 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Improving Reward Design in RL: A Reward Alignment Metric for RL Practitioners
Mar 08, 2025



Reinforcement learning agents are fundamentally limited by the quality of the reward functions they learn from, yet reward design is often overlooked under the assumption that a well-defined reward is readily available. However, in practice, designing rewards is difficult, and even when specified, evaluating their correctness is equally problematic: how do we know if a reward function is correctly specified? In our work, we address these challenges by focusing on reward alignment -- assessing whether a reward function accurately encodes the preferences of a human stakeholder. As a concrete measure of reward alignment, we introduce the Trajectory Alignment Coefficient to quantify the similarity between a human stakeholder's ranking of trajectory distributions and those induced by a given reward function. We show that the Trajectory Alignment Coefficient exhibits desirable properties, such as not requiring access to a ground truth reward, invariance to potential-based reward shaping, and applicability to online RL. Additionally, in an 11 -- person user study of RL practitioners, we found that access to the Trajectory Alignment Coefficient during reward selection led to statistically significant improvements. Compared to relying only on reward functions, our metric reduced cognitive workload by 1.5x, was preferred by 82% of users and increased the success rate of selecting reward functions that produced performant policies by 41%.
Influencing Humans to Conform to Preference Models for RLHF
Jan 11, 2025



Designing a reinforcement learning from human feedback (RLHF) algorithm to approximate a human's unobservable reward function requires assuming, implicitly or explicitly, a model of human preferences. A preference model that poorly describes how humans generate preferences risks learning a poor approximation of the human's reward function. In this paper, we conduct three human studies to asses whether one can influence the expression of real human preferences to more closely conform to a desired preference model. Importantly, our approach does not seek to alter the human's unobserved reward function. Rather, we change how humans use this reward function to generate preferences, such that they better match whatever preference model is assumed by a particular RLHF algorithm. We introduce three interventions: showing humans the quantities that underlie a preference model, which is normally unobservable information derived from the reward function; training people to follow a specific preference model; and modifying the preference elicitation question. All intervention types show significant effects, providing practical tools to improve preference data quality and the resultant alignment of the learned reward functions. Overall we establish a novel research direction in model alignment: designing interfaces and training interventions to increase human conformance with the modeling assumptions of the algorithm that will learn from their input.
Quality-Diversity Generative Sampling for Learning with Synthetic Data
Dec 22, 2023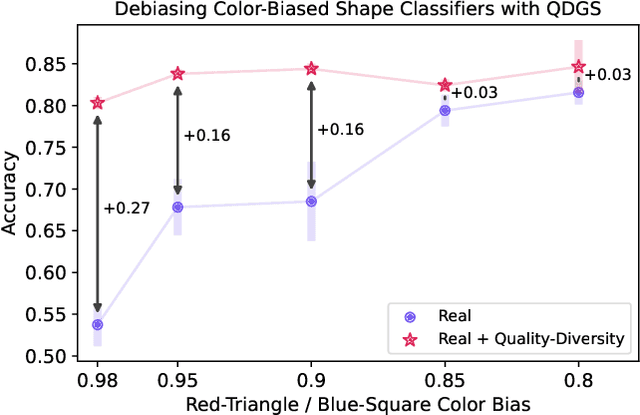
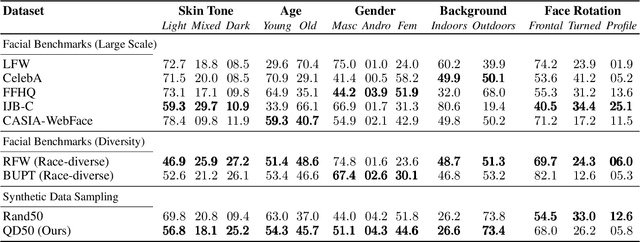


