 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLA-Mark: A cross modal watermark for large vision-language alignment model
Jul 18, 2025



Vision-language models demand watermarking solutions that protect intellectual property without compromising multimodal coherence. Existing text watermarking methods disrupt visual-textual alignment through biased token selection and static strategies, leaving semantic-critical concepts vulnerable. We propose VLA-Mark, a vision-aligned framework that embeds detectable watermarks while preserving semantic fidelity through cross-modal coordination. Our approach integrates multiscale visual-textual alignment metrics, combining localized patch affinity, global semantic coherence, and contextual attention patterns, to guide watermark injection without model retraining. An entropy-sensitive mechanism dynamically balances watermark strength and semantic preservation, prioritizing visual grounding during low-uncertainty generation phases. Experiments show 7.4% lower PPL and 26.6% higher BLEU than conventional methods, with near-perfect detection (98.8% AUC). The framework demonstrates 96.1\% attack resilience against attacks such as paraphrasing and synonym substitution, while maintaining text-visual consistency, establishing new standards for quality-preserving multimodal watermarking
Enhancing Mathematical Reasoning in LLMs with Background Operators
Dec 05, 2024We propose utilizing background operators for mathematical reasoning in large language models (LLMs). To achieve this, we define a set of fundamental mathematical predicates as the basic building blocks. For each mathematical problem, we develop a Prolog solution that includes problem-specific predicates and intermediate predicates derived from these background operators, ensuring that each solution adheres to the defined operator set. We introduce the MATH-Prolog corpus, which is derived from the counting and probability categories of the MATH corpus. For efficient data augmentation, we apply K-fold cross-validated self-training. This method incrementally generates new Prolog solutions for each fold, incorporating those verified as correct into the training set throughout the model training process. Our experimental results demonstrate that 5-fold crossvalidated self-training effectively identifies new, accurate Prolog solutions, achieving an accuracy of 84.6% on the cross-validated set, and 84.8% on the test set during fine-tuning the Meta-Llama-3.1-8B-Instruct model. This approach successfully uncovers new solutions with fully computable inference steps for previously unseen problems. Additionally, incorporating the background mathematical predicates into the prompt enhances solution coverage.
