 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBadSAD: Clean-Label Backdoor Attacks against Deep Semi-Supervised Anomaly Detection
Dec 17, 2024Image anomaly detection (IAD) is essential in applications such as industrial inspection, medical imaging, and security. Despite the progress achieved with deep learning models like Deep Semi-Supervised Anomaly Detection (DeepSAD), these models remain susceptible to backdoor attacks, presenting significant security challenges. In this paper, we introduce BadSAD, a novel backdoor attack framework specifically designed to target DeepSAD models. Our approach involves two key phases: trigger injection, where subtle triggers are embedded into normal images, and latent space manipulation, which positions and clusters the poisoned images near normal images to make the triggers appear benign. Extensive experiments on benchmark datasets validate the effectiveness of our attack strategy, highlighting the severe risks that backdoor attacks pose to deep learning-based anomaly detection systems.
Backdoor Attack against One-Class Sequential Anomaly Detection Models
Feb 15, 2024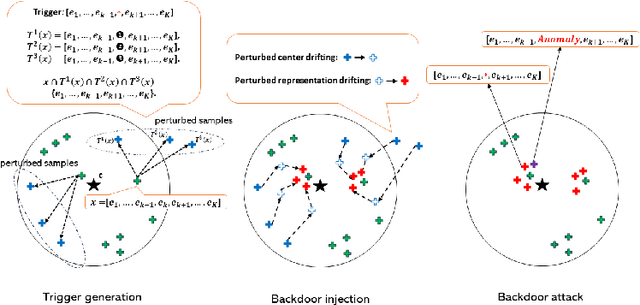
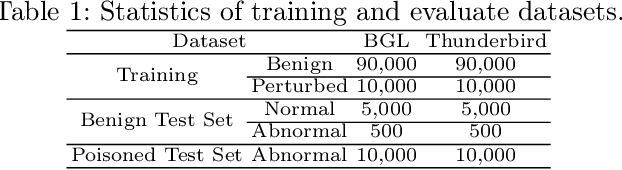
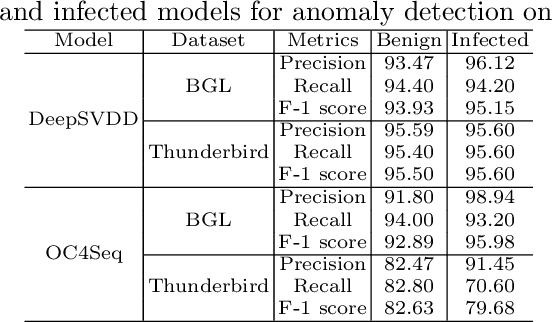
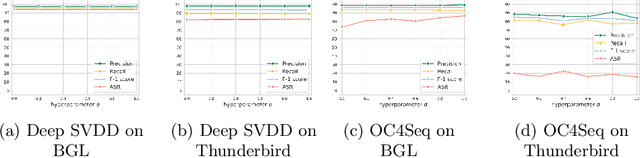
Deep anomaly detection on sequential data has garnered significant attention due to the wide application scenarios. However, deep learning-based models face a critical security threat - their vulnerability to backdoor attacks. In this paper, we explore compromising deep sequential anomaly detection models by proposing a novel backdoor attack strategy. The attack approach comprises two primary steps, trigger generation and backdoor injection. Trigger generation is to derive imperceptible triggers by crafting perturbed samples from the benign normal data, of which the perturbed samples are still normal. The backdoor injection is to properly inject the backdoor triggers to comprise the model only for the samples with triggers. The experimental results demonstrate the effectiveness of our proposed attack strategy by injecting backdoors on two well-established one-class anomaly detection models.