Generative models can serve as surrogates for some real data sources by creating synthetic training datasets, but in doing so they may transfer biases to downstream tasks. We focus on protecting quality and diversity when generating synthetic training datasets. We propose quality-diversity generative sampling (QDGS), a framework for sampling data uniformly across a user-defined measure space, despite the data coming from a biased generator. QDGS is a model-agnostic framework that uses prompt guidance to optimize a quality objective across measures of diversity for synthetically generated data, without fine-tuning the generative model. Using balanced synthetic datasets generated by QDGS, we first debias classifiers trained on color-biased shape datasets as a proof-of-concept. By applying QDGS to facial data synthesis, we prompt for desired semantic concepts, such as skin tone and age, to create an intersectional dataset with a combined blend of visual features. Leveraging this balanced data for training classifiers improves fairness while maintaining accuracy on facial recognition benchmarks. Code available at: https://github.com/Cylumn/qd-generative-sampling
Learning Optimal Advantage from Preferences and Mistaking it for Reward
Oct 03, 2023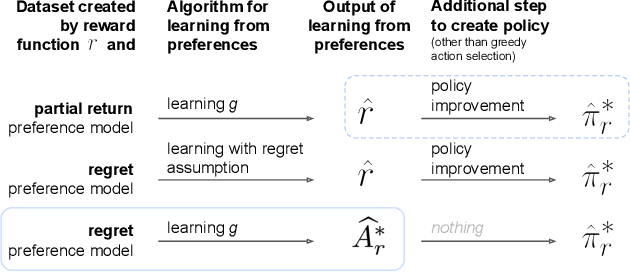

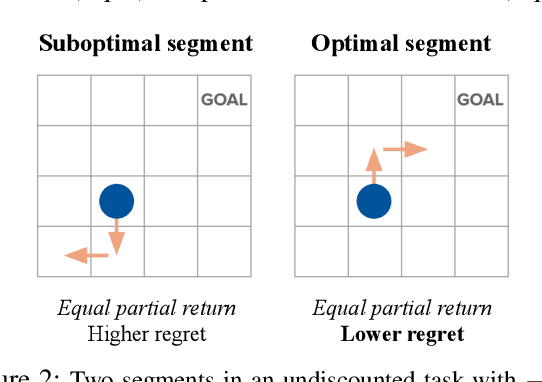
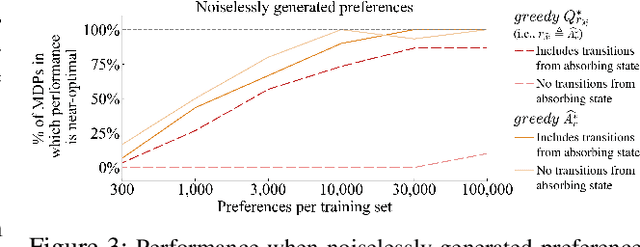
We consider algorithms for learning reward functions from human preferences over pairs of trajectory segments, as used in reinforcement learning from human feedback (RLHF). Most recent work assumes that human preferences are generated based only upon the reward accrued within those segments, or their partial return. Recent work casts doubt on the validity of this assumption, proposing an alternative preference model based upon regret. We investigate the consequences of assuming preferences are based upon partial return when they actually arise from regret. We argue that the learned function is an approximation of the optimal advantage function, $\hat{A^*_r}$, not a reward function. We find that if a specific pitfall is addressed, this incorrect assumption is not particularly harmful, resulting in a highly shaped reward function. Nonetheless, this incorrect usage of $\hat{A^*_r}$ is less desirable than the appropriate and simpler approach of greedy maximization of $\hat{A^*_r}$. From the perspective of the regret preference model, we also provide a clearer interpretation of fine tuning contemporary large language models with RLHF. This paper overall provides insight regarding why learning under the partial return preference model tends to work so well in practice, despite it conforming poorly to how humans give preferences.
Models of human preference for learning reward functions
Jun 05, 2022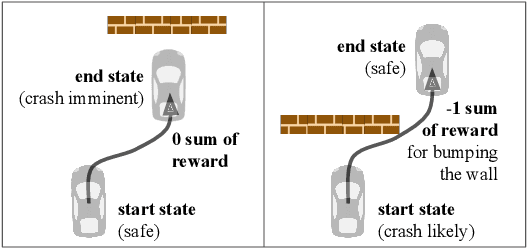
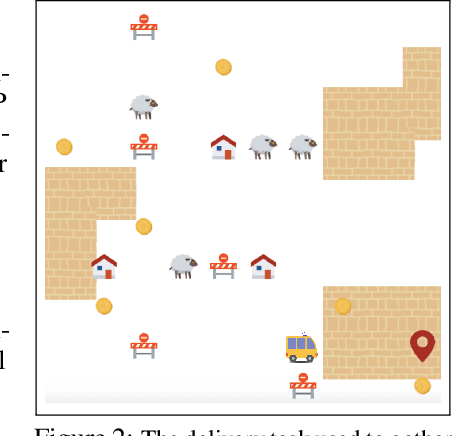
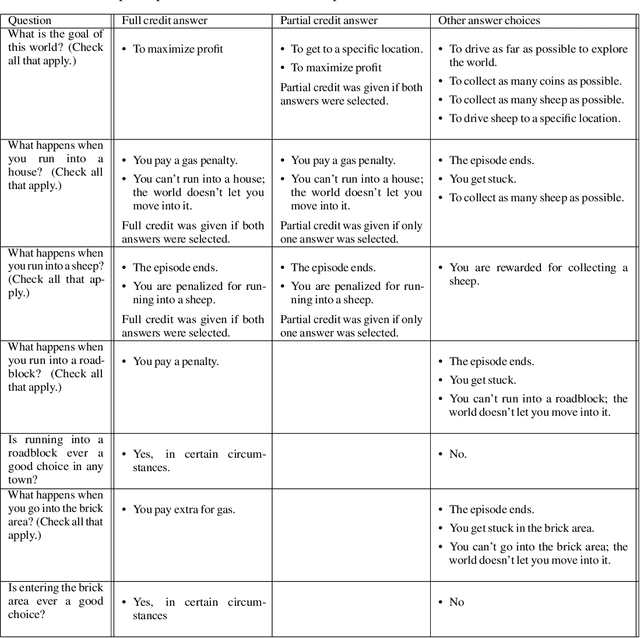
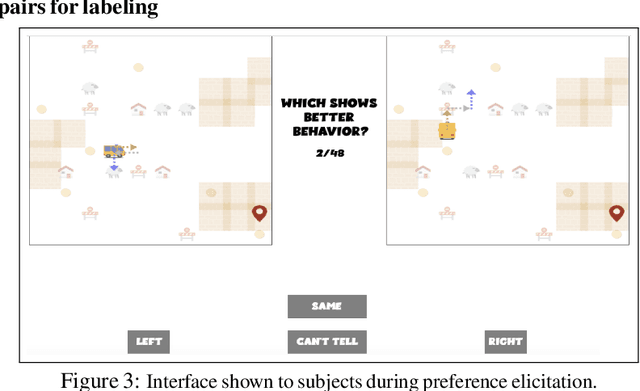
