 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurrent Agents Fail to Leverage World Model as Tool for Foresight
Jan 08, 2026Agents built on vision-language models increasingly face tasks that demand anticipating future states rather than relying on short-horizon reasoning. Generative world models offer a promising remedy: agents could use them as external simulators to foresee outcomes before acting. This paper empirically examines whether current agents can leverage such world models as tools to enhance their cognition. Across diverse agentic and visual question answering tasks, we observe that some agents rarely invoke simulation (fewer than 1%), frequently misuse predicted rollouts (approximately 15%), and often exhibit inconsistent or even degraded performance (up to 5%) when simulation is available or enforced. Attribution analysis further indicates that the primary bottleneck lies in the agents' capacity to decide when to simulate, how to interpret predicted outcomes, and how to integrate foresight into downstream reasoning. These findings underscore the need for mechanisms that foster calibrated, strategic interaction with world models, paving the way toward more reliable anticipatory cognition in future agent systems.
Flexible Multitask Learning with Factorized Diffusion Policy
Dec 26, 2025Multitask learning poses significant challenges due to the highly multimodal and diverse nature of robot action distributions. However, effectively fitting policies to these complex task distributions is often difficult, and existing monolithic models often underfit the action distribution and lack the flexibility required for efficient adaptation. We introduce a novel modular diffusion policy framework that factorizes complex action distributions into a composition of specialized diffusion models, each capturing a distinct sub-mode of the behavior space for a more effective overall policy. In addition, this modular structure enables flexible policy adaptation to new tasks by adding or fine-tuning components, which inherently mitigates catastrophic forgetting. Empirically, across both simulation and real-world robotic manipulation settings, we illustrate how our method consistently outperforms strong modular and monolithic baselines.
Real-to-Sim Robot Policy Evaluation with Gaussian Splatting Simulation of Soft-Body Interactions
Nov 06, 2025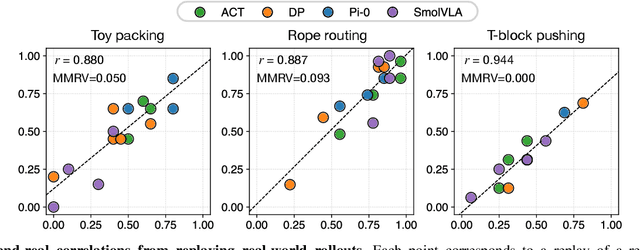

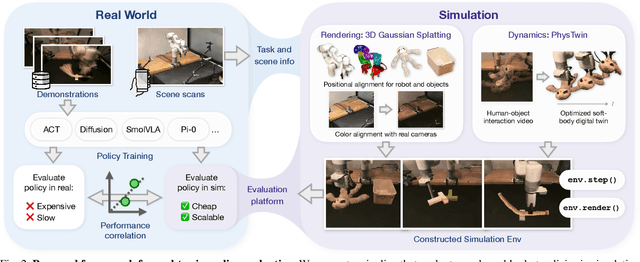
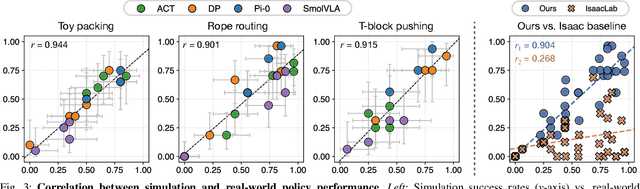
Robotic manipulation policies are advancing rapidly, but their direct evaluation in the real world remains costly, time-consuming, and difficult to reproduce, particularly for tasks involving deformable objects. Simulation provides a scalable and systematic alternative, yet existing simulators often fail to capture the coupled visual and physical complexity of soft-body interactions. We present a real-to-sim policy evaluation framework that constructs soft-body digital twins from real-world videos and renders robots, objects, and environments with photorealistic fidelity using 3D Gaussian Splatting. We validate our approach on representative deformable manipulation tasks, including plush toy packing, rope routing, and T-block pushing, demonstrating that simulated rollouts correlate strongly with real-world execution performance and reveal key behavioral patterns of learned policies. Our results suggest that combining physics-informed reconstruction with high-quality rendering enables reproducible, scalable, and accurate evaluation of robotic manipulation policies. Website: https://real2sim-eval.github.io/
Robotic Manipulation by Imitating Generated Videos Without Physical Demonstrations
Jul 01, 2025This work introduces Robots Imitating Generated Videos (RIGVid), a system that enables robots to perform complex manipulation tasks--such as pouring, wiping, and mixing--purely by imitating AI-generated videos, without requiring any physical demonstrations or robot-specific training. Given a language command and an initial scene image, a video diffusion model generates potential demonstration videos, and a vision-language model (VLM) automatically filters out results that do not follow the command. A 6D pose tracker then extracts object trajectories from the video, and the trajectories are retargeted to the robot in an embodiment-agnostic fashion. Through extensive real-world evaluations, we show that filtered generated videos are as effective as real demonstrations, and that performance improves with generation quality. We also show that relying on generated videos outperforms more compact alternatives such as keypoint prediction using VLMs, and that strong 6D pose tracking outperforms other ways to extract trajectories, such as dense feature point tracking. These findings suggest that videos produced by a state-of-the-art off-the-shelf model can offer an effective source of supervision for robotic manipulation.
