 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizable Dense Reward for Long-Horizon Robotic Tasks
Mar 31, 2026Existing robotic foundation policies are trained primarily via large-scale imitation learning. While such models demonstrate strong capabilities, they often struggle with long-horizon tasks due to distribution shift and error accumulation. While reinforcement learning (RL) can finetune these models, it cannot work well across diverse tasks without manual reward engineering. We propose VLLR, a dense reward framework combining (1) an extrinsic reward from Large Language Models (LLMs) and Vision-Language Models (VLMs) for task progress recognition, and (2) an intrinsic reward based on policy self-certainty. VLLR uses LLMs to decompose tasks into verifiable subtasks and then VLMs to estimate progress to initialize the value function for a brief warm-up phase, avoiding prohibitive inference cost during full training; and self-certainty provides per-step intrinsic guidance throughout PPO finetuning. Ablation studies reveal complementary benefits: VLM-based value initialization primarily improves task completion efficiency, while self-certainty primarily enhances success rates, particularly on out-of-distribution tasks. On the CHORES benchmark covering mobile manipulation and navigation, VLLR achieves up to 56% absolute success rate gains over the pretrained policy, up to 5% gains over state-of-the-art RL finetuning methods on in-distribution tasks, and up to $10\%$ gains on out-of-distribution tasks, all without manual reward engineering. Additional visualizations can be found in https://silongyong.github.io/vllr_project_page/
Latent Particle World Models: Self-supervised Object-centric Stochastic Dynamics Modeling
Mar 04, 2026We introduce Latent Particle World Model (LPWM), a self-supervised object-centric world model scaled to real-world multi-object datasets and applicable in decision-making. LPWM autonomously discovers keypoints, bounding boxes, and object masks directly from video data, enabling it to learn rich scene decompositions without supervision. Our architecture is trained end-to-end purely from videos and supports flexible conditioning on actions, language, and image goals. LPWM models stochastic particle dynamics via a novel latent action module and achieves state-of-the-art results on diverse real-world and synthetic datasets. Beyond stochastic video modeling, LPWM is readily applicable to decision-making, including goal-conditioned imitation learning, as we demonstrate in the paper. Code, data, pre-trained models and video rollouts are available: https://taldatech.github.io/lpwm-web
Self-Refining Vision Language Model for Robotic Failure Detection and Reasoning
Feb 12, 2026Reasoning about failures is crucial for building reliable and trustworthy robotic systems. Prior approaches either treat failure reasoning as a closed-set classification problem or assume access to ample human annotations. Failures in the real world are typically subtle, combinatorial, and difficult to enumerate, whereas rich reasoning labels are expensive to acquire. We address this problem by introducing ARMOR: Adaptive Round-based Multi-task mOdel for Robotic failure detection and reasoning. We formulate detection and reasoning as a multi-task self-refinement process, where the model iteratively predicts detection outcomes and natural language reasoning conditioned on past outputs. During training, ARMOR learns from heterogeneous supervision - large-scale sparse binary labels and small-scale rich reasoning annotations - optimized via a combination of offline and online imitation learning. At inference time, ARMOR generates multiple refinement trajectories and selects the most confident prediction via a self-certainty metric. Experiments across diverse environments show that ARMOR achieves state-of-the-art performance by improving over the previous approaches by up to 30% on failure detection rate and up to 100% in reasoning measured through LLM fuzzy match score, demonstrating robustness to heterogeneous supervision and open-ended reasoning beyond predefined failure modes. We provide dditional visualizations on our website: https://sites.google.com/utexas.edu/armor
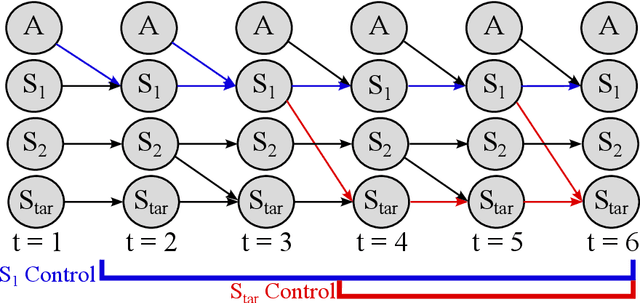
Hierarchical Entity-centric Reinforcement Learning with Factored Subgoal Diffusion
Feb 02, 2026We propose a hierarchical entity-centric framework for offline Goal-Conditioned Reinforcement Learning (GCRL) that combines subgoal decomposition with factored structure to solve long-horizon tasks in domains with multiple entities. Achieving long-horizon goals in complex environments remains a core challenge in Reinforcement Learning (RL). Domains with multiple entities are particularly difficult due to their combinatorial complexity. GCRL facilitates generalization across goals and the use of subgoal structure, but struggles with high-dimensional observations and combinatorial state-spaces, especially under sparse reward. We employ a two-level hierarchy composed of a value-based GCRL agent and a factored subgoal-generating conditional diffusion model. The RL agent and subgoal generator are trained independently and composed post hoc through selective subgoal generation based on the value function, making the approach modular and compatible with existing GCRL algorithms. We introduce new variations to benchmark tasks that highlight the challenges of multi-entity domains, and show that our method consistently boosts performance of the underlying RL agent on image-based long-horizon tasks with sparse rewards, achieving over 150% higher success rates on the hardest task in our suite and generalizing to increasing horizons and numbers of entities. Rollout videos are provided at: https://sites.google.com/view/hecrl
