 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative Analysis of Formula and Structure Prediction from Tandem Mass Spectra
Jan 02, 2026Liquid chromatography mass spectrometry (LC-MS)-based metabolomics and exposomics aim to measure detectable small molecules in biological samples. The results facilitate hypothesis-generating discovery of metabolic changes and disease mechanisms and provide information about environmental exposures and their effects on human health. Metabolomics and exposomics are made possible by the high resolving power of LC and high mass measurement accuracy of MS. However, a majority of the signals from such studies still cannot be identified or annotated using conventional library searching because existing spectral libraries are far from covering the vast chemical space captured by LC-MS/MS. To address this challenge and unleash the full potential of metabolomics and exposomics, a number of computational approaches have been developed to predict compounds based on tandem mass spectra. Published assessment of these approaches used different datasets and evaluation. To select prediction workflows for practical applications and identify areas for further improvements, we have carried out a systematic evaluation of the state-of-the-art prediction algorithms. Specifically, the accuracy of formula prediction and structure prediction was evaluated for different types of adducts. The resulting findings have established realistic performance baselines, identified critical bottlenecks, and provided guidance to further improve compound predictions based on MS.
BadSAD: Clean-Label Backdoor Attacks against Deep Semi-Supervised Anomaly Detection
Dec 17, 2024Image anomaly detection (IAD) is essential in applications such as industrial inspection, medical imaging, and security. Despite the progress achieved with deep learning models like Deep Semi-Supervised Anomaly Detection (DeepSAD), these models remain susceptible to backdoor attacks, presenting significant security challenges. In this paper, we introduce BadSAD, a novel backdoor attack framework specifically designed to target DeepSAD models. Our approach involves two key phases: trigger injection, where subtle triggers are embedded into normal images, and latent space manipulation, which positions and clusters the poisoned images near normal images to make the triggers appear benign. Extensive experiments on benchmark datasets validate the effectiveness of our attack strategy, highlighting the severe risks that backdoor attacks pose to deep learning-based anomaly detection systems.
Adversary-Guided Motion Retargeting for Skeleton Anonymization
May 08, 2024Skeleton-based motion visualization is a rising field in computer vision, especially in the case of virtual reality (VR). With further advancements in human-pose estimation and skeleton extracting sensors, more and more applications that utilize skeleton data have come about. These skeletons may appear to be anonymous but they contain embedded personally identifiable information (PII). In this paper we present a new anonymization technique that is based on motion retargeting, utilizing adversary classifiers to further remove PII embedded in the skeleton. Motion retargeting is effective in anonymization as it transfers the movement of the user onto the a dummy skeleton. In doing so, any PII linked to the skeleton will be based on the dummy skeleton instead of the user we are protecting. We propose a Privacy-centric Deep Motion Retargeting model (PMR) which aims to further clear the retargeted skeleton of PII through adversarial learning. In our experiments, PMR achieves motion retargeting utility performance on par with state of the art models while also reducing the performance of privacy attacks.
Generating Textual Adversaries with Minimal Perturbation
Nov 12, 2022
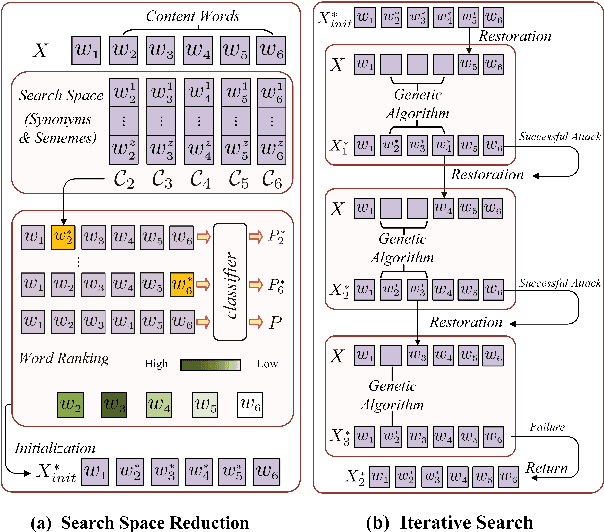
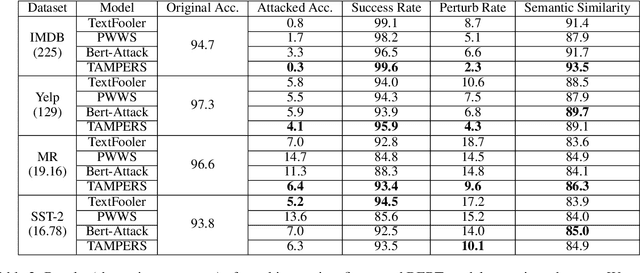

Many word-level adversarial attack approaches for textual data have been proposed in recent studies. However, due to the massive search space consisting of combinations of candidate words, the existing approaches face the problem of preserving the semantics of texts when crafting adversarial counterparts. In this paper, we develop a novel attack strategy to find adversarial texts with high similarity to the original texts while introducing minimal perturbation. The rationale is that we expect the adversarial texts with small perturbation can better preserve the semantic meaning of original texts. Experiments show that, compared with state-of-the-art attack approaches, our approach achieves higher success rates and lower perturbation rates in four benchmark datasets.