Particle-Grid Neural Dynamics for Learning Deformable Object Models from RGB-D Videos
Jun 18, 2025Modeling the dynamics of deformable objects is challenging due to their diverse physical properties and the difficulty of estimating states from limited visual information. We address these challenges with a neural dynamics framework that combines object particles and spatial grids in a hybrid representation. Our particle-grid model captures global shape and motion information while predicting dense particle movements, enabling the modeling of objects with varied shapes and materials. Particles represent object shapes, while the spatial grid discretizes the 3D space to ensure spatial continuity and enhance learning efficiency. Coupled with Gaussian Splattings for visual rendering, our framework achieves a fully learning-based digital twin of deformable objects and generates 3D action-conditioned videos. Through experiments, we demonstrate that our model learns the dynamics of diverse objects -- such as ropes, cloths, stuffed animals, and paper bags -- from sparse-view RGB-D recordings of robot-object interactions, while also generalizing at the category level to unseen instances. Our approach outperforms state-of-the-art learning-based and physics-based simulators, particularly in scenarios with limited camera views. Furthermore, we showcase the utility of our learned models in model-based planning, enabling goal-conditioned object manipulation across a range of tasks. The project page is available at https://kywind.github.io/pgnd .
Tool-as-Interface: Learning Robot Policies from Human Tool Usage through Imitation Learning
Apr 06, 2025Tool use is critical for enabling robots to perform complex real-world tasks, and leveraging human tool-use data can be instrumental for teaching robots. However, existing data collection methods like teleoperation are slow, prone to control delays, and unsuitable for dynamic tasks. In contrast, human natural data, where humans directly perform tasks with tools, offers natural, unstructured interactions that are both efficient and easy to collect. Building on the insight that humans and robots can share the same tools, we propose a framework to transfer tool-use knowledge from human data to robots. Using two RGB cameras, our method generates 3D reconstruction, applies Gaussian splatting for novel view augmentation, employs segmentation models to extract embodiment-agnostic observations, and leverages task-space tool-action representations to train visuomotor policies. We validate our approach on diverse real-world tasks, including meatball scooping, pan flipping, wine bottle balancing, and other complex tasks. Our method achieves a 71\% higher average success rate compared to diffusion policies trained with teleoperation data and reduces data collection time by 77\%, with some tasks solvable only by our framework. Compared to hand-held gripper, our method cuts data collection time by 41\%. Additionally, our method bridges the embodiment gap, improves robustness to variations in camera viewpoints and robot configurations, and generalizes effectively across objects and spatial setups.
Learning Coordinated Bimanual Manipulation Policies using State Diffusion and Inverse Dynamics Models
Mar 30, 2025When performing tasks like laundry, humans naturally coordinate both hands to manipulate objects and anticipate how their actions will change the state of the clothes. However, achieving such coordination in robotics remains challenging due to the need to model object movement, predict future states, and generate precise bimanual actions. In this work, we address these challenges by infusing the predictive nature of human manipulation strategies into robot imitation learning. Specifically, we disentangle task-related state transitions from agent-specific inverse dynamics modeling to enable effective bimanual coordination. Using a demonstration dataset, we train a diffusion model to predict future states given historical observations, envisioning how the scene evolves. Then, we use an inverse dynamics model to compute robot actions that achieve the predicted states. Our key insight is that modeling object movement can help learning policies for bimanual coordination manipulation tasks. Evaluating our framework across diverse simulation and real-world manipulation setups, including multimodal goal configurations, bimanual manipulation, deformable objects, and multi-object setups, we find that it consistently outperforms state-of-the-art state-to-action mapping policies. Our method demonstrates a remarkable capacity to navigate multimodal goal configurations and action distributions, maintain stability across different control modes, and synthesize a broader range of behaviors than those present in the demonstration dataset.
