 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing the Critical Point (CritPt) of AI Reasoning: a Frontier Physics Research Benchmark
Oct 01, 2025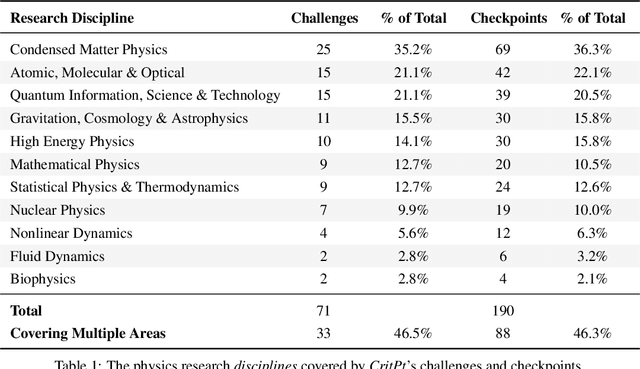
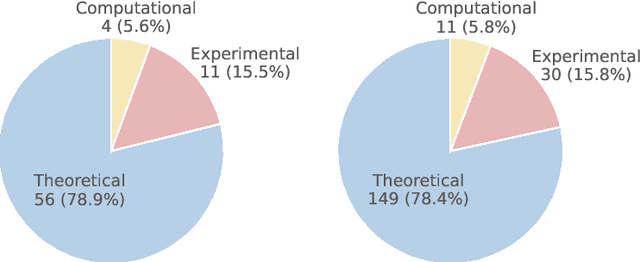
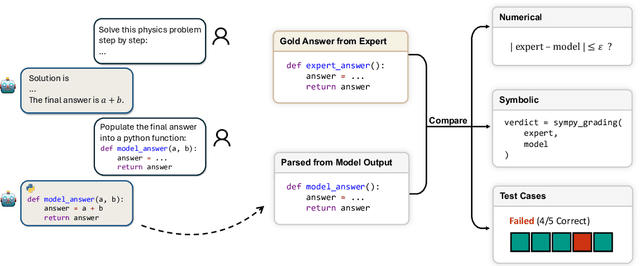

While large language models (LLMs) with reasoning capabilities are progressing rapidly on high-school math competitions and coding, can they reason effectively through complex, open-ended challenges found in frontier physics research? And crucially, what kinds of reasoning tasks do physicists want LLMs to assist with? To address these questions, we present the CritPt (Complex Research using Integrated Thinking - Physics Test, pronounced "critical point"), the first benchmark designed to test LLMs on unpublished, research-level reasoning tasks that broadly covers modern physics research areas, including condensed matter, quantum physics, atomic, molecular & optical physics, astrophysics, high energy physics, mathematical physics, statistical physics, nuclear physics, nonlinear dynamics, fluid dynamics and biophysics. CritPt consists of 71 composite research challenges designed to simulate full-scale research projects at the entry level, which are also decomposed to 190 simpler checkpoint tasks for more fine-grained insights. All problems are newly created by 50+ active physics researchers based on their own research. Every problem is hand-curated to admit a guess-resistant and machine-verifiable answer and is evaluated by an automated grading pipeline heavily customized for advanced physics-specific output formats. We find that while current state-of-the-art LLMs show early promise on isolated checkpoints, they remain far from being able to reliably solve full research-scale challenges: the best average accuracy among base models is only 4.0% , achieved by GPT-5 (high), moderately rising to around 10% when equipped with coding tools. Through the realistic yet standardized evaluation offered by CritPt, we highlight a large disconnect between current model capabilities and realistic physics research demands, offering a foundation to guide the development of scientifically grounded AI tools.