Arithmetic Reasoning with LLM: Prolog Generation & Permutation
May 28, 2024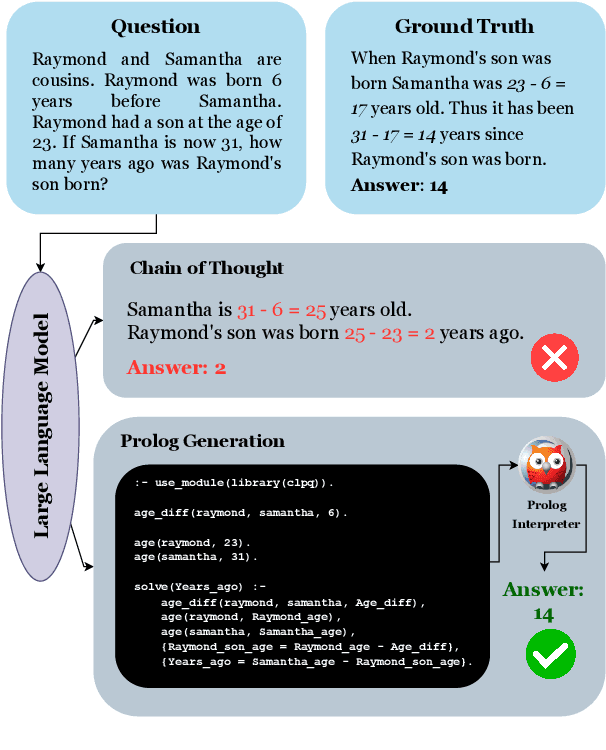
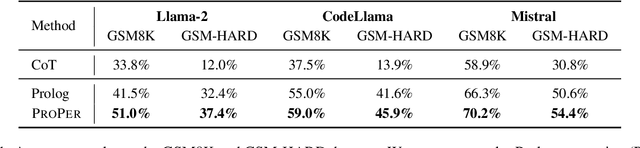
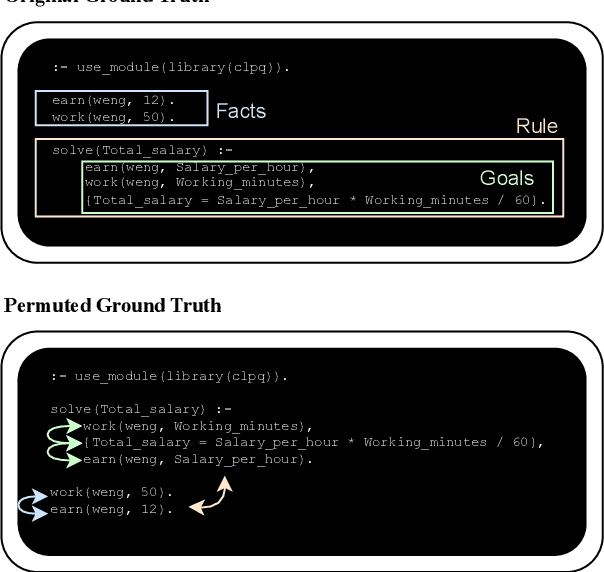
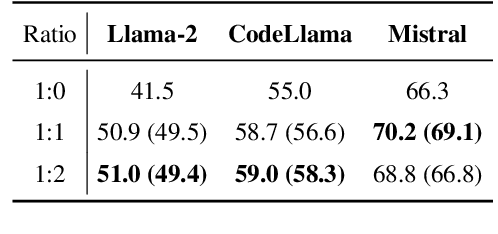
Instructing large language models (LLMs) to solve elementary school math problems has shown great success using Chain of Thought (CoT). However, the CoT approach relies on an LLM to generate a sequence of arithmetic calculations which can be prone to cascaded calculation errors. We hypothesize that an LLM should focus on extracting predicates and generating symbolic formulas from the math problem description so that the underlying calculation can be done via an external code interpreter. We investigate using LLM to generate Prolog programs to solve mathematical questions. Experimental results show that our Prolog-based arithmetic problem-solving outperforms CoT generation in the GSM8K benchmark across three distinct LLMs. In addition, given the insensitive ordering of predicates and symbolic formulas in Prolog, we propose to permute the ground truth predicates for more robust LLM training via data augmentation.
Exploring an LM to generate Prolog Predicates from Mathematics Questions
Sep 08, 2023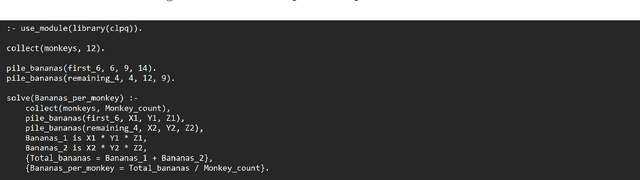
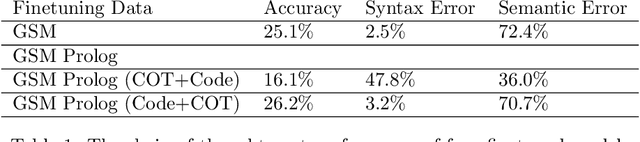
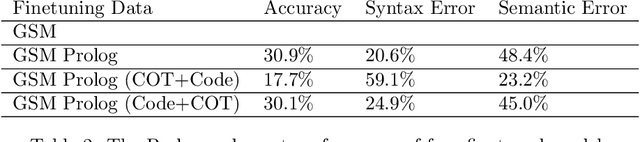
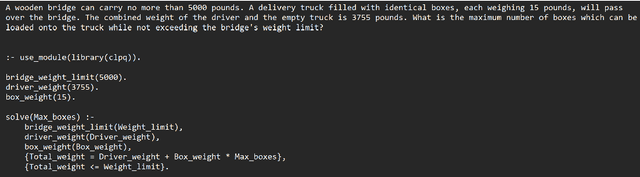
Recently, there has been a surge in interest in NLP driven by ChatGPT. ChatGPT, a transformer-based generative language model of substantial scale, exhibits versatility in performing various tasks based on natural language. Nevertheless, large language models often exhibit poor performance in solving mathematics questions that require reasoning. Prior research has demonstrated the effectiveness of chain-of-thought prompting in enhancing reasoning capabilities. Now, we aim to investigate whether fine-tuning a model for the generation of Prolog codes, a logic language, and subsequently passing these codes to a compiler can further improve accuracy. Consequently, we employ chain-of-thought to fine-tune LLaMA7B as a baseline model and develop other fine-tuned LLaMA7B models for the generation of Prolog code, Prolog code + chain-of-thought, and chain-of-thought + Prolog code, respectively. The results reveal that the Prolog generation model surpasses the baseline in performance, while the combination generation models do not yield significant improvements. The Prolog corpus based on GSM8K and the correspondingly finetuned Prolog generation model based on LLaMA7B are released to the research community.