The utility of reinforcement learning is limited by the alignment of reward functions with the interests of human stakeholders. One promising method for alignment is to learn the reward function from human-generated preferences between pairs of trajectory segments. These human preferences are typically assumed to be informed solely by partial return, the sum of rewards along each segment. We find this assumption to be flawed and propose modeling preferences instead as arising from a different statistic: each segment's regret, a measure of a segment's deviation from optimal decision-making. Given infinitely many preferences generated according to regret, we prove that we can identify a reward function equivalent to the reward function that generated those preferences. We also prove that the previous partial return model lacks this identifiability property without preference noise that reveals rewards' relative proportions, and we empirically show that our proposed regret preference model outperforms it with finite training data in otherwise the same setting. Additionally, our proposed regret preference model better predicts real human preferences and also learns reward functions from these preferences that lead to policies that are better human-aligned. Overall, this work establishes that the choice of preference model is impactful, and our proposed regret preference model provides an improvement upon a core assumption of recent research.
The Irrationality of Neural Rationale Models
Oct 14, 2021



Neural rationale models are popular for interpretable predictions of NLP tasks. In these, a selector extracts segments of the input text, called rationales, and passes these segments to a classifier for prediction. Since the rationale is the only information accessible to the classifier, it is plausibly defined as the explanation. Is such a characterization unconditionally correct? In this paper, we argue to the contrary, with both philosophical perspectives and empirical evidence suggesting that rationale models are, perhaps, less rational and interpretable than expected. We call for more rigorous and comprehensive evaluations of these models to ensure desired properties of interpretability are indeed achieved. The code can be found at https://github.com/yimingz89/Neural-Rationale-Analysis.
Machine Learning Practices Outside Big Tech: How Resource Constraints Challenge Responsible Development
Oct 06, 2021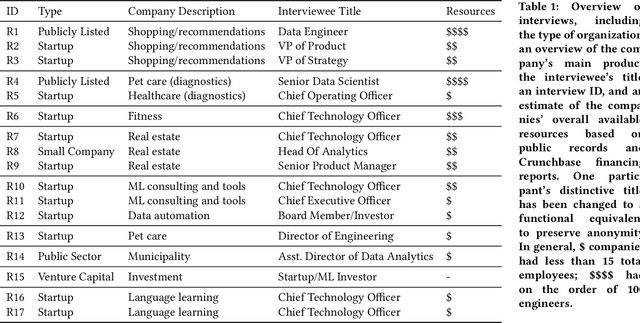
Practitioners from diverse occupations and backgrounds are increasingly using machine learning (ML) methods. Nonetheless, studies on ML Practitioners typically draw populations from Big Tech and academia, as researchers have easier access to these communities. Through this selection bias, past research often excludes the broader, lesser-resourced ML community -- for example, practitioners working at startups, at non-tech companies, and in the public sector. These practitioners share many of the same ML development difficulties and ethical conundrums as their Big Tech counterparts; however, their experiences are subject to additional under-studied challenges stemming from deploying ML with limited resources, increased existential risk, and absent access to in-house research teams. We contribute a qualitative analysis of 17 interviews with stakeholders from organizations which are less represented in prior studies. We uncover a number of tensions which are introduced or exacerbated by these organizations' resource constraints -- tensions between privacy and ubiquity, resource management and performance optimization, and access and monopolization. Increased academic focus on these practitioners can facilitate a more holistic understanding of ML limitations, and so is useful for prescribing a research agenda to facilitate responsible ML development for all.