Algorithmic Recourse for Anomaly Detection in Multivariate Time Series
Sep 28, 2023


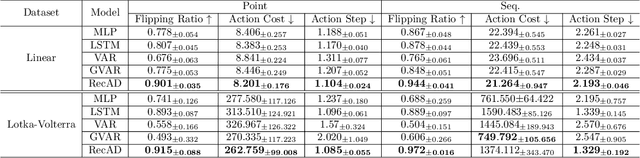
Anomaly detection in multivariate time series has received extensive study due to the wide spectrum of applications. An anomaly in multivariate time series usually indicates a critical event, such as a system fault or an external attack. Therefore, besides being effective in anomaly detection, recommending anomaly mitigation actions is also important in practice yet under-investigated. In this work, we focus on algorithmic recourse in time series anomaly detection, which is to recommend fixing actions on abnormal time series with a minimum cost so that domain experts can understand how to fix the abnormal behavior. To this end, we propose an algorithmic recourse framework, called RecAD, which can recommend recourse actions to flip the abnormal time steps. Experiments on two synthetic and one real-world datasets show the effectiveness of our framework.
LogGPT: Log Anomaly Detection via GPT
Sep 25, 2023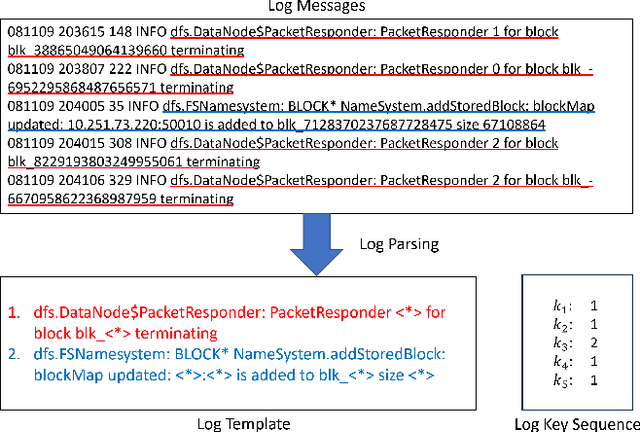
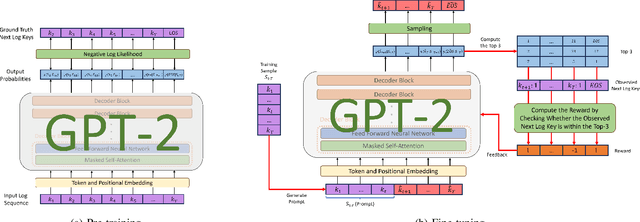
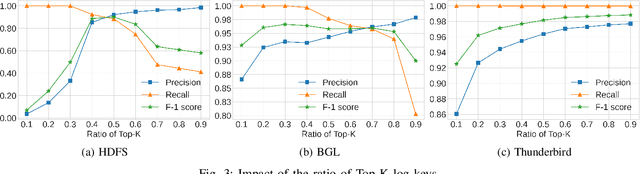
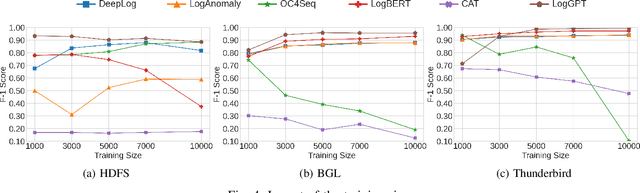
Detecting system anomalies based on log data is important for ensuring the security and reliability of computer systems. Recently, deep learning models have been widely used for log anomaly detection. The core idea is to model the log sequences as natural language and adopt deep sequential models, such as LSTM or Transformer, to encode the normal patterns in log sequences via language modeling. However, there is a gap between language modeling and anomaly detection as the objective of training a sequential model via a language modeling loss is not directly related to anomaly detection. To fill up the gap, we propose LogGPT, a novel framework that employs GPT for log anomaly detection. LogGPT is first trained to predict the next log entry based on the preceding sequence. To further enhance the performance of LogGPT, we propose a novel reinforcement learning strategy to finetune the model specifically for the log anomaly detection task. The experimental results on three datasets show that LogGPT significantly outperforms existing state-of-the-art approaches.
