuse and enhance functional recovery after stroke. We show that the BARTR satisfies the criteria of an appropriate metric for neurorehabilitative contexts: it is valid, reliable, and simple to use.
* Accepted to Science Robotics at https://www.science.org/doi/10.1126/scirobotics.adf7723 on November 15th, 2023
Quality-Diversity Generative Sampling for Learning with Synthetic Data
Dec 22, 2023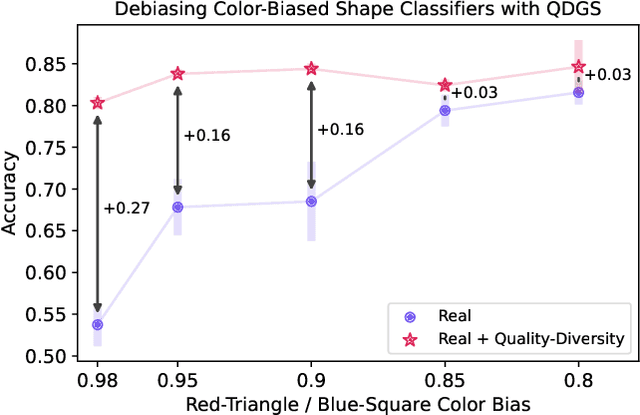
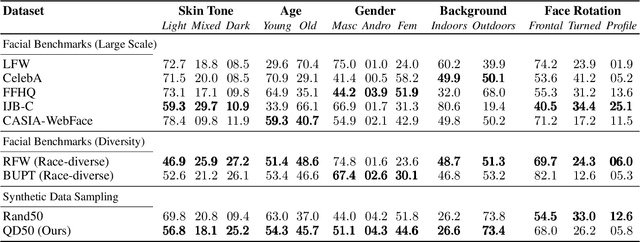


Generative models can serve as surrogates for some real data sources by creating synthetic training datasets, but in doing so they may transfer biases to downstream tasks. We focus on protecting quality and diversity when generating synthetic training datasets. We propose quality-diversity generative sampling (QDGS), a framework for sampling data uniformly across a user-defined measure space, despite the data coming from a biased generator. QDGS is a model-agnostic framework that uses prompt guidance to optimize a quality objective across measures of diversity for synthetically generated data, without fine-tuning the generative model. Using balanced synthetic datasets generated by QDGS, we first debias classifiers trained on color-biased shape datasets as a proof-of-concept. By applying QDGS to facial data synthesis, we prompt for desired semantic concepts, such as skin tone and age, to create an intersectional dataset with a combined blend of visual features. Leveraging this balanced data for training classifiers improves fairness while maintaining accuracy on facial recognition benchmarks. Code available at: https://github.com/Cylumn/qd-generative-sampling
Evaluating Temporal Patterns in Applied Infant Affect Recognition
