 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNITER-Based Situated Coreference Resolution with Rich Multimodal Input
Paper and Code

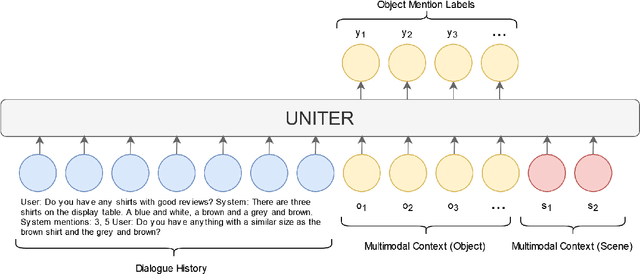
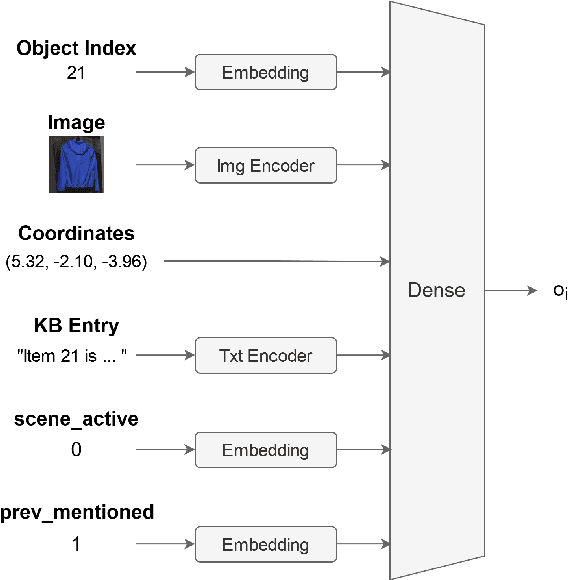
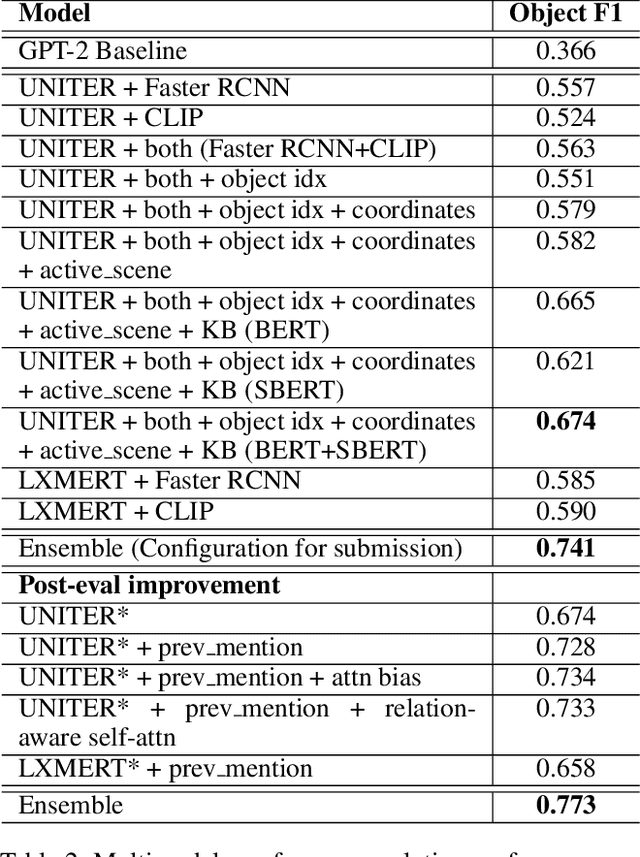
We present our work on the multimodal coreference resolution task of the Situated and Interactive Multimodal Conversation 2.0 (SIMMC 2.0) dataset as a part of the tenth Dialog System Technology Challenge (DSTC10). We propose a UNITER-based model utilizing rich multimodal context such as textual dialog history, object knowledge base and visual dialog scenes to determine whether each object in the current scene is mentioned in the current dialog turn. Results show that the proposed approach outperforms the official DSTC10 baseline substantially, with the object F1 score boosted from 36.6% to 77.3% on the development set, demonstrating the effectiveness of the proposed object representations from rich multimodal input. Our model ranks second in the official evaluation on the object coreference resolution task with an F1 score of 73.3% after model ensembling.