 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepFleet: Multi-Agent Foundation Models for Mobile Robots
Aug 12, 2025
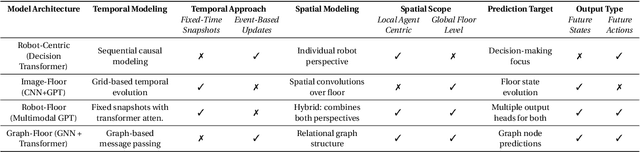
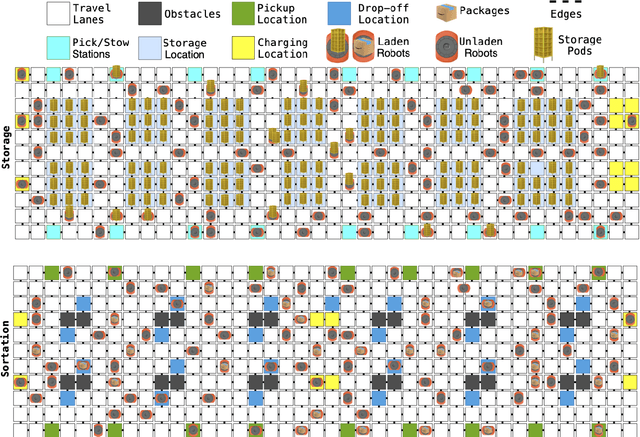
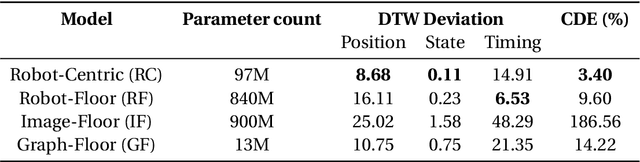
We introduce DeepFleet, a suite of foundation models designed to support coordination and planning for large-scale mobile robot fleets. These models are trained on fleet movement data, including robot positions, goals, and interactions, from hundreds of thousands of robots in Amazon warehouses worldwide. DeepFleet consists of four architectures that each embody a distinct inductive bias and collectively explore key points in the design space for multi-agent foundation models: the robot-centric (RC) model is an autoregressive decision transformer operating on neighborhoods of individual robots; the robot-floor (RF) model uses a transformer with cross-attention between robots and the warehouse floor; the image-floor (IF) model applies convolutional encoding to a multi-channel image representation of the full fleet; and the graph-floor (GF) model combines temporal attention with graph neural networks for spatial relationships. In this paper, we describe these models and present our evaluation of the impact of these design choices on prediction task performance. We find that the robot-centric and graph-floor models, which both use asynchronous robot state updates and incorporate the localized structure of robot interactions, show the most promise. We also present experiments that show that these two models can make effective use of larger warehouses operation datasets as the models are scaled up.