Fine-grained Anomaly Detection in Sequential Data via Counterfactual Explanations
Oct 09, 2022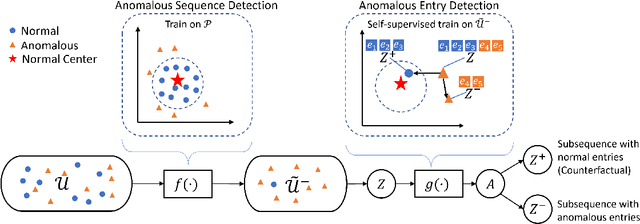
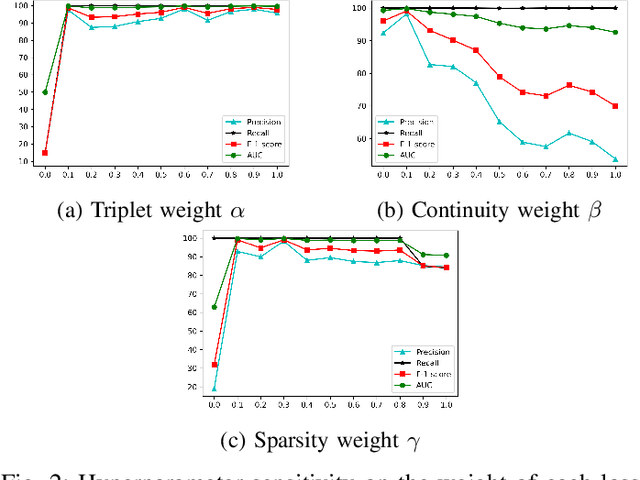
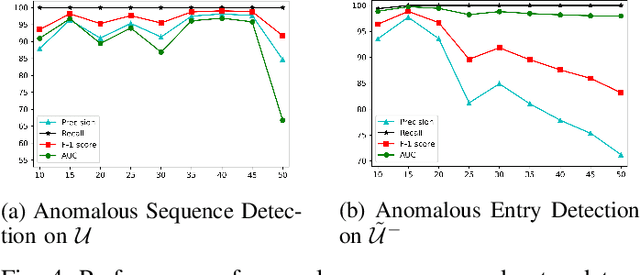
Anomaly detection in sequential data has been studied for a long time because of its potential in various applications, such as detecting abnormal system behaviors from log data. Although many approaches can achieve good performance on anomalous sequence detection, how to identify the anomalous entries in sequences is still challenging due to a lack of information at the entry-level. In this work, we propose a novel framework called CFDet for fine-grained anomalous entry detection. CFDet leverages the idea of interpretable machine learning. Given a sequence that is detected as anomalous, we can consider anomalous entry detection as an interpretable machine learning task because identifying anomalous entries in the sequence is to provide an interpretation to the detection result. We make use of the deep support vector data description (Deep SVDD) approach to detect anomalous sequences and propose a novel counterfactual interpretation-based approach to identify anomalous entries in the sequences. Experimental results on three datasets show that CFDet can correctly detect anomalous entries.