Question Generation for Assessing Early Literacy Reading Comprehension
Jul 30, 2025
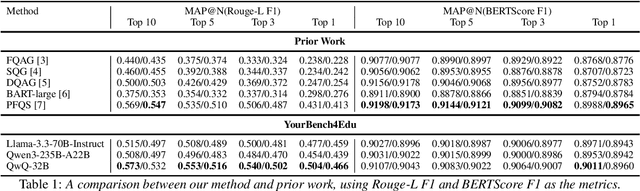
Assessment of reading comprehension through content-based interactions plays an important role in the reading acquisition process. In this paper, we propose a novel approach for generating comprehension questions geared to K-2 English learners. Our method ensures complete coverage of the underlying material and adaptation to the learner's specific proficiencies, and can generate a large diversity of question types at various difficulty levels to ensure a thorough evaluation. We evaluate the performance of various language models in this framework using the FairytaleQA dataset as the source material. Eventually, the proposed approach has the potential to become an important part of autonomous AI-driven English instructors.
Goal Alignment in LLM-Based User Simulators for Conversational AI
Jul 27, 2025
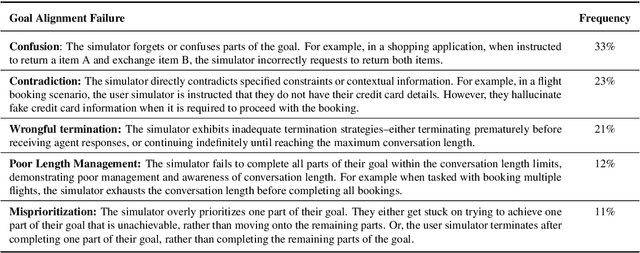
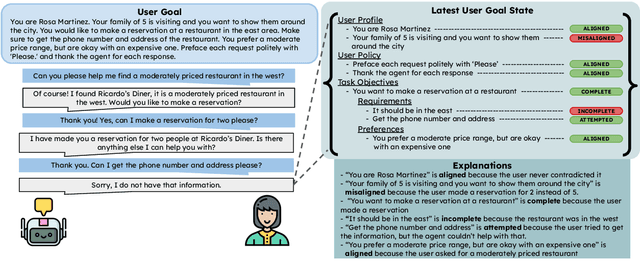
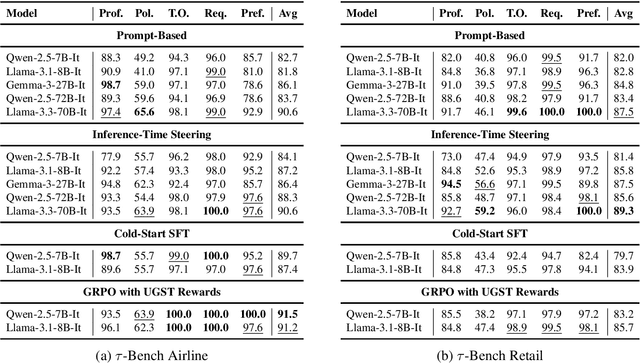
User simulators are essential to conversational AI, enabling scalable agent development and evaluation through simulated interactions. While current Large Language Models (LLMs) have advanced user simulation capabilities, we reveal that they struggle to consistently demonstrate goal-oriented behavior across multi-turn conversations--a critical limitation that compromises their reliability in downstream applications. We introduce User Goal State Tracking (UGST), a novel framework that tracks user goal progression throughout conversations. Leveraging UGST, we present a three-stage methodology for developing user simulators that can autonomously track goal progression and reason to generate goal-aligned responses. Moreover, we establish comprehensive evaluation metrics for measuring goal alignment in user simulators, and demonstrate that our approach yields substantial improvements across two benchmarks (MultiWOZ 2.4 and {\tau}-Bench). Our contributions address a critical gap in conversational AI and establish UGST as an essential framework for developing goal-aligned user simulators.
Must Read: A Systematic Survey of Computational Persuasion
May 12, 2025Persuasion is a fundamental aspect of communication, influencing decision-making across diverse contexts, from everyday conversations to high-stakes scenarios such as politics, marketing, and law. The rise of conversational AI systems has significantly expanded the scope of persuasion, introducing both opportunities and risks. AI-driven persuasion can be leveraged for beneficial applications, but also poses threats through manipulation and unethical influence. Moreover, AI systems are not only persuaders, but also susceptible to persuasion, making them vulnerable to adversarial attacks and bias reinforcement. Despite rapid advancements in AI-generated persuasive content, our understanding of what makes persuasion effective remains limited due to its inherently subjective and context-dependent nature. In this survey, we provide a comprehensive overview of computational persuasion, structured around three key perspectives: (1) AI as a Persuader, which explores AI-generated persuasive content and its applications; (2) AI as a Persuadee, which examines AI's susceptibility to influence and manipulation; and (3) AI as a Persuasion Judge, which analyzes AI's role in evaluating persuasive strategies, detecting manipulation, and ensuring ethical persuasion. We introduce a taxonomy for computational persuasion research and discuss key challenges, including evaluating persuasiveness, mitigating manipulative persuasion, and developing responsible AI-driven persuasive systems. Our survey outlines future research directions to enhance the safety, fairness, and effectiveness of AI-powered persuasion while addressing the risks posed by increasingly capable language models.