Null Counterfactual Factor Interactions for Goal-Conditioned Reinforcement Learning
May 06, 2025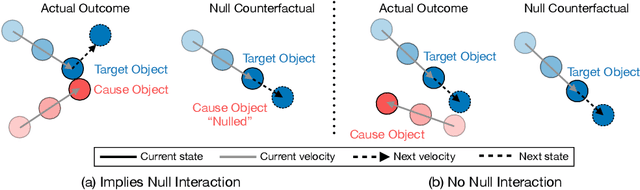
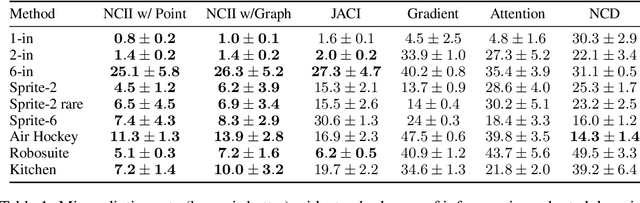
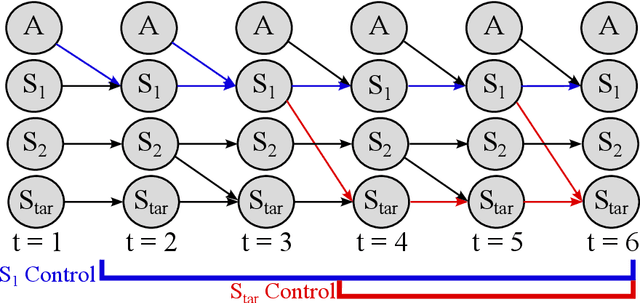

Hindsight relabeling is a powerful tool for overcoming sparsity in goal-conditioned reinforcement learning (GCRL), especially in certain domains such as navigation and locomotion. However, hindsight relabeling can struggle in object-centric domains. For example, suppose that the goal space consists of a robotic arm pushing a particular target block to a goal location. In this case, hindsight relabeling will give high rewards to any trajectory that does not interact with the block. However, these behaviors are only useful when the object is already at the goal -- an extremely rare case in practice. A dataset dominated by these kinds of trajectories can complicate learning and lead to failures. In object-centric domains, one key intuition is that meaningful trajectories are often characterized by object-object interactions such as pushing the block with the gripper. To leverage this intuition, we introduce Hindsight Relabeling using Interactions (HInt), which combines interactions with hindsight relabeling to improve the sample efficiency of downstream RL. However because interactions do not have a consensus statistical definition tractable for downstream GCRL, we propose a definition of interactions based on the concept of null counterfactual: a cause object is interacting with a target object if, in a world where the cause object did not exist, the target object would have different transition dynamics. We leverage this definition to infer interactions in Null Counterfactual Interaction Inference (NCII), which uses a "nulling'' operation with a learned model to infer interactions. NCII is able to achieve significantly improved interaction inference accuracy in both simple linear dynamics domains and dynamic robotic domains in Robosuite, Robot Air Hockey, and Franka Kitchen and HInt improves sample efficiency by up to 4x.
* Published at ICLR 2025
Pairwise or Pointwise? Evaluating Feedback Protocols for Bias in LLM-Based Evaluation
Apr 20, 2025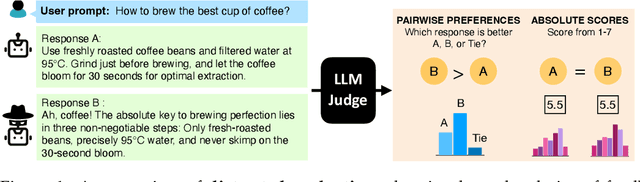

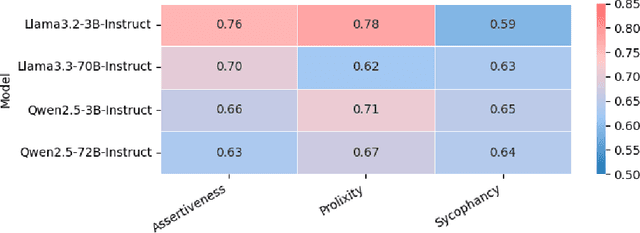

Large Language Models (LLMs) are widely used as proxies for human labelers in both training (Reinforcement Learning from AI Feedback) and large-scale response evaluation (LLM-as-a-judge). Alignment and evaluation are critical components in the development of reliable LLMs, and the choice of feedback protocol plays a central role in both but remains understudied. In this work, we show that the choice of feedback protocol (absolute scores versus relative preferences) can significantly affect evaluation reliability and induce systematic biases. In particular, we show that pairwise evaluation protocols are more vulnerable to distracted evaluation. Generator models can exploit spurious attributes (or distractor features) favored by the LLM judge, resulting in inflated scores for lower-quality outputs and misleading training signals. We find that absolute scoring is more robust to such manipulation, producing judgments that better reflect response quality and are less influenced by distractor features. Our results demonstrate that generator models can flip preferences by embedding distractor features, skewing LLM-as-a-judge comparisons and leading to inaccurate conclusions about model quality in benchmark evaluations. Pairwise preferences flip in about 35% of the cases, compared to only 9% for absolute scores. We offer recommendations for choosing feedback protocols based on dataset characteristics and evaluation objectives.