Robust Unstructured Knowledge Access in Conversational Dialogue with ASR Errors
Nov 08, 2022



Performance of spoken language understanding (SLU) can be degraded with automatic speech recognition (ASR) errors. We propose a novel approach to improve SLU robustness by randomly corrupting clean training text with an ASR error simulator, followed by self-correcting the errors and minimizing the target classification loss in a joint manner. In the proposed error simulator, we leverage confusion networks generated from an ASR decoder without human transcriptions to generate a variety of error patterns for model training. We evaluate our approach on the DSTC10 challenge targeted for knowledge-grounded task-oriented conversational dialogues with ASR errors. Experimental results show the effectiveness of our proposed approach, boosting the knowledge-seeking turn detection (KTD) F1 significantly from 0.9433 to 0.9904. Knowledge cluster classification is boosted from 0.7924 to 0.9333 in Recall@1. After knowledge document re-ranking, our approach shows significant improvement in all knowledge selection metrics, from 0.7358 to 0.7806 in Recall@1, from 0.8301 to 0.9333 in Recall@5, and from 0.7798 to 0.8460 in MRR@5 on the test set. In the recent DSTC10 evaluation, our approach demonstrates significant improvement in knowledge selection, boosting Recall@1 from 0.495 to 0.7144 compared to the official baseline. Our source code is released in GitHub https://github.com/yctam/dstc10_track2_task2.git.
* 7 pages, 2 figures. Accepted at ICASSP 2022
Suffix Retrieval-Augmented Language Modeling
Nov 06, 2022Causal language modeling (LM) uses word history to predict the next word. BERT, on the other hand, makes use of bi-directional word information in a sentence to predict words at masked positions. While BERT is effective in sequence encoding, it is non-causal by nature and is not designed for sequence generation. In this paper, we propose a novel language model, SUffix REtrieval-Augmented LM (SUREALM), that simulates a bi-directional contextual effect in an autoregressive manner. SUREALM employs an embedding retriever to search for training sentences in a data store that share similar word history during sequence generation. In particular, the suffix portions of the retrieved sentences mimick the "future" context. We evaluated our proposed model on the DSTC9 spoken dialogue corpus and showed promising word perplexity reduction on the validation and test set compared to competitive baselines.