Do Feature Attribution Methods Correctly Attribute Features?
Apr 27, 2021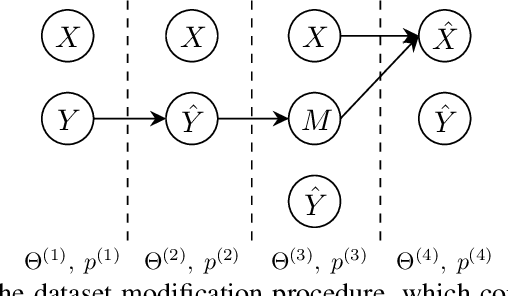

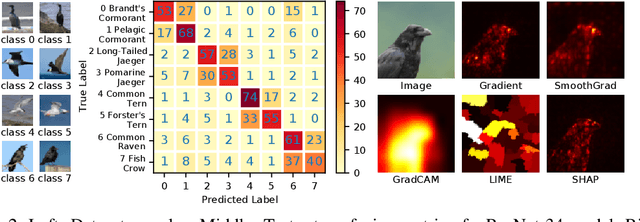
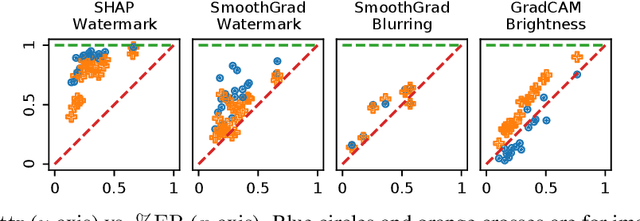
Feature attribution methods are exceedingly popular in interpretable machine learning. They aim to compute the attribution of each input feature to represent its importance, but there is no consensus on the definition of "attribution", leading to many competing methods with little systematic evaluation. The lack of attribution ground truth further complicates evaluation, which has to rely on proxy metrics. To address this, we propose a dataset modification procedure such that models trained on the new dataset have ground truth attribution available. We evaluate three methods: saliency maps, rationales, and attention. We identify their deficiencies and add a new perspective to the growing body of evidence questioning their correctness and reliability in the wild. Our evaluation approach is model-agnostic and can be used to assess future feature attribution method proposals as well. Code is available at https://github.com/YilunZhou/feature-attribution-evaluation.
RoCUS: Robot Controller Understanding via Sampling
Dec 25, 2020
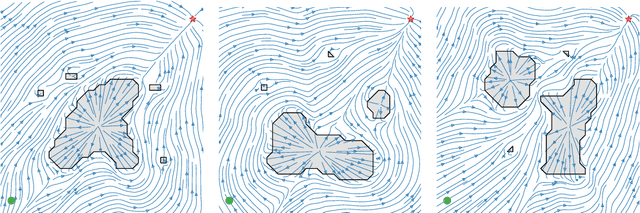
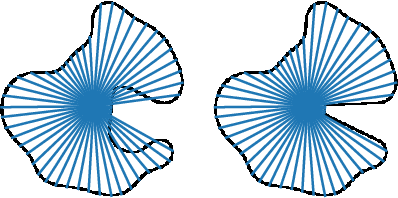
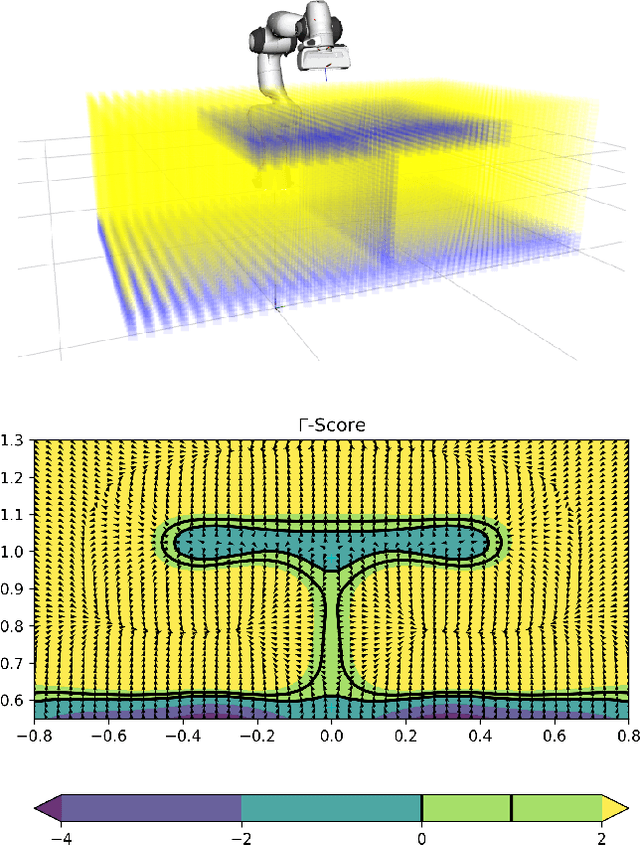
As robots are deployed in complex situations, engineers and end users must develop a holistic understanding of their capabilities and behaviors. Existing research focuses mainly on factors related to task completion, such as success rate, completion time, or total energy consumption. Other factors like collision avoidance behavior, trajectory smoothness, and motion legibility are equally or more important for safe and trustworthy deployment. While methods exist to analyze these quality factors for individual trajectories or distributions of trajectories, these