 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Single-shot Writing: Deep Research Agents are Unreliable at Multi-turn Report Revision
Jan 19, 2026Existing benchmarks for Deep Research Agents (DRAs) treat report generation as a single-shot writing task, which fundamentally diverges from how human researchers iteratively draft and revise reports via self-reflection or peer feedback. Whether DRAs can reliably revise reports with user feedback remains unexplored. We introduce Mr Dre, an evaluation suite that establishes multi-turn report revision as a new evaluation axis for DRAs. Mr Dre consists of (1) a unified long-form report evaluation protocol spanning comprehensiveness, factuality, and presentation, and (2) a human-verified feedback simulation pipeline for multi-turn revision. Our analysis of five diverse DRAs reveals a critical limitation: while agents can address most user feedback, they also regress on 16-27% of previously covered content and citation quality. Over multiple revision turns, even the best-performing agents leave significant headroom, as they continue to disrupt content outside the feedback's scope and fail to preserve earlier edits. We further show that these issues are not easily resolvable through inference-time fixes such as prompt engineering and a dedicated sub-agent for report revision.
Arithmetic Reasoning with LLM: Prolog Generation & Permutation
May 28, 2024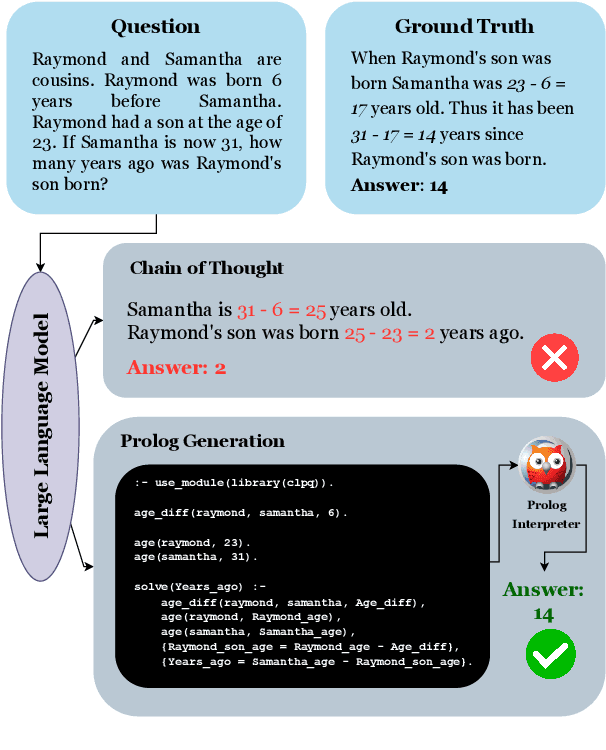
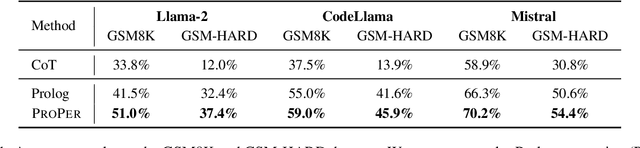
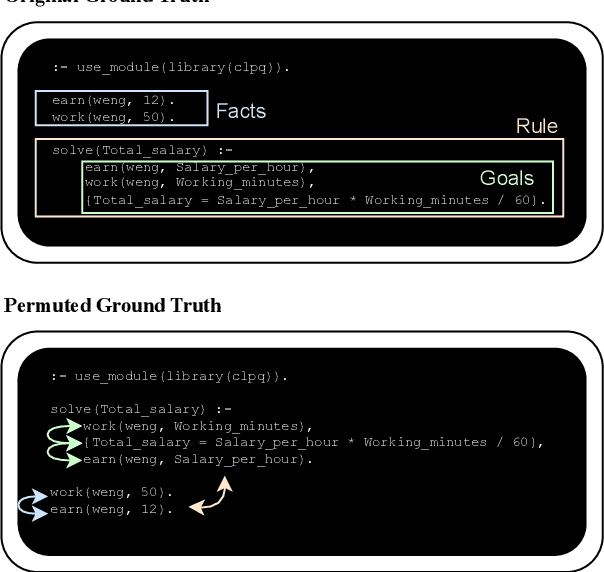
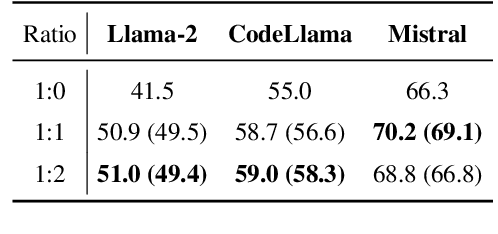
Instructing large language models (LLMs) to solve elementary school math problems has shown great success using Chain of Thought (CoT). However, the CoT approach relies on an LLM to generate a sequence of arithmetic calculations which can be prone to cascaded calculation errors. We hypothesize that an LLM should focus on extracting predicates and generating symbolic formulas from the math problem description so that the underlying calculation can be done via an external code interpreter. We investigate using LLM to generate Prolog programs to solve mathematical questions. Experimental results show that our Prolog-based arithmetic problem-solving outperforms CoT generation in the GSM8K benchmark across three distinct LLMs. In addition, given the insensitive ordering of predicates and symbolic formulas in Prolog, we propose to permute the ground truth predicates for more robust LLM training via data augmentation.