Robust Fraud Detection via Supervised Contrastive Learning
Aug 19, 2023Deep learning models have recently become popular for detecting malicious user activity sessions in computing platforms. In many real-world scenarios, only a few labeled malicious and a large amount of normal sessions are available. These few labeled malicious sessions usually do not cover the entire diversity of all possible malicious sessions. In many scenarios, possible malicious sessions can be highly diverse. As a consequence, learned session representations of deep learning models can become ineffective in achieving a good generalization performance for unseen malicious sessions. To tackle this open-set fraud detection challenge, we propose a robust supervised contrastive learning based framework called ConRo, which specifically operates in the scenario where only a few malicious sessions having limited diversity is available. ConRo applies an effective data augmentation strategy to generate diverse potential malicious sessions. By employing these generated and available training set sessions, ConRo derives separable representations w.r.t open-set fraud detection task by leveraging supervised contrastive learning. We empirically evaluate our ConRo framework and other state-of-the-art baselines on benchmark datasets. Our ConRo framework demonstrates noticeable performance improvement over state-of-the-art baselines.
Achieving Counterfactual Fairness for Anomaly Detection
Mar 04, 2023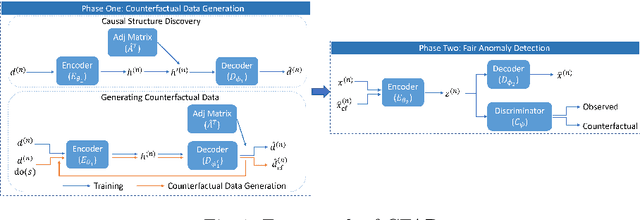
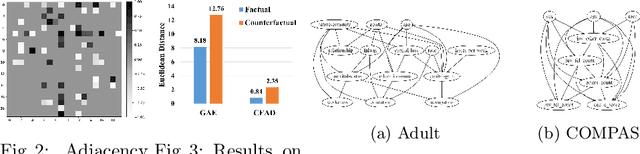
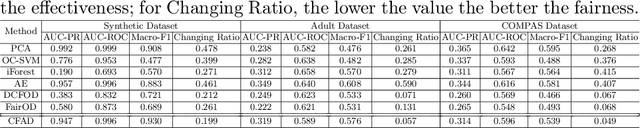
Ensuring fairness in anomaly detection models has received much attention recently as many anomaly detection applications involve human beings. However, existing fair anomaly detection approaches mainly focus on association-based fairness notions. In this work, we target counterfactual fairness, which is a prevalent causation-based fairness notion. The goal of counterfactually fair anomaly detection is to ensure that the detection outcome of an individual in the factual world is the same as that in the counterfactual world where the individual had belonged to a different group. To this end, we propose a counterfactually fair anomaly detection (CFAD) framework which consists of two phases, counterfactual data generation and fair anomaly detection. Experimental results on a synthetic dataset and two real datasets show that CFAD can effectively detect anomalies as well as ensure counterfactual fairness.
On Interpretable Anomaly Detection Using Causal Algorithmic Recourse
Dec 08, 2022



As many deep anomaly detection models have been deployed in the real-world, interpretable anomaly detection becomes an emerging task. Recent studies focus on identifying features of samples leading to abnormal outcomes but cannot recommend a set of actions to flip the abnormal outcomes. In this work, we focus on interpretations via algorithmic recourse that shows how to act to revert abnormal predictions by suggesting actions on features. The key challenge is that algorithmic recourse involves interventions in the physical world, which is fundamentally a causal problem. To tackle this challenge, we propose an interpretable Anomaly Detection framework using Causal Algorithmic Recourse (ADCAR), which recommends recourse actions and infers counterfactual of abnormal samples guided by the causal mechanism. Experiments on three datasets show that ADCAR can flip the abnormal labels with minimal interventions.