Sep 07, 2022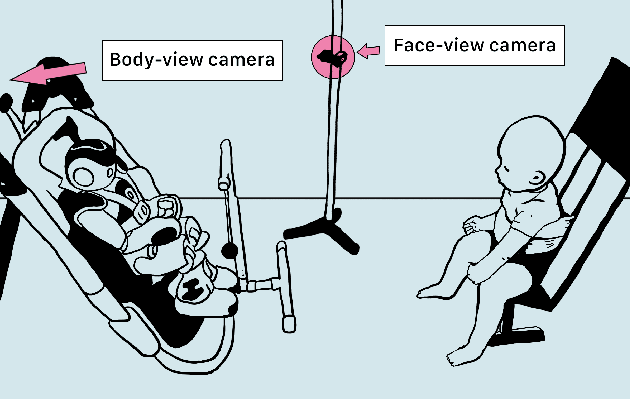
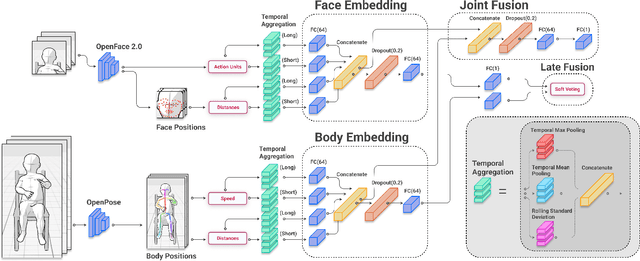

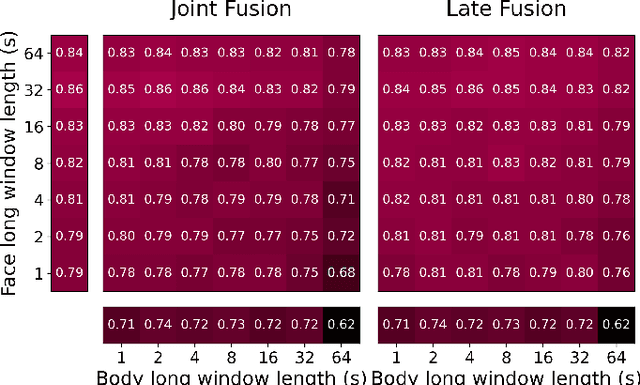
Agents must monitor their partners' affective states continuously in order to understand and engage in social interactions. However, methods for evaluating affect recognition do not account for changes in classification performance that may occur during occlusions or transitions between affective states. This paper addresses temporal patterns in affect classification performance in the context of an infant-robot interaction, where infants' affective states contribute to their ability to participate in a therapeutic leg movement activity. To support robustness to facial occlusions in video recordings, we trained infant affect recognition classifiers using both facial and body features. Next, we conducted an in-depth analysis of our best-performing models to evaluate how performance changed over time as the models encountered missing data and changing infant affect. During time windows when features were extracted with high confidence, a unimodal model trained on facial features achieved the same optimal performance as multimodal models trained on both facial and body features. However, multimodal models outperformed unimodal models when evaluated on the entire dataset. Additionally, model performance was weakest when predicting an affective state transition and improved after multiple predictions of the same affective state. These findings emphasize the benefits of incorporating body features in continuous affect recognition for infants. Our work highlights the importance of evaluating variability in model performance both over time and in the presence of missing data when applying affect recognition to social interactions.
