 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent-Predictive Empowerment: Measuring Empowerment without a Simulator
Oct 15, 2024Empowerment has the potential to help agents learn large skillsets, but is not yet a scalable solution for training general-purpose agents. Recent empowerment methods learn diverse skillsets by maximizing the mutual information between skills and states; however, these approaches require a model of the transition dynamics, which can be challenging to learn in realistic settings with high-dimensional and stochastic observations. We present Latent-Predictive Empowerment (LPE), an algorithm that can compute empowerment in a more practical manner. LPE learns large skillsets by maximizing an objective that is a principled replacement for the mutual information between skills and states and that only requires a simpler latent-predictive model rather than a full simulator of the environment. We show empirically in a variety of settings--including ones with high-dimensional observations and highly stochastic transition dynamics--that our empowerment objective (i) learns similar-sized skillsets as the leading empowerment algorithm that assumes access to a model of the transition dynamics and (ii) outperforms other model-based approaches to empowerment.
Hierarchical Empowerment: Towards Tractable Empowerment-Based Skill-Learning
Jul 06, 2023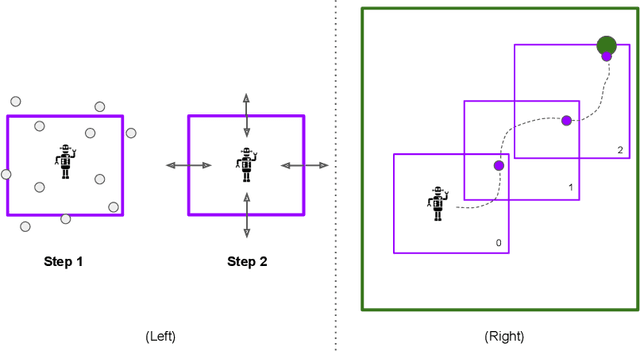