Fairness-aware Agnostic Federated Learning
Oct 10, 2020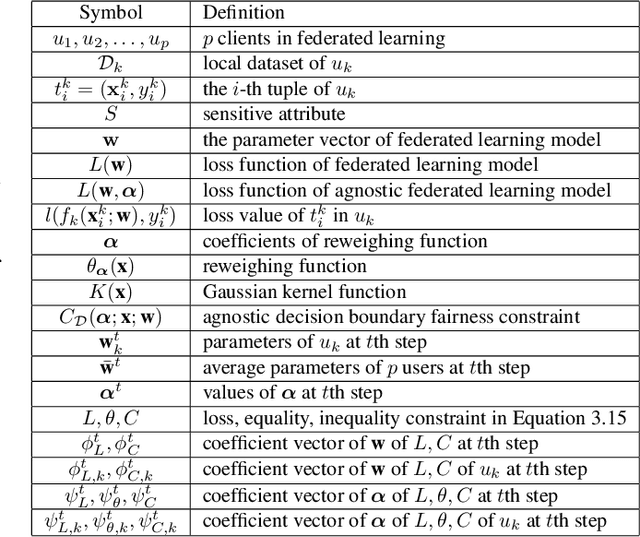

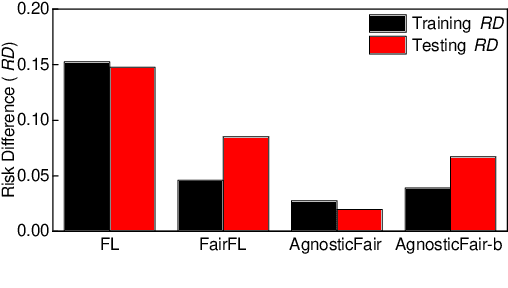
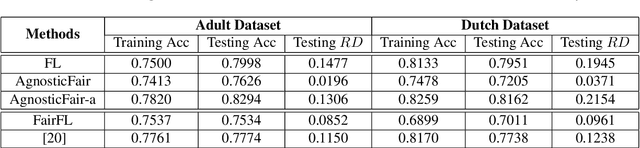
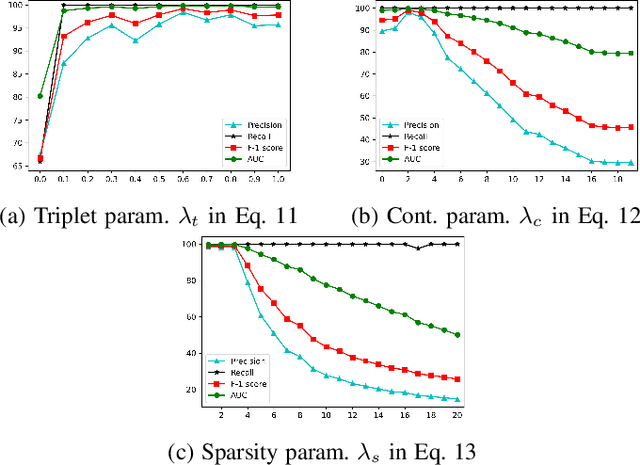
Federated learning is an emerging framework that builds centralized machine learning models with training data distributed across multiple devices. Most of the previous works about federated learning focus on the privacy protection and communication cost reduction. However, how to achieve fairness in federated learning is under-explored and challenging especially when testing data distribution is different from training distribution or even unknown. Introducing simple fairness constraints on the centralized model cannot achieve model fairness on unknown testing data. In this paper, we develop a fairness-aware agnostic federated learning framework (AgnosticFair) to deal with the challenge of unknown testing distribution. We use kernel reweighing functions to assign a reweighing value on each training sample in both loss function and fairness constraint. Therefore, the centralized model built from AgnosticFair can achieve high accuracy and fairness guarantee on unknown testing data. Moreover, the built model can be directly applied to local sites as it guarantees fairness on local data distributions. To our best knowledge, this is the first work to achieve fairness in federated learning. Experimental results on two real datasets demonstrate the effectiveness in terms of both utility and fairness under data shift scenarios.