Localized Graph-Based Neural Dynamics Models for Terrain Manipulation
Mar 30, 2025

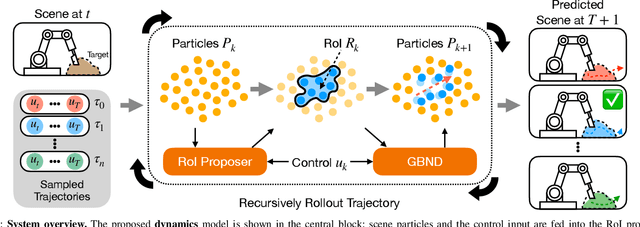

Predictive models can be particularly helpful for robots to effectively manipulate terrains in construction sites and extraterrestrial surfaces. However, terrain state representations become extremely high-dimensional especially to capture fine-resolution details and when depth is unknown or unbounded. This paper introduces a learning-based approach for terrain dynamics modeling and manipulation, leveraging the Graph-based Neural Dynamics (GBND) framework to represent terrain deformation as motion of a graph of particles. Based on the principle that the moving portion of a terrain is usually localized, our approach builds a large terrain graph (potentially millions of particles) but only identifies a very small active subgraph (hundreds of particles) for predicting the outcomes of robot-terrain interaction. To minimize the size of the active subgraph we introduce a learning-based approach that identifies a small region of interest (RoI) based on the robot's control inputs and the current scene. We also introduce a novel domain boundary feature encoding that allows GBNDs to perform accurate dynamics prediction in the RoI interior while avoiding particle penetration through RoI boundaries. Our proposed method is both orders of magnitude faster than naive GBND and it achieves better overall prediction accuracy. We further evaluated our framework on excavation and shaping tasks on terrain with different granularity.
PhysGen3D: Crafting a Miniature Interactive World from a Single Image
Mar 26, 2025Envisioning physically plausible outcomes from a single image requires a deep understanding of the world's dynamics. To address this, we introduce PhysGen3D, a novel framework that transforms a single image into an amodal, camera-centric, interactive 3D scene. By combining advanced image-based geometric and semantic understanding with physics-based simulation, PhysGen3D creates an interactive 3D world from a static image, enabling us to "imagine" and simulate future scenarios based on user input. At its core, PhysGen3D estimates 3D shapes, poses, physical and lighting properties of objects, thereby capturing essential physical attributes that drive realistic object interactions. This framework allows users to specify precise initial conditions, such as object speed or material properties, for enhanced control over generated video outcomes. We evaluate PhysGen3D's performance against closed-source state-of-the-art (SOTA) image-to-video models, including Pika, Kling, and Gen-3, showing PhysGen3D's capacity to generate videos with realistic physics while offering greater flexibility and fine-grained control. Our results show that PhysGen3D achieves a unique balance of photorealism, physical plausibility, and user-driven interactivity, opening new possibilities for generating dynamic, physics-grounded video from an image.
KUDA: Keypoints to Unify Dynamics Learning and Visual Prompting for Open-Vocabulary Robotic Manipulation
Mar 13, 2025With the rapid advancement of large language models (LLMs) and vision-language models (VLMs), significant progress has been made in developing open-vocabulary robotic manipulation systems. However, many existing approaches overlook the importance of object dynamics, limiting their applicability to more complex, dynamic tasks. In this work, we introduce KUDA, an open-vocabulary manipulation system that integrates dynamics learning and visual prompting through keypoints, leveraging both VLMs and learning-based neural dynamics models. Our key insight is that a keypoint-based target specification is simultaneously interpretable by VLMs and can be efficiently translated into cost functions for model-based planning. Given language instructions and visual observations, KUDA first assigns keypoints to the RGB image and queries the VLM to generate target specifications. These abstract keypoint-based representations are then converted into cost functions, which are optimized using a learned dynamics model to produce robotic trajectories. We evaluate KUDA on a range of manipulation tasks, including free-form language instructions across diverse object categories, multi-object interactions, and deformable or granular objects, demonstrating the effectiveness of our framework. The project page is available at http://kuda-dynamics.github.io.