What and How Are We Reporting in HRI? A Review and Recommendations for Reporting Recruitment, Compensation, and Gender
Jan 22, 2022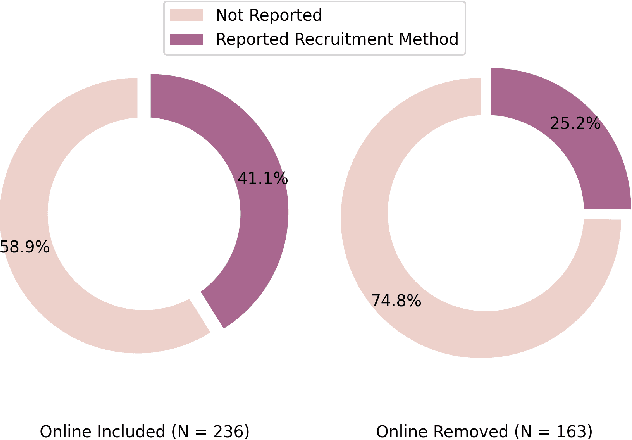
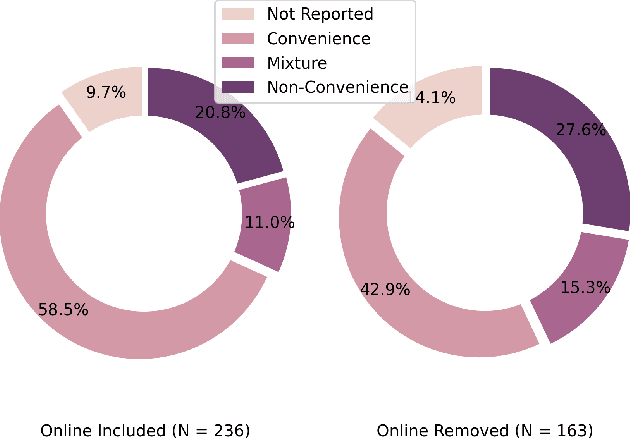
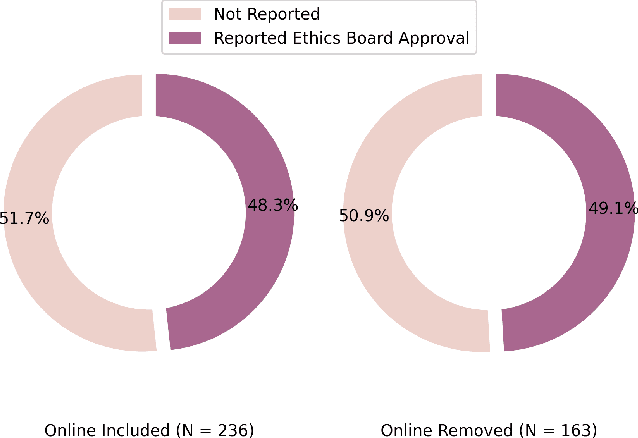
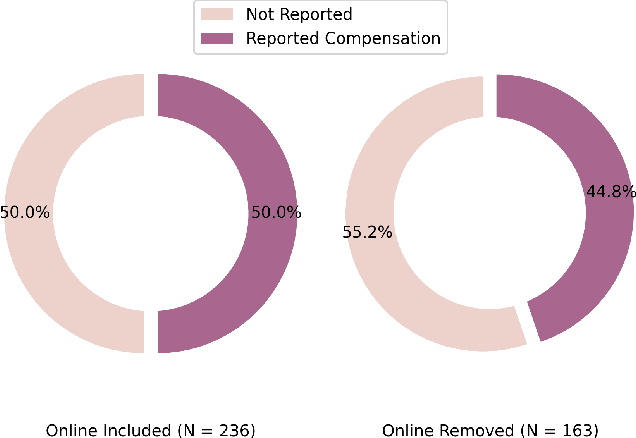
Study reproducibility and generalizability of results to broadly inclusive populations is crucial in any research. Previous meta-analyses in HRI have focused on the consistency of reported information from papers in various categories. However, members of the HRI community have noted that much of the information needed for reproducible and generalizable studies is not found in published papers. We address this issue by surveying the reported study metadata over the past three years (2019 through 2021) of the main proceedings of the International Conference on Human-Robot Interaction (HRI) as well as alt.HRI. Based on the analysis results, we propose a set of recommendations for the HRI community that follow the longer-standing reporting guidelines from human-computer interaction (HCI), psychology, and other fields most related to HRI. Finally, we examine three key areas for user study reproducibility: recruitment details, participant compensation, and participant gender. We find a lack of reporting within each of these study metadata categories: of the 236 studies, 139 studies failed to report recruitment method, 118 studies failed to report compensation, and 62 studies failed to report gender data. This analysis therefore provides guidance about specific types of needed reporting improvements for HRI.