Null Counterfactual Factor Interactions for Goal-Conditioned Reinforcement Learning
May 06, 2025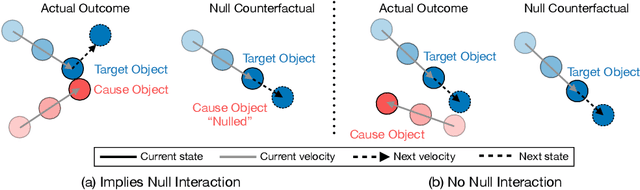
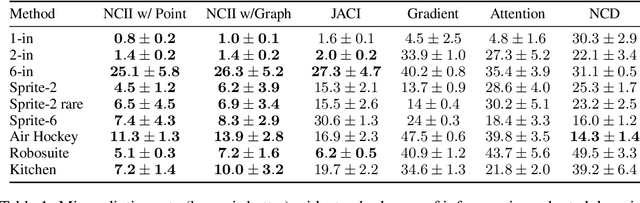

Hindsight relabeling is a powerful tool for overcoming sparsity in goal-conditioned reinforcement learning (GCRL), especially in certain domains such as navigation and locomotion. However, hindsight relabeling can struggle in object-centric domains. For example, suppose that the goal space consists of a robotic arm pushing a particular target block to a goal location. In this case, hindsight relabeling will give high rewards to any trajectory that does not interact with the block. However, these behaviors are only useful when the object is already at the goal -- an extremely rare case in practice. A dataset dominated by these kinds of trajectories can complicate learning and lead to failures. In object-centric domains, one key intuition is that meaningful trajectories are often characterized by object-object interactions such as pushing the block with the gripper. To leverage this intuition, we introduce Hindsight Relabeling using Interactions (HInt), which combines interactions with hindsight relabeling to improve the sample efficiency of downstream RL. However because interactions do not have a consensus statistical definition tractable for downstream GCRL, we propose a definition of interactions based on the concept of null counterfactual: a cause object is interacting with a target object if, in a world where the cause object did not exist, the target object would have different transition dynamics. We leverage this definition to infer interactions in Null Counterfactual Interaction Inference (NCII), which uses a "nulling'' operation with a learned model to infer interactions. NCII is able to achieve significantly improved interaction inference accuracy in both simple linear dynamics domains and dynamic robotic domains in Robosuite, Robot Air Hockey, and Franka Kitchen and HInt improves sample efficiency by up to 4x.
* Published at ICLR 2025
EC-Diffuser: Multi-Object Manipulation via Entity-Centric Behavior Generation
Dec 25, 2024



Object manipulation is a common component of everyday tasks, but learning to manipulate objects from high-dimensional observations presents significant challenges. These challenges are heightened in multi-object environments due to the combinatorial complexity of the state space as well as of the desired behaviors. While recent approaches have utilized large-scale offline data to train models from pixel observations, achieving performance gains through scaling, these methods struggle with compositional generalization in unseen object configurations with constrained network and dataset sizes. To address these issues, we propose a novel behavioral cloning (BC) approach that leverages object-centric representations and an entity-centric Transformer with diffusion-based optimization, enabling efficient learning from offline image data. Our method first decomposes observations into an object-centric representation, which is then processed by our entity-centric Transformer that computes attention at the object level, simultaneously predicting object dynamics and the agent's actions. Combined with the ability of diffusion models to capture multi-modal behavior distributions, this results in substantial performance improvements in multi-object tasks and, more importantly, enables compositional generalization. We present BC agents capable of zero-shot generalization to tasks with novel compositions of objects and goals, including larger numbers of objects than seen during training. We provide video rollouts on our webpage: https://sites.google.com/view/ec-diffuser.
Robot Air Hockey: A Manipulation Testbed for Robot Learning with Reinforcement Learning
May 06, 2024



Reinforcement Learning is a promising tool for learning complex policies even in fast-moving and object-interactive domains where human teleoperation or hard-coded policies might fail. To effectively reflect this challenging category of tasks, we introduce a dynamic, interactive RL testbed based on robot air hockey. By augmenting air hockey with a large family of tasks ranging from easy tasks like reaching, to challenging ones like pushing a block by hitting it with a puck, as well as goal-based and human-interactive tasks, our testbed allows a varied assessment of RL capabilities. The robot air hockey testbed also supports sim-to-real transfer with three domains: two simulators of increasing fidelity and a real robot system. Using a dataset of demonstration data gathered through two teleoperation systems: a virtualized control environment, and human shadowing, we assess the testbed with behavior cloning, offline RL, and RL from scratch.