Removing Disparate Impact of Differentially Private Stochastic Gradient Descent on Model Accuracy
Mar 08, 2020
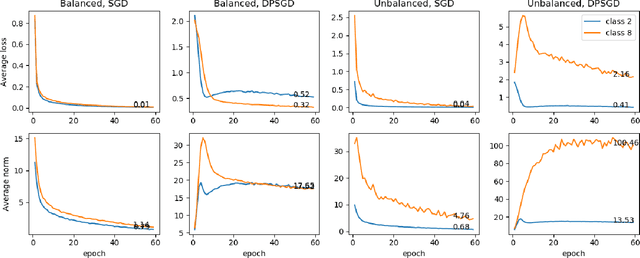
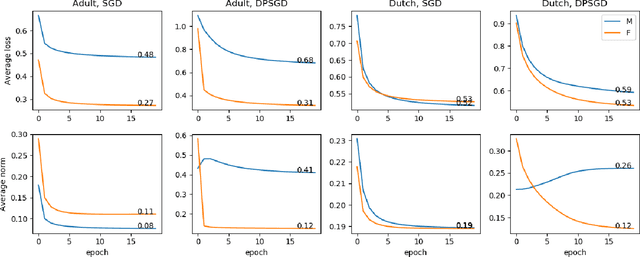
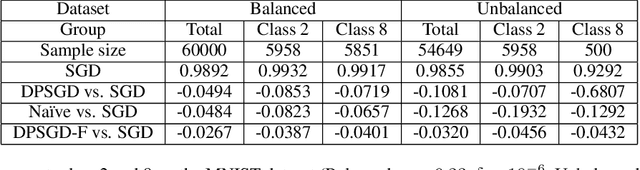
When we enforce differential privacy in machine learning, the utility-privacy trade-off is different w.r.t. each group. Gradient clipping and random noise addition disproportionately affect underrepresented and complex classes and subgroups, which results in inequality in utility loss. In this work, we analyze the inequality in utility loss by differential privacy and propose a modified differentially private stochastic gradient descent (DPSGD), called DPSGD-F, to remove the potential disparate impact of differential privacy on the protected group. DPSGD-F adjusts the contribution of samples in a group depending on the group clipping bias such that differential privacy has no disparate impact on group utility. Our experimental evaluation shows how group sample size and group clipping bias affect the impact of differential privacy in DPSGD, and how adaptive clipping for each group helps to mitigate the disparate impact caused by differential privacy in DPSGD-F.
Achieving Differential Privacy in Vertically Partitioned Multiparty Learning
Nov 11, 2019



Preserving differential privacy has been well studied under centralized setting. However, it's very challenging to preserve differential privacy under multiparty setting, especially for the vertically partitioned case. In this work, we propose a new framework for differential privacy preserving multiparty learning in the vertically partitioned setting. Our core idea is based on the functional mechanism that achieves differential privacy of the released model by adding noise to the objective function. We show the server can simply dissect the objective function into single-party and cross-party sub-functions, and allocate computation and perturbation of their polynomial coefficients to local parties. Our method needs only one round of noise addition and secure aggregation. The released model in our framework achieves the same utility as applying the functional mechanism in the centralized setting. Evaluation on real-world and synthetic datasets for linear and logistic regressions shows the effectiveness of our proposed method.
FairGAN: Fairness-aware Generative Adversarial Networks
May 28, 2018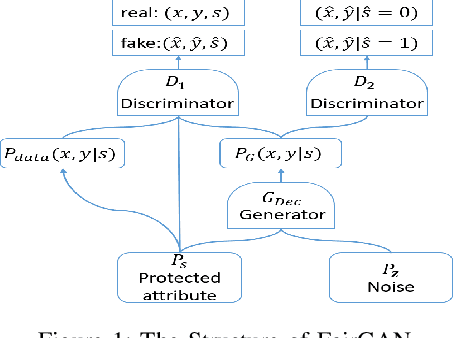


Fairness-aware learning is increasingly important in data mining. Discrimination prevention aims to prevent discrimination in the training data before it is used to conduct predictive analysis. In this paper, we focus on fair data generation that ensures the generated data is discrimination free. Inspired by generative adversarial networks (GAN), we present fairness-aware generative adversarial networks, called FairGAN, which are able to learn a generator producing fair data and also preserving good data utility. Compared with the naive fair data generation models, FairGAN further ensures the classifiers which are trained on generated data can achieve fair classification on real data. Experiments on a real dataset show the effectiveness of FairGAN.