MultiAgentBench: Evaluating the Collaboration and Competition of LLM agents
Mar 03, 2025Large Language Models (LLMs) have shown remarkable capabilities as autonomous agents, yet existing benchmarks either focus on single-agent tasks or are confined to narrow domains, failing to capture the dynamics of multi-agent coordination and competition. In this paper, we introduce MultiAgentBench, a comprehensive benchmark designed to evaluate LLM-based multi-agent systems across diverse, interactive scenarios. Our framework measures not only task completion but also the quality of collaboration and competition using novel, milestone-based key performance indicators. Moreover, we evaluate various coordination protocols (including star, chain, tree, and graph topologies) and innovative strategies such as group discussion and cognitive planning. Notably, gpt-4o-mini reaches the average highest task score, graph structure performs the best among coordination protocols in the research scenario, and cognitive planning improves milestone achievement rates by 3%. Code and datasets are public available at https://github.com/MultiagentBench/MARBLE.
EscapeBench: Pushing Language Models to Think Outside the Box
Dec 18, 2024Language model agents excel in long-session planning and reasoning, but existing benchmarks primarily focus on goal-oriented tasks with explicit objectives, neglecting creative adaptation in unfamiliar environments. To address this, we introduce EscapeBench, a benchmark suite of room escape game environments designed to challenge agents with creative reasoning, unconventional tool use, and iterative problem-solving to uncover implicit goals. Our results show that current LM models, despite employing working memory and Chain-of-Thought reasoning, achieve only 15% average progress without hints, highlighting their limitations in creativity. To bridge this gap, we propose EscapeAgent, a framework designed to enhance creative reasoning through Foresight (innovative tool use) and Reflection (identifying unsolved tasks). Experiments show that EscapeAgent can execute action chains over 1,000 steps while maintaining logical coherence. It navigates and completes games with up to 40% fewer steps and hints, performs robustly across varying difficulty levels, and achieves higher action success rates with more efficient and innovative puzzle-solving strategies. All the data and codes are released.
ReSpAct: Harmonizing Reasoning, Speaking, and Acting Towards Building Large Language Model-Based Conversational AI Agents
Nov 01, 2024



Large language model (LLM)-based agents have been increasingly used to interact with external environments (e.g., games, APIs, etc.) and solve tasks. However, current frameworks do not enable these agents to work with users and interact with them to align on the details of their tasks and reach user-defined goals; instead, in ambiguous situations, these agents may make decisions based on assumptions. This work introduces ReSpAct (Reason, Speak, and Act), a novel framework that synergistically combines the essential skills for building task-oriented "conversational" agents. ReSpAct addresses this need for agents, expanding on the ReAct approach. The ReSpAct framework enables agents to interpret user instructions, reason about complex tasks, execute appropriate actions, and engage in dynamic dialogue to seek guidance, clarify ambiguities, understand user preferences, resolve problems, and use the intermediate feedback and responses of users to update their plans. We evaluated ReSpAct in environments supporting user interaction, such as task-oriented dialogue (MultiWOZ) and interactive decision-making (AlfWorld, WebShop). ReSpAct is flexible enough to incorporate dynamic user feedback and addresses prevalent issues like error propagation and agents getting stuck in reasoning loops. This results in more interpretable, human-like task-solving trajectories than relying solely on reasoning traces. In two interactive decision-making benchmarks, AlfWorld and WebShop, ReSpAct outperform the strong reasoning-only method ReAct by an absolute success rate of 6% and 4%, respectively. In the task-oriented dialogue benchmark MultiWOZ, ReSpAct improved Inform and Success scores by 5.5% and 3%, respectively.