An Optimal Discriminator Weighted Imitation Perspective for Reinforcement Learning
Apr 17, 2025We introduce Iterative Dual Reinforcement Learning (IDRL), a new method that takes an optimal discriminator-weighted imitation view of solving RL. Our method is motivated by a simple experiment in which we find training a discriminator using the offline dataset plus an additional expert dataset and then performing discriminator-weighted behavior cloning gives strong results on various types of datasets. That optimal discriminator weight is quite similar to the learned visitation distribution ratio in Dual-RL, however, we find that current Dual-RL methods do not correctly estimate that ratio. In IDRL, we propose a correction method to iteratively approach the optimal visitation distribution ratio in the offline dataset given no addtional expert dataset. During each iteration, IDRL removes zero-weight suboptimal transitions using the learned ratio from the previous iteration and runs Dual-RL on the remaining subdataset. This can be seen as replacing the behavior visitation distribution with the optimized visitation distribution from the previous iteration, which theoretically gives a curriculum of improved visitation distribution ratios that are closer to the optimal discriminator weight. We verify the effectiveness of IDRL on various kinds of offline datasets, including D4RL datasets and more realistic corrupted demonstrations. IDRL beats strong Primal-RL and Dual-RL baselines in terms of both performance and stability, on all datasets.
Fast Adaptation with Behavioral Foundation Models
Apr 10, 2025Unsupervised zero-shot reinforcement learning (RL) has emerged as a powerful paradigm for pretraining behavioral foundation models (BFMs), enabling agents to solve a wide range of downstream tasks specified via reward functions in a zero-shot fashion, i.e., without additional test-time learning or planning. This is achieved by learning self-supervised task embeddings alongside corresponding near-optimal behaviors and incorporating an inference procedure to directly retrieve the latent task embedding and associated policy for any given reward function. Despite promising results, zero-shot policies are often suboptimal due to errors induced by the unsupervised training process, the embedding, and the inference procedure. In this paper, we focus on devising fast adaptation strategies to improve the zero-shot performance of BFMs in a few steps of online interaction with the environment while avoiding any performance drop during the adaptation process. Notably, we demonstrate that existing BFMs learn a set of skills containing more performant policies than those identified by their inference procedure, making them well-suited for fast adaptation. Motivated by this observation, we propose both actor-critic and actor-only fast adaptation strategies that search in the low-dimensional task-embedding space of the pre-trained BFM to rapidly improve the performance of its zero-shot policies on any downstream task. Notably, our approach mitigates the initial "unlearning" phase commonly observed when fine-tuning pre-trained RL models. We evaluate our fast adaptation strategies on top of four state-of-the-art zero-shot RL methods in multiple navigation and locomotion domains. Our results show that they achieve 10-40% improvement over their zero-shot performance in a few tens of episodes, outperforming existing baselines.
Supervised Reward Inference
Feb 25, 2025Existing approaches to reward inference from behavior typically assume that humans provide demonstrations according to specific models of behavior. However, humans often indicate their goals through a wide range of behaviors, from actions that are suboptimal due to poor planning or execution to behaviors which are intended to communicate goals rather than achieve them. We propose that supervised learning offers a unified framework to infer reward functions from any class of behavior, and show that such an approach is asymptotically Bayes-optimal under mild assumptions. Experiments on simulated robotic manipulation tasks show that our method can efficiently infer rewards from a wide variety of arbitrarily suboptimal demonstrations.