statistics may be insufficient to develop a mental model of the controller's behaviors, especially uncommon behaviors. We present RoCUS: a Bayesian sampling-based method to find situations that lead to trajectories which exhibit certain behaviors. By analyzing these situations and trajectories, we can gain important insights into the controller that are easily missed in standard task-completion evaluations. On a 2D navigation problem and a 7 degree-of-freedom (DoF) arm reaching problem, we analyze three controllers: a rapidly exploring random tree (RRT) planner, a dynamical system (DS) formulation, and a deep imitation learning (IL) or reinforcement learning (RL) model. We show how RoCUS can uncover insights to further our understanding about them beyond task-completion aspects. The code is available at https://github.com/YilunZhou/RoCUS.
Bayes-Probe: Distribution-Guided Sampling for Prediction Level Sets
Feb 19, 2020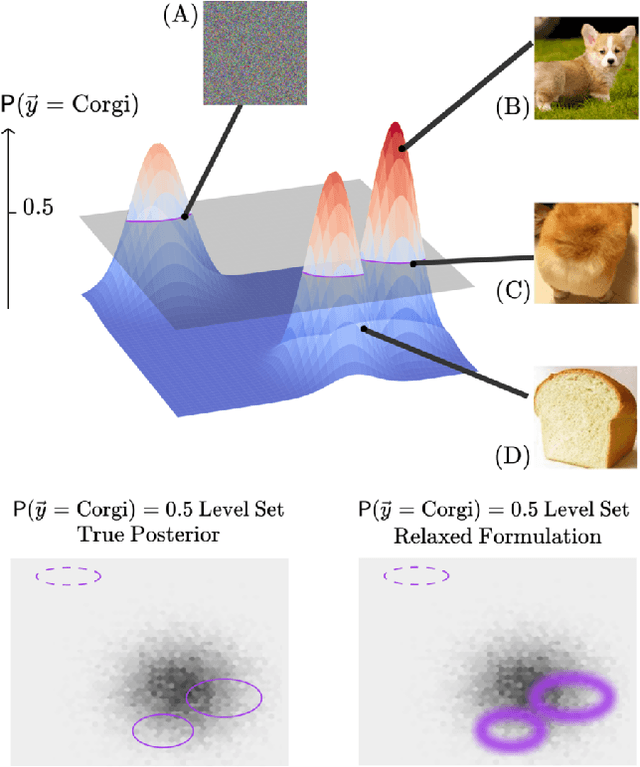


Building machine learning models requires a suite of tools for interpretation, understanding, and debugging. Many existing methods have been proposed, but it can still be difficult to probe for examples which communicate model behaviour. We introduce Bayes-Probe, a model inspection method for analyzing neural networks by generating distribution-conforming examples of known prediction confidence. By selecting appropriate distributions and confidence prediction values, Bayes-Probe can be used to synthesize ambivalent predictions, uncover in-distribution adversarial examples, and understand novel-class extrapolation and domain adaptation behaviours. Bayes-Probe is model agnostic, requiring only a data generator and classifier prediction. We use Bayes-Probe to analyze models trained on both procedurally-generated data (CLEVR) and organic data (MNIST and Fashion-MNIST). Code is available at https://github.com/serenabooth/Bayes-Probe.