Generating Textual Adversaries with Minimal Perturbation
Nov 12, 2022
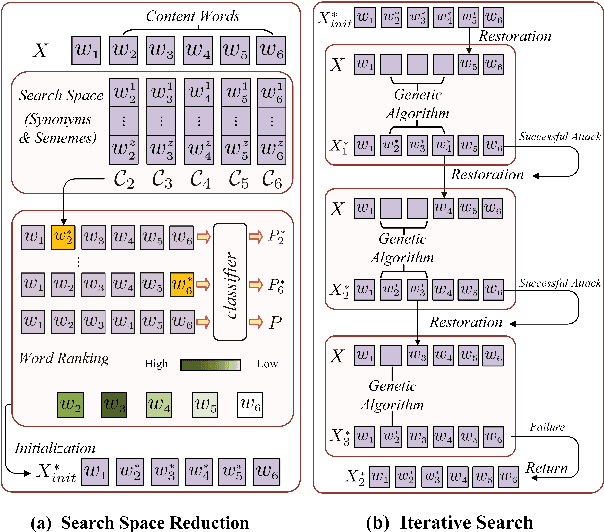
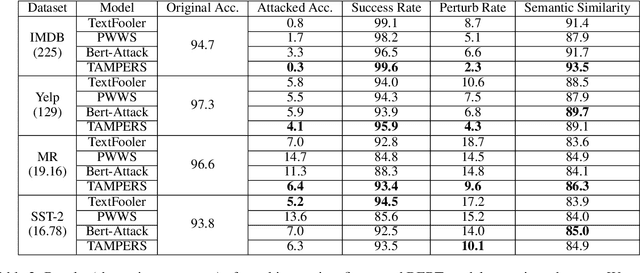

Many word-level adversarial attack approaches for textual data have been proposed in recent studies. However, due to the massive search space consisting of combinations of candidate words, the existing approaches face the problem of preserving the semantics of texts when crafting adversarial counterparts. In this paper, we develop a novel attack strategy to find adversarial texts with high similarity to the original texts while introducing minimal perturbation. The rationale is that we expect the adversarial texts with small perturbation can better preserve the semantic meaning of original texts. Experiments show that, compared with state-of-the-art attack approaches, our approach achieves higher success rates and lower perturbation rates in four benchmark datasets.
Robust Unstructured Knowledge Access in Conversational Dialogue with ASR Errors
Nov 08, 2022



Performance of spoken language understanding (SLU) can be degraded with automatic speech recognition (ASR) errors. We propose a novel approach to improve SLU robustness by randomly corrupting clean training text with an ASR error simulator, followed by self-correcting the errors and minimizing the target classification loss in a joint manner. In the proposed error simulator, we leverage confusion networks generated from an ASR decoder without human transcriptions to generate a variety of error patterns for model training. We evaluate our approach on the DSTC10 challenge targeted for knowledge-grounded task-oriented conversational dialogues with ASR errors. Experimental results show the effectiveness of our proposed approach, boosting the knowledge-seeking turn detection (KTD) F1 significantly from 0.9433 to 0.9904. Knowledge cluster classification is boosted from 0.7924 to 0.9333 in Recall@1. After knowledge document re-ranking, our approach shows significant improvement in all knowledge selection metrics, from 0.7358 to 0.7806 in Recall@1, from 0.8301 to 0.9333 in Recall@5, and from 0.7798 to 0.8460 in MRR@5 on the test set. In the recent DSTC10 evaluation, our approach demonstrates significant improvement in knowledge selection, boosting Recall@1 from 0.495 to 0.7144 compared to the official baseline. Our source code is released in GitHub https://github.com/yctam/dstc10_track2_task2.git.