Arithmetic Reasoning with LLM: Prolog Generation & Permutation
May 28, 2024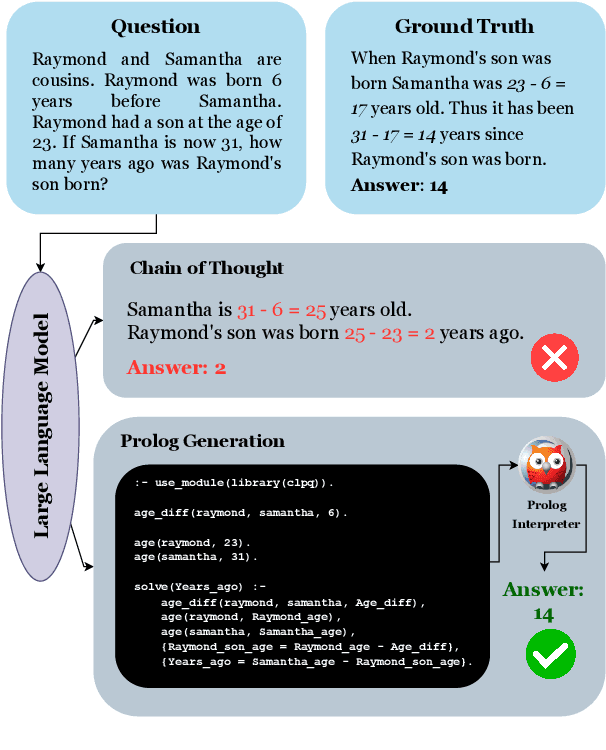
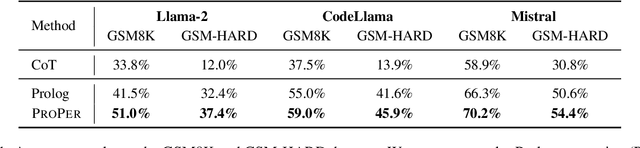
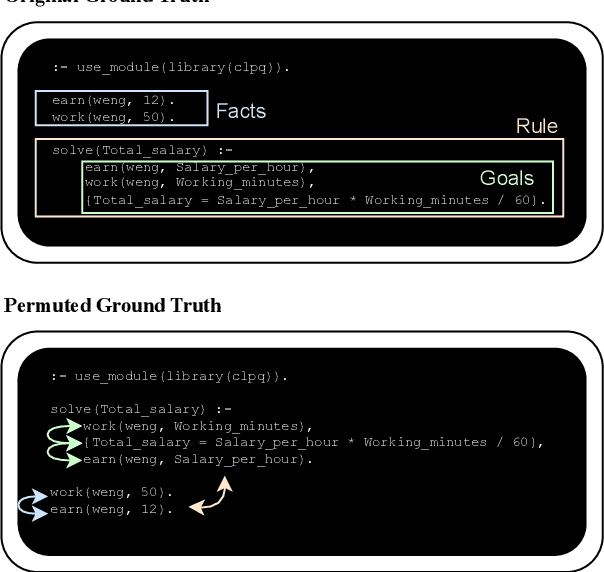
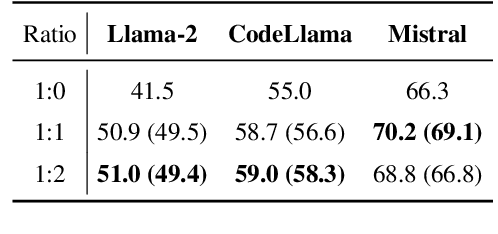
Instructing large language models (LLMs) to solve elementary school math problems has shown great success using Chain of Thought (CoT). However, the CoT approach relies on an LLM to generate a sequence of arithmetic calculations which can be prone to cascaded calculation errors. We hypothesize that an LLM should focus on extracting predicates and generating symbolic formulas from the math problem description so that the underlying calculation can be done via an external code interpreter. We investigate using LLM to generate Prolog programs to solve mathematical questions. Experimental results show that our Prolog-based arithmetic problem-solving outperforms CoT generation in the GSM8K benchmark across three distinct LLMs. In addition, given the insensitive ordering of predicates and symbolic formulas in Prolog, we propose to permute the ground truth predicates for more robust LLM training via data augmentation.