UNITER-Based Situated Coreference Resolution with Rich Multimodal Input
Dec 07, 2021
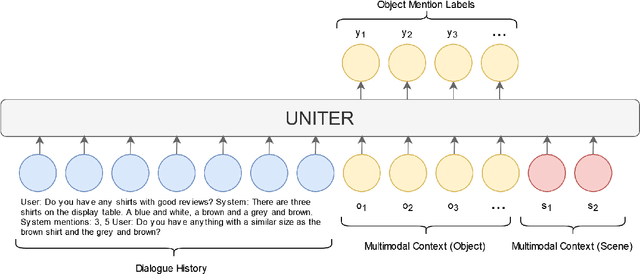
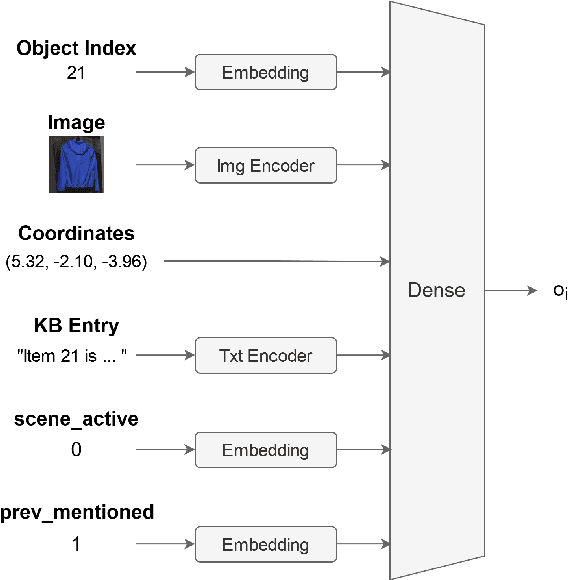
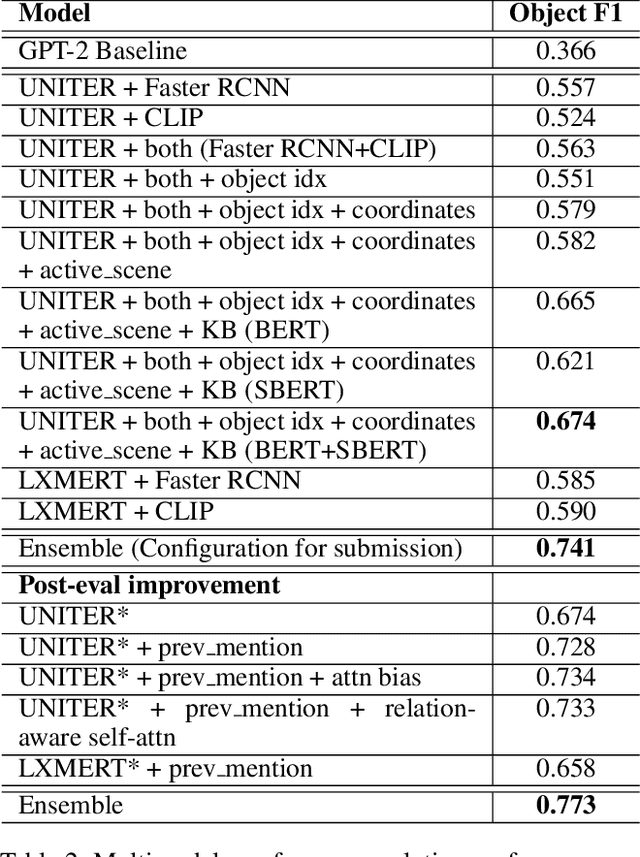
We present our work on the multimodal coreference resolution task of the Situated and Interactive Multimodal Conversation 2.0 (SIMMC 2.0) dataset as a part of the tenth Dialog System Technology Challenge (DSTC10). We propose a UNITER-based model utilizing rich multimodal context such as textual dialog history, object knowledge base and visual dialog scenes to determine whether each object in the current scene is mentioned in the current dialog turn. Results show that the proposed approach outperforms the official DSTC10 baseline substantially, with the object F1 score boosted from 36.6% to 77.3% on the development set, demonstrating the effectiveness of the proposed object representations from rich multimodal input. Our model ranks second in the official evaluation on the object coreference resolution task with an F1 score of 73.3% after model ensembling.