Learning Generalizable Tool-use Skills through Trajectory Generation
Oct 06, 2023



Autonomous systems that efficiently utilize tools can assist humans in completing many common tasks such as cooking and cleaning. However, current systems fall short of matching human-level of intelligence in terms of adapting to novel tools. Prior works based on affordance often make strong assumptions about the environments and cannot scale to more complex, contact-rich tasks. In this work, we tackle this challenge and explore how agents can learn to use previously unseen tools to manipulate deformable objects. We propose to learn a generative model of the tool-use trajectories as a sequence of point clouds, which generalizes to different tool shapes. Given any novel tool, we first generate a tool-use trajectory and then optimize the sequence of tool poses to align with the generated trajectory. We train a single model for four different challenging deformable object manipulation tasks. Our model is trained with demonstration data from just a single tool for each task and is able to generalize to various novel tools, significantly outperforming baselines. Additional materials can be found on our project website: https://sites.google.com/view/toolgen.
Planning with Spatial-Temporal Abstraction from Point Clouds for Deformable Object Manipulation
Oct 27, 2022Effective planning of long-horizon deformable object manipulation requires suitable abstractions at both the spatial and temporal levels. Previous methods typically either focus on short-horizon tasks or make strong assumptions that full-state information is available, which prevents their use on deformable objects. In this paper, we propose PlAnning with Spatial-Temporal Abstraction (PASTA), which incorporates both spatial abstraction (reasoning about objects and their relations to each other) and temporal abstraction (reasoning over skills instead of low-level actions). Our framework maps high-dimension 3D observations such as point clouds into a set of latent vectors and plans over skill sequences on top of the latent set representation. We show that our method can effectively perform challenging sequential deformable object manipulation tasks in the real world, which require combining multiple tool-use skills such as cutting with a knife, pushing with a pusher, and spreading the dough with a roller.
Learning Closed-loop Dough Manipulation Using a Differentiable Reset Module
Jul 11, 2022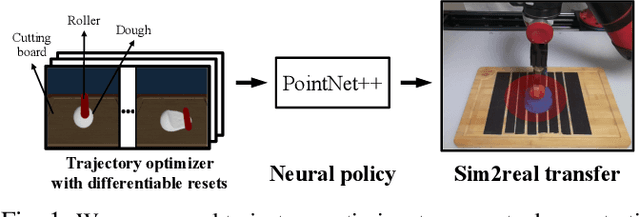
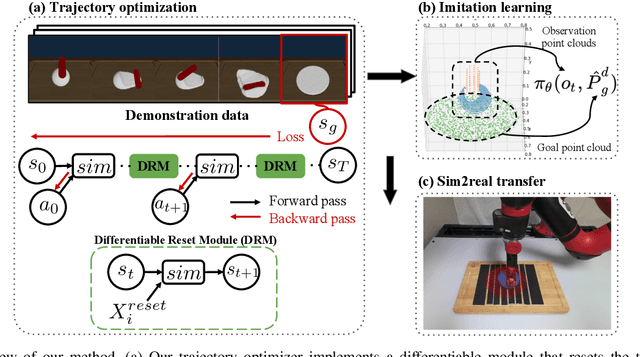
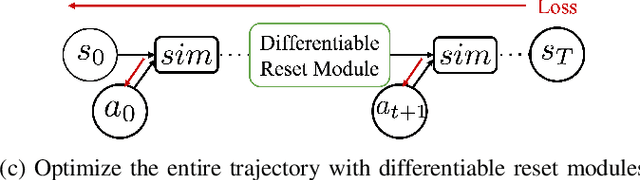
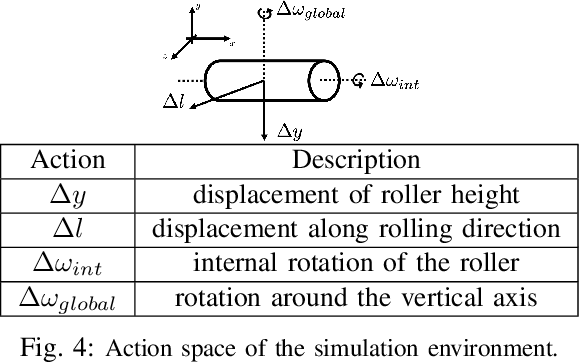
Deformable object manipulation has many applications such as cooking and laundry folding in our daily lives. Manipulating elastoplastic objects such as dough is particularly challenging because dough lacks a compact state representation and requires contact-rich interactions. We consider the task of flattening a piece of dough into a specific shape from RGB-D images. While the task is seemingly intuitive for humans, there exist local optima for common approaches such as naive trajectory optimization. We propose a novel trajectory optimizer that optimizes through a differentiable "reset" module, transforming a single-stage, fixed-initialization trajectory into a multistage, multi-initialization trajectory where all stages are optimized jointly. We then train a closed-loop policy on the demonstrations generated by our trajectory optimizer. Our policy receives partial point clouds as input, allowing ease of transfer from simulation to the real world. We show that our policy can perform real-world dough manipulation, flattening a ball of dough into a target shape.