Exploring an LM to generate Prolog Predicates from Mathematics Questions
Sep 08, 2023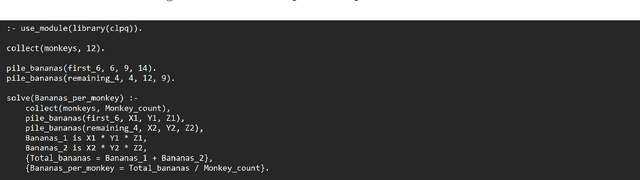
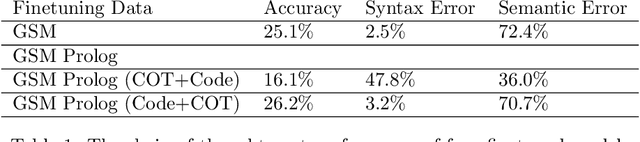
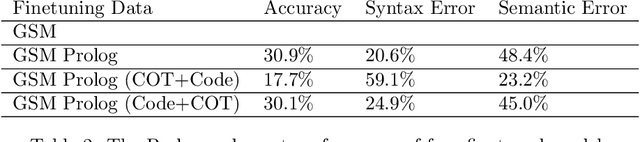
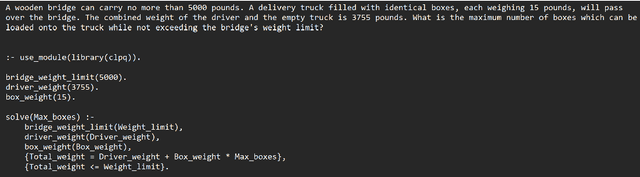
Recently, there has been a surge in interest in NLP driven by ChatGPT. ChatGPT, a transformer-based generative language model of substantial scale, exhibits versatility in performing various tasks based on natural language. Nevertheless, large language models often exhibit poor performance in solving mathematics questions that require reasoning. Prior research has demonstrated the effectiveness of chain-of-thought prompting in enhancing reasoning capabilities. Now, we aim to investigate whether fine-tuning a model for the generation of Prolog codes, a logic language, and subsequently passing these codes to a compiler can further improve accuracy. Consequently, we employ chain-of-thought to fine-tune LLaMA7B as a baseline model and develop other fine-tuned LLaMA7B models for the generation of Prolog code, Prolog code + chain-of-thought, and chain-of-thought + Prolog code, respectively. The results reveal that the Prolog generation model surpasses the baseline in performance, while the combination generation models do not yield significant improvements. The Prolog corpus based on GSM8K and the correspondingly finetuned Prolog generation model based on LLaMA7B are released to the research community.
Simple and Efficient Heterogeneous Graph Neural Network
Jul 06, 2022



Heterogeneous graph neural networks (HGNNs) deliver the powerful capability to embed rich structural and semantic information of a heterogeneous graph into low-dimensional node representations. Existing HGNNs usually learn to embed information using hierarchy attention mechanism and repeated neighbor aggregation, suffering from unnecessary complexity and redundant computation. This paper proposes Simple and Efficient Heterogeneous Graph Neural Network (SeHGNN) which reduces this excess complexity through avoiding overused node-level attention within the same relation and pre-computing the neighbor aggregation in the pre-processing stage. Unlike previous work, SeHGNN utilizes a light-weight parameter-free neighbor aggregator to learn structural information for each metapath, and a transformer-based semantic aggregator to combine semantic information across metapaths for the final embedding of each node. As a result, SeHGNN offers the simple network structure, high prediction accuracy, and fast training speed. Extensive experiments on five real-world heterogeneous graphs demonstrate the superiority of SeHGNN over the state-of-the-arts on both the accuracy and training speed. Codes are available at https://github.com/ICT-GIMLab/SeHGNN.