* 7 pages, 2 figures. Accepted at ICASSP 2022
Fine-grained Anomaly Detection in Sequential Data via Counterfactual Explanations
Oct 09, 2022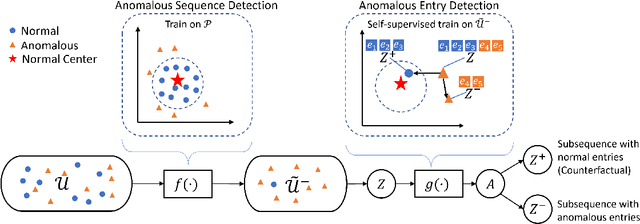
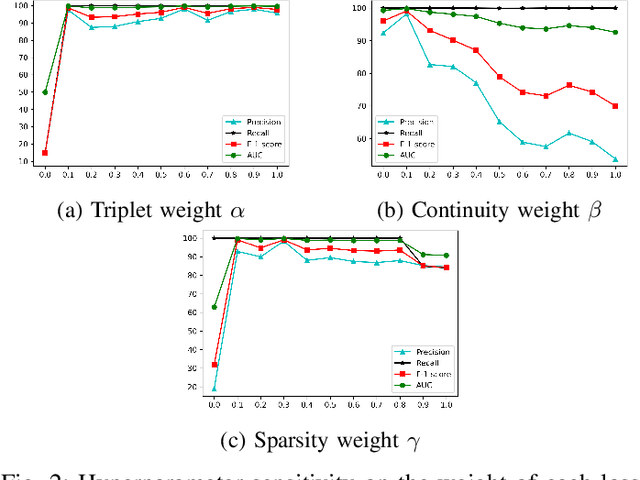
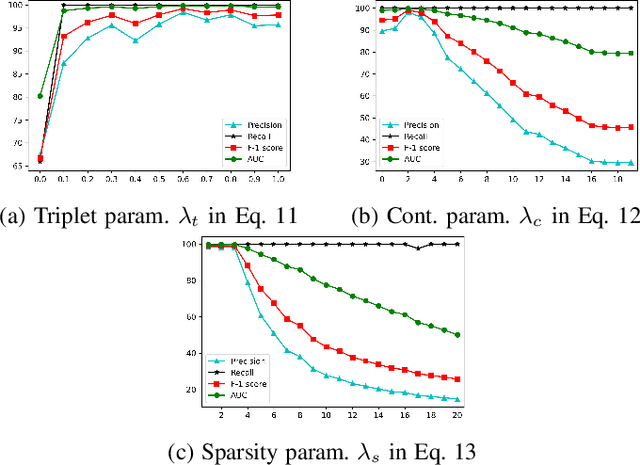
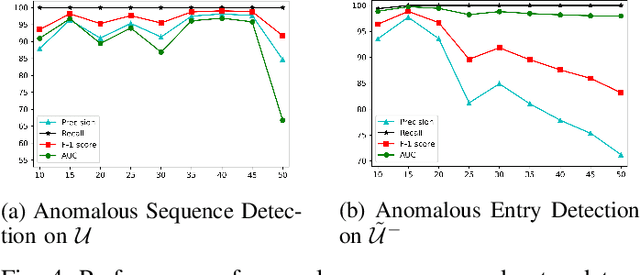
Anomaly detection in sequential data has been studied for a long time because of its potential in various applications, such as detecting abnormal system behaviors from log data. Although many approaches can achieve good performance on anomalous sequence detection, how to identify the anomalous entries in sequences is still challenging due to a lack of information at the entry-level. In this work, we propose a novel framework called CFDet for fine-grained anomalous entry detection. CFDet leverages the idea of interpretable machine learning. Given a sequence that is detected as anomalous, we can consider anomalous entry detection as an interpretable machine learning task because identifying anomalous entries in the sequence is to provide an interpretation to the detection result. We make use of the deep support vector data description (Deep SVDD) approach to detect anomalous sequences and propose a novel counterfactual interpretation-based approach to identify anomalous entries in the sequences. Experimental results on three datasets show that CFDet can correctly detect anomalous entries.