Influencing Humans to Conform to Preference Models for RLHF
Jan 11, 2025



Designing a reinforcement learning from human feedback (RLHF) algorithm to approximate a human's unobservable reward function requires assuming, implicitly or explicitly, a model of human preferences. A preference model that poorly describes how humans generate preferences risks learning a poor approximation of the human's reward function. In this paper, we conduct three human studies to asses whether one can influence the expression of real human preferences to more closely conform to a desired preference model. Importantly, our approach does not seek to alter the human's unobserved reward function. Rather, we change how humans use this reward function to generate preferences, such that they better match whatever preference model is assumed by a particular RLHF algorithm. We introduce three interventions: showing humans the quantities that underlie a preference model, which is normally unobservable information derived from the reward function; training people to follow a specific preference model; and modifying the preference elicitation question. All intervention types show significant effects, providing practical tools to improve preference data quality and the resultant alignment of the learned reward functions. Overall we establish a novel research direction in model alignment: designing interfaces and training interventions to increase human conformance with the modeling assumptions of the algorithm that will learn from their input.
RL Zero: Zero-Shot Language to Behaviors without any Supervision
Dec 07, 2024Rewards remain an uninterpretable way to specify tasks for Reinforcement Learning, as humans are often unable to predict the optimal behavior of any given reward function, leading to poor reward design and reward hacking. Language presents an appealing way to communicate intent to agents and bypass reward design, but prior efforts to do so have been limited by costly and unscalable labeling efforts. In this work, we propose a method for a completely unsupervised alternative to grounding language instructions in a zero-shot manner to obtain policies. We present a solution that takes the form of imagine, project, and imitate: The agent imagines the observation sequence corresponding to the language description of a task, projects the imagined sequence to our target domain, and grounds it to a policy. Video-language models allow us to imagine task descriptions that leverage knowledge of tasks learned from internet-scale video-text mappings. The challenge remains to ground these generations to a policy. In this work, we show that we can achieve a zero-shot language-to-behavior policy by first grounding the imagined sequences in real observations of an unsupervised RL agent and using a closed-form solution to imitation learning that allows the RL agent to mimic the grounded observations. Our method, RLZero, is the first to our knowledge to show zero-shot language to behavior generation abilities without any supervision on a variety of tasks on simulated domains. We further show that RLZero can also generate policies zero-shot from cross-embodied videos such as those scraped from YouTube.
Predicting Future Actions of Reinforcement Learning Agents
Oct 29, 2024


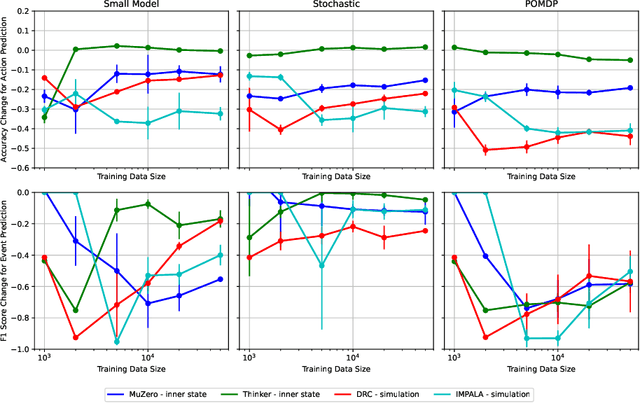
As reinforcement learning agents become increasingly deployed in real-world scenarios, predicting future agent actions and events during deployment is important for facilitating better human-agent interaction and preventing catastrophic outcomes. This paper experimentally evaluates and compares the effectiveness of future action and event prediction for three types of RL agents: explicitly planning, implicitly planning, and non-planning. We employ two approaches: the inner state approach, which involves predicting based on the inner computations of the agents (e.g., plans or neuron activations), and a simulation-based approach, which involves unrolling the agent in a learned world model. Our results show that the plans of explicitly planning agents are significantly more informative for prediction than the neuron activations of the other types. Furthermore, using internal plans proves more robust to model quality compared to simulation-based approaches when predicting actions, while the results for event prediction are more mixed. These findings highlight the benefits of leveraging inner states and simulations to predict future agent actions and events, thereby improving interaction and safety in real-world deployments.