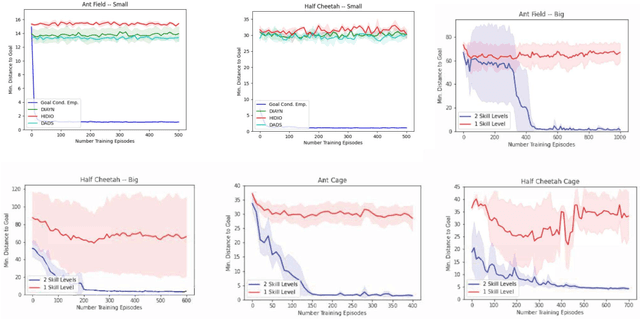

General purpose agents will require large repertoires of skills. Empowerment -- the maximum mutual information between skills and the states -- provides a pathway for learning large collections of distinct skills, but mutual information is difficult to optimize. We introduce a new framework, Hierarchical Empowerment, that makes computing empowerment more tractable by integrating concepts from Goal-Conditioned Hierarchical Reinforcement Learning. Our framework makes two specific contributions. First, we introduce a new variational lower bound on mutual information that can be used to compute empowerment over short horizons. Second, we introduce a hierarchical architecture for computing empowerment over exponentially longer time scales. We verify the contributions of the framework in a series of simulated robotics tasks. In a popular ant navigation domain, our four level agents are able to learn skills that cover a surface area over two orders of magnitude larger than prior work.
Models of human preference for learning reward functions
Jun 05, 2022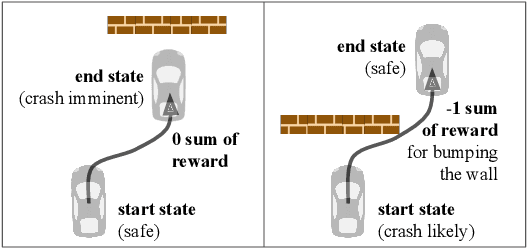
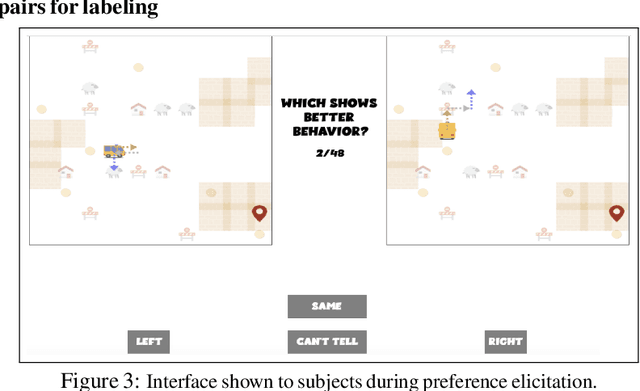
The utility of reinforcement learning is limited by the alignment of reward functions with the interests of human stakeholders. One promising method for alignment is to learn the reward function from human-generated preferences between pairs of trajectory segments. These human preferences are typically assumed to be informed solely by partial return, the sum of rewards along each segment. We find this assumption to be flawed and propose modeling preferences instead as arising from a different statistic: each segment's regret, a measure of a segment's deviation from optimal decision-making. Given infinitely many preferences generated according to regret, we prove that we can identify a reward function equivalent to the reward function that generated those preferences. We also prove that the previous partial return model lacks this identifiability property without preference noise that reveals rewards' relative proportions, and we empirically show that our proposed regret preference model outperforms it with finite training data in otherwise the same setting. Additionally, our proposed regret preference model better predicts real human preferences and also learns reward functions from these preferences that lead to policies that are better human-aligned. Overall, this work establishes that the choice of preference model is impactful, and our proposed regret preference model provides an improvement upon a core assumption of recent research.
Reward (Mis)design for Autonomous Driving
Apr 28, 2021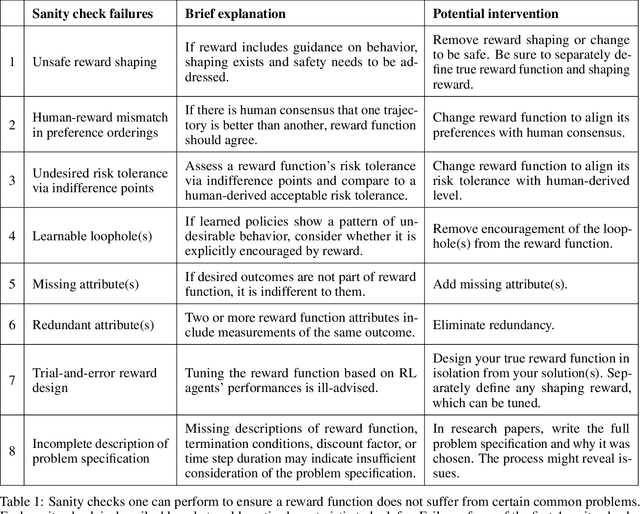
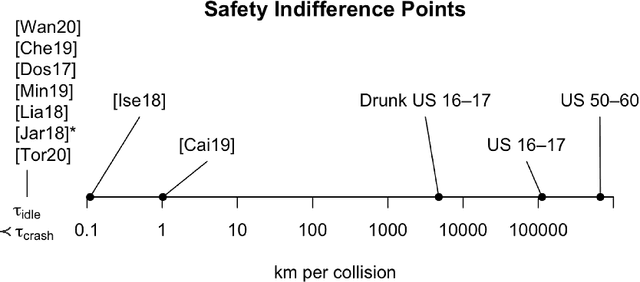
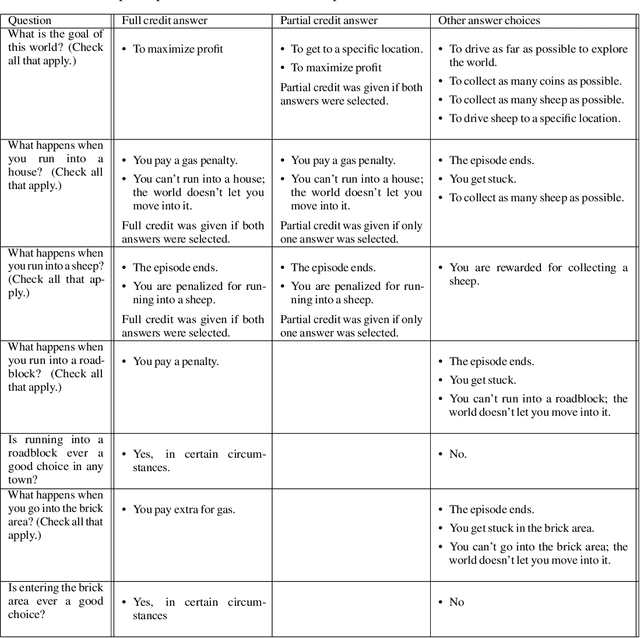
This paper considers the problem of reward design for autonomous driving (AD), with insights that are also applicable to the design of cost functions and performance metrics more generally. Herein we develop 8 simple sanity checks for identifying flaws in reward functions. The sanity checks are applied to reward functions from past work on reinforcement learning (RL) for autonomous driving, revealing near-universal flaws in reward design for AD that might also exist pervasively across reward design for other tasks. Lastly, we explore promising directions that may help future researchers design reward functions for AD.
The EMPATHIC Framework for Task Learning from Implicit Human Feedback
Sep 28, 2020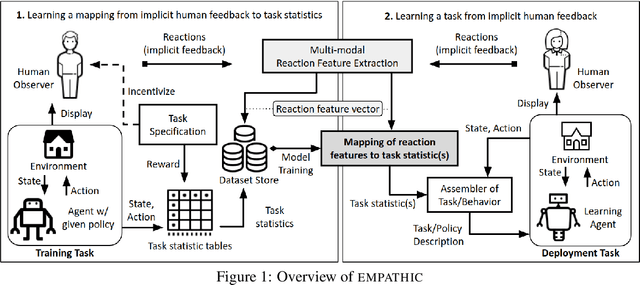



Reactions such as gestures, facial expressions, and vocalizations are an abundant, naturally occurring channel of information that humans provide during interactions. A robot or other agent could leverage an understanding of such implicit human feedback to improve its task performance at no cost to the human. This approach contrasts with common agent teaching methods based on demonstrations, critiques, or other guidance that need to be attentively and intentionally provided. In this paper, we first define the general problem of learning from implicit human feedback and then propose to address this problem through a novel data-driven framework, EMPATHIC. This two-stage method consists of (1) mapping implicit human feedback to relevant task statistics such as rewards, optimality, and advantage; and (2) using such a mapping to learn a task. We instantiate the first stage and three second-stage evaluations of the learned mapping. To do so, we collect a dataset of human facial reactions while participants observe an agent execute a sub-optimal policy for a prescribed training task. We train a deep neural network on this data and demonstrate its ability to (1) infer relative reward ranking of events in the training task from prerecorded human facial reactions; (2) improve the policy of an agent in the training task using live human facial reactions; and (3) transfer to a novel domain in which it evaluates robot manipulation trajectories.