 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversary-Guided Motion Retargeting for Skeleton Anonymization
May 08, 2024Skeleton-based motion visualization is a rising field in computer vision, especially in the case of virtual reality (VR). With further advancements in human-pose estimation and skeleton extracting sensors, more and more applications that utilize skeleton data have come about. These skeletons may appear to be anonymous but they contain embedded personally identifiable information (PII). In this paper we present a new anonymization technique that is based on motion retargeting, utilizing adversary classifiers to further remove PII embedded in the skeleton. Motion retargeting is effective in anonymization as it transfers the movement of the user onto the a dummy skeleton. In doing so, any PII linked to the skeleton will be based on the dummy skeleton instead of the user we are protecting. We propose a Privacy-centric Deep Motion Retargeting model (PMR) which aims to further clear the retargeted skeleton of PII through adversarial learning. In our experiments, PMR achieves motion retargeting utility performance on par with state of the art models while also reducing the performance of privacy attacks.
Domain Adaptation for Reinforcement Learning on the Atari
Dec 18, 2018
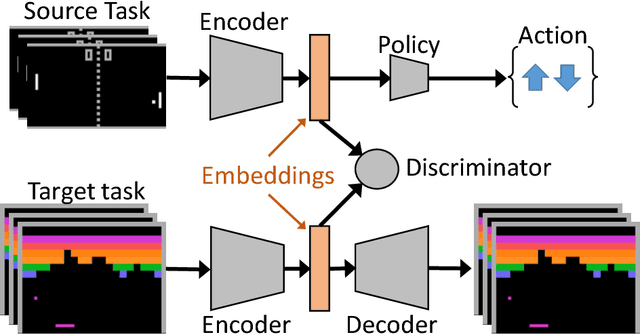


Deep reinforcement learning agents have recently been successful across a variety of discrete and continuous control tasks; however, they can be slow to train and require a large number of interactions with the environment to learn a suitable policy. This is borne out by the fact that a reinforcement learning agent has no prior knowledge of the world, no pre-existing data to depend on and so must devote considerable time to exploration. Transfer learning can alleviate some of the problems by leveraging learning done on some source task to help learning on some target task. Our work presents an algorithm for initialising the hidden feature representation of the target task. We propose a domain adaptation method to transfer state representations and demonstrate transfer across domains, tasks and action spaces. We utilise adversarial domain adaptation ideas combined with an adversarial autoencoder architecture. We align our new policies' representation space with a pre-trained source policy, taking target task data generated from a random policy. We demonstrate that this initialisation step provides significant improvement when learning a new reinforcement learning task, which highlights the wide applicability of adversarial adaptation methods; even as the task and label/action space also changes.