Long-Term, in-the-Wild Study of Feedback about Speech Intelligibility for K-12 Students Attending Class via a Telepresence Robot
Aug 24, 2021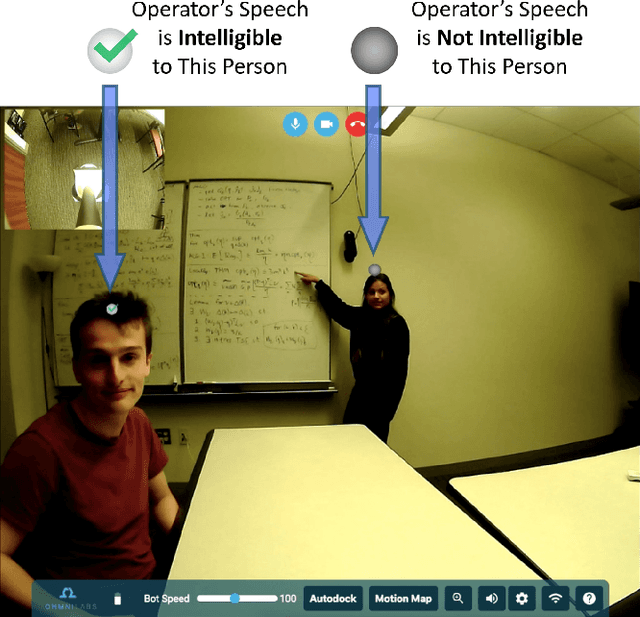

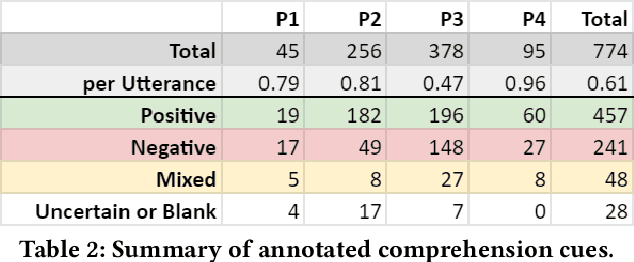
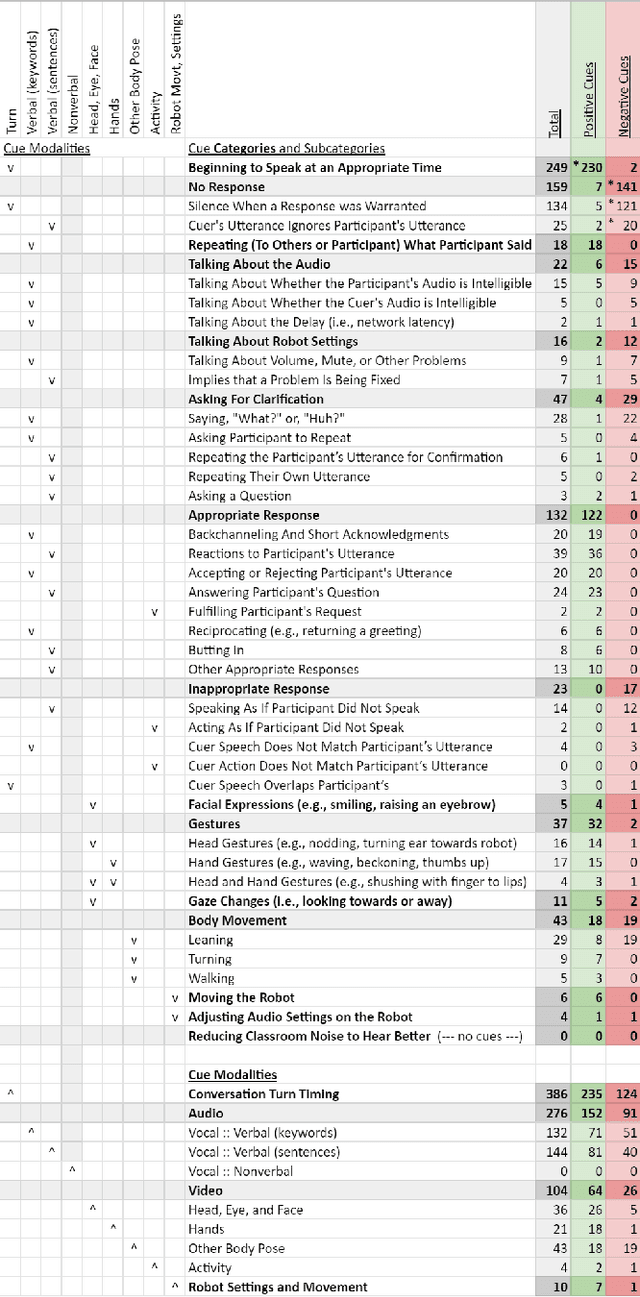
Telepresence robots offer presence, embodiment, and mobility to remote users, making them promising options for homebound K-12 students. It is difficult, however, for robot operators to know how well they are being heard in remote and noisy classroom environments. One solution is to estimate the operator's speech intelligibility to their listeners in order to provide feedback about it to the operator. This work contributes the first evaluation of a speech intelligibility feedback system for homebound K-12 students attending class remotely. In our four long-term, in-the-wild deployments we found that students speak at different volumes instead of adjusting the robot's volume, and that detailed audio calibration and network latency feedback are needed. We also contribute the first findings about the types and frequencies of multimodal comprehension cues given to homebound students by listeners in the classroom. By annotating and categorizing over 700 cues, we found that the most common cue modalities were conversation turn timing and verbal content. Conversation turn timing cues occurred more frequently overall, whereas verbal content cues contained more information and might be the most frequent modality for negative cues. Our work provides recommendations for telepresence systems that could intervene to ensure that remote users are being heard.