Ontology-Enhanced Slot Filling
Aug 25, 2021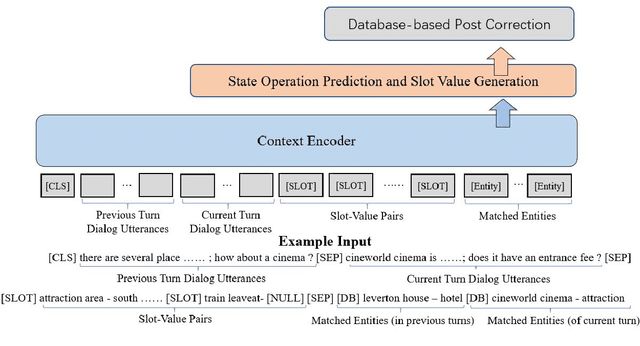


Slot filling is a fundamental task in dialog state tracking in task-oriented dialog systems. In multi-domain task-oriented dialog system, user utterances and system responses may mention multiple named entities and attributes values. A system needs to select those that are confirmed by the user and fill them into destined slots. One difficulty is that since a dialogue session contains multiple system-user turns, feeding in all the tokens into a deep model such as BERT can be challenging due to limited capacity of input word tokens and GPU memory. In this paper, we investigate an ontology-enhanced approach by matching the named entities occurred in all dialogue turns using ontology. The matched entities in the previous dialogue turns will be accumulated and encoded as additional inputs to a BERT-based dialogue state tracker. In addition, our improvement includes ontology constraint checking and the correction of slot name tokenization. Experimental results showed that our ontology-enhanced dialogue state tracker improves the joint goal accuracy (slot F1) from 52.63% (91.64%) to 53.91% (92%) on MultiWOZ 2.1 corpus.
Keyword-Attentive Deep Semantic Matching
Mar 11, 2020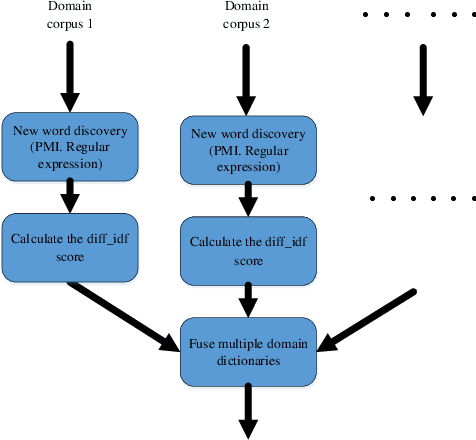
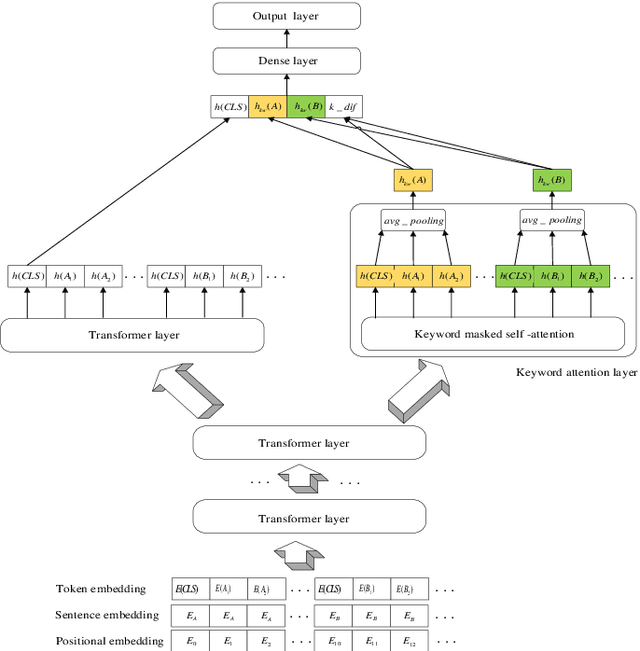


Deep Semantic Matching is a crucial component in various natural language processing applications such as question and answering (QA), where an input query is compared to each candidate question in a QA corpus in terms of relevance. Measuring similarities between a query-question pair in an open domain scenario can be challenging due to diverse word tokens in the queryquestion pair. We propose a keyword-attentive approach to improve deep semantic matching. We first leverage domain tags from a large corpus to generate a domain-enhanced keyword dictionary. Built upon BERT, we stack a keyword-attentive transformer layer to highlight the importance of keywords in the query-question pair. During model training, we propose a new negative sampling approach based on keyword coverage between the input pair. We evaluate our approach on a Chinese QA corpus using various metrics, including precision of retrieval candidates and accuracy of semantic matching. Experiments show that our approach outperforms existing strong baselines. Our approach is general and can be applied to other text matching tasks with little adaptation.