SkiLD: Unsupervised Skill Discovery Guided by Factor Interactions
Oct 24, 2024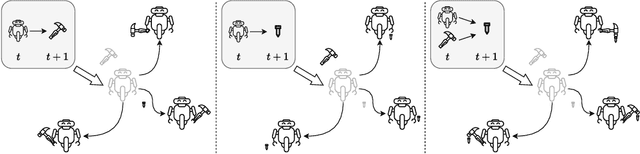
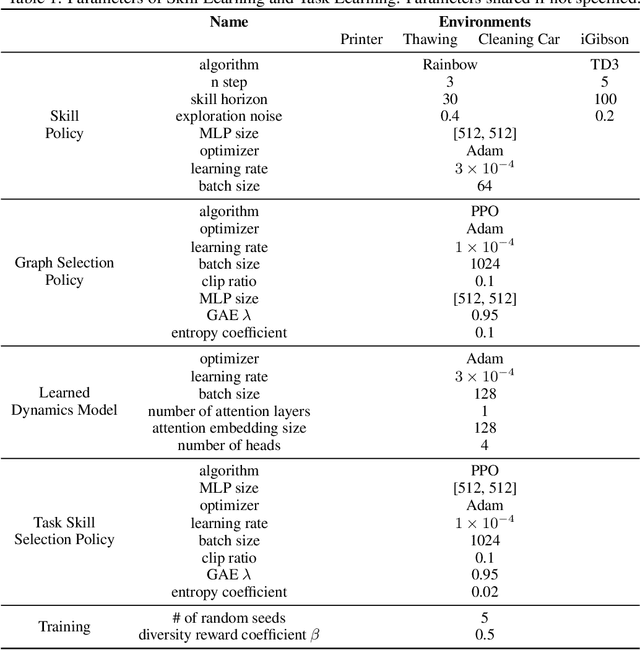
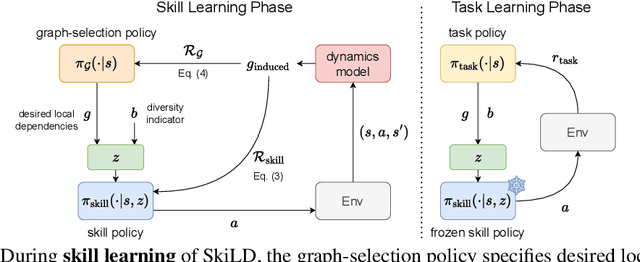
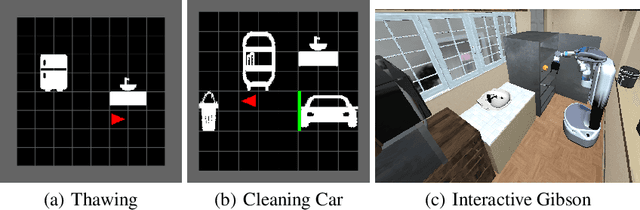
Unsupervised skill discovery carries the promise that an intelligent agent can learn reusable skills through autonomous, reward-free environment interaction. Existing unsupervised skill discovery methods learn skills by encouraging distinguishable behaviors that cover diverse states. However, in complex environments with many state factors (e.g., household environments with many objects), learning skills that cover all possible states is impossible, and naively encouraging state diversity often leads to simple skills that are not ideal for solving downstream tasks. This work introduces Skill Discovery from Local Dependencies (Skild), which leverages state factorization as a natural inductive bias to guide the skill learning process. The key intuition guiding Skild is that skills that induce <b>diverse interactions</b> between state factors are often more valuable for solving downstream tasks. To this end, Skild develops a novel skill learning objective that explicitly encourages the mastering of skills that effectively induce different interactions within an environment. We evaluate Skild in several domains with challenging, long-horizon sparse reward tasks including a realistic simulated household robot domain, where Skild successfully learns skills with clear semantic meaning and shows superior performance compared to existing unsupervised reinforcement learning methods that only maximize state coverage.