Modeling Engagement in Long-Term, In-Home Socially Assistive Robot Interventions for Children with Autism Spectrum Disorders
Feb 06, 2020

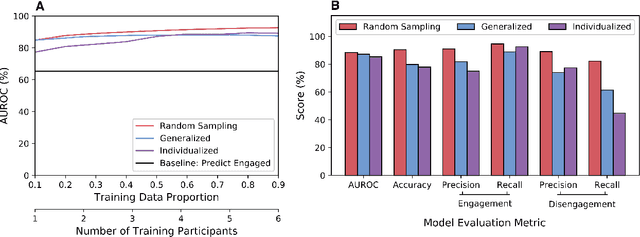
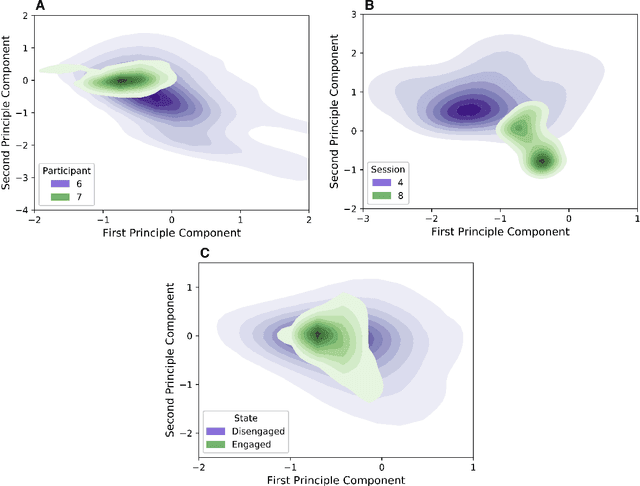
Socially assistive robotics (SAR) has great potential to provide accessible, affordable, and personalized therapeutic interventions for children with autism spectrum disorders (ASD). However, human-robot interaction (HRI) methods are still limited in their ability to autonomously recognize and respond to behavioral cues, especially in atypical users and everyday settings. This work applies supervised machine learning algorithms to model user engagement in the context of long-term, in-home SAR interventions for children with ASD. Specifically, two types of engagement models are presented for each user: 1) generalized models trained on data from different users; and 2) individualized models trained on an early subset of the user's data. The models achieved approximately 90% accuracy (AUROC) for post hoc binary classification of engagement, despite the high variance in data observed across users, sessions, and engagement states. Moreover, temporal patterns in model predictions could be used to reliably initiate re-engagement actions at appropriate times. These results validate the feasibility and challenges of recognition and response to user disengagement in long-term, real-world HRI settings. The contributions of this work also inform the design of engaging and personalized HRI, especially for the ASD community.
Using Socially Expressive Mixed Reality Arms for Enhancing Low-Expressivity Robots
Nov 30, 2019


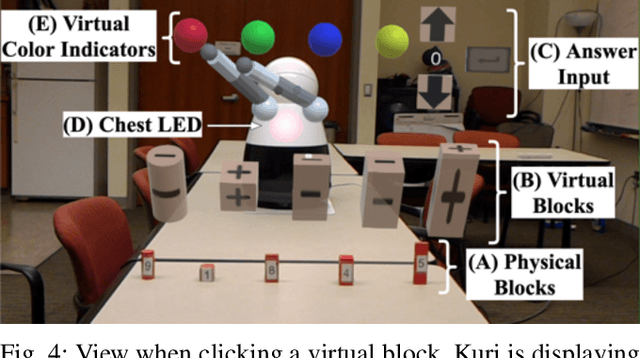
Expressivity--the use of multiple modalities to convey internal state and intent of a robot--is critical for interaction. Yet, due to cost, safety, and other constraints, many robots lack high degrees of physical expressivity. This paper explores using mixed reality to enhance a robot with limited expressivity by adding virtual arms that extend the robot's expressiveness. The arms, capable of a range of non-physically-constrained gestures, were evaluated in a between-subject study ($n=34$) where participants engaged in a mixed reality mathematics task with a socially assistive robot. The study results indicate that the virtual arms added a higher degree of perceived emotion, helpfulness, and physical presence to the robot. Users who reported a higher perceived physical presence also found the robot to have a higher degree of social presence, ease of use, usefulness, and had a positive attitude toward using the robot with mixed reality. The results also demonstrate the users' ability to distinguish the virtual gestures' valence and intent.