 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKHMP: Frequency-Domain Kalman Refinement for High-Fidelity Human Motion Prediction
Mar 22, 2026Stochastic human motion prediction aims to generate diverse, plausible futures from observed sequences. Despite advances in generative modeling, existing methods often produce predictions corrupted by high-frequency jitter and temporal discontinuities. To address these challenges, we introduce KHMP, a novel framework featuring an adaptiveKalman filter applied in the DCT domain to generate high-fidelity human motion predictions. By treating high-frequency DCT coefficients as a frequency-indexed noisy signal, the Kalman filter recursively suppresses noise while preserving motion details. Notably, its noise parameters are dynamically adjusted based on estimated Signal-to-Noise Ratio (SNR), enabling aggressive denoising for jittery predictions and conservative filtering for clean motions. This refinement is complemented by training-time physical constraints (temporal smoothness and joint angle limits) that encode biomechanical principles into the generative model. Together, these innovations establish a new paradigm integrating adaptive signal processing with physics-informed learning. Experiments on the Human3.6M and HumanEva-I datasets demonstrate that KHMP achieves state-of-the-art accuracy, effectively mitigating jitter artifacts to produce smooth and physically plausible motions.
UniSTFormer: Unified Spatio-Temporal Lightweight Transformer for Efficient Skeleton-Based Action Recognition
Aug 12, 2025



Skeleton-based action recognition (SAR) has achieved impressive progress with transformer architectures. However, existing methods often rely on complex module compositions and heavy designs, leading to increased parameter counts, high computational costs, and limited scalability. In this paper, we propose a unified spatio-temporal lightweight transformer framework that integrates spatial and temporal modeling within a single attention module, eliminating the need for separate temporal modeling blocks. This approach reduces redundant computations while preserving temporal awareness within the spatial modeling process. Furthermore, we introduce a simplified multi-scale pooling fusion module that combines local and global pooling pathways to enhance the model's ability to capture fine-grained local movements and overarching global motion patterns. Extensive experiments on benchmark datasets demonstrate that our lightweight model achieves a superior balance between accuracy and efficiency, reducing parameter complexity by over 58% and lowering computational cost by over 60% compared to state-of-the-art transformer-based baselines, while maintaining competitive recognition performance.
FreqMixFormerV2: Lightweight Frequency-aware Mixed Transformer for Human Skeleton Action Recognition
Dec 29, 2024Transformer-based human skeleton action recognition has been developed for years. However, the complexity and high parameter count demands of these models hinder their practical applications, especially in resource-constrained environments. In this work, we propose FreqMixForemrV2, which was built upon the Frequency-aware Mixed Transformer (FreqMixFormer) for identifying subtle and discriminative actions with pioneered frequency-domain analysis. We design a lightweight architecture that maintains robust performance while significantly reducing the model complexity. This is achieved through a redesigned frequency operator that optimizes high-frequency and low-frequency parameter adjustments, and a simplified frequency-aware attention module. These improvements result in a substantial reduction in model parameters, enabling efficient deployment with only a minimal sacrifice in accuracy. Comprehensive evaluations of standard datasets (NTU RGB+D, NTU RGB+D 120, and NW-UCLA datasets) demonstrate that the proposed model achieves a superior balance between efficiency and accuracy, outperforming state-of-the-art methods with only 60% of the parameters.
Frequency Guidance Matters: Skeletal Action Recognition by Frequency-Aware Mixed Transformer
Jul 17, 2024Recently, transformers have demonstrated great potential for modeling long-term dependencies from skeleton sequences and thereby gained ever-increasing attention in skeleton action recognition. However, the existing transformer-based approaches heavily rely on the naive attention mechanism for capturing the spatiotemporal features, which falls short in learning discriminative representations that exhibit similar motion patterns. To address this challenge, we introduce the Frequency-aware Mixed Transformer (FreqMixFormer), specifically designed for recognizing similar skeletal actions with subtle discriminative motions. First, we introduce a frequency-aware attention module to unweave skeleton frequency representations by embedding joint features into frequency attention maps, aiming to distinguish the discriminative movements based on their frequency coefficients. Subsequently, we develop a mixed transformer architecture to incorporate spatial features with frequency features to model the comprehensive frequency-spatial patterns. Additionally, a temporal transformer is proposed to extract the global correlations across frames. Extensive experiments show that FreqMiXFormer outperforms SOTA on 3 popular skeleton action recognition datasets, including NTU RGB+D, NTU RGB+D 120, and NW-UCLA datasets.
Adversary-Guided Motion Retargeting for Skeleton Anonymization
May 08, 2024Skeleton-based motion visualization is a rising field in computer vision, especially in the case of virtual reality (VR). With further advancements in human-pose estimation and skeleton extracting sensors, more and more applications that utilize skeleton data have come about. These skeletons may appear to be anonymous but they contain embedded personally identifiable information (PII). In this paper we present a new anonymization technique that is based on motion retargeting, utilizing adversary classifiers to further remove PII embedded in the skeleton. Motion retargeting is effective in anonymization as it transfers the movement of the user onto the a dummy skeleton. In doing so, any PII linked to the skeleton will be based on the dummy skeleton instead of the user we are protecting. We propose a Privacy-centric Deep Motion Retargeting model (PMR) which aims to further clear the retargeted skeleton of PII through adversarial learning. In our experiments, PMR achieves motion retargeting utility performance on par with state of the art models while also reducing the performance of privacy attacks.
What User Behaviors Make the Differences During the Process of Visual Analytics?
Nov 17, 2023The understanding of visual analytics process can benefit visualization researchers from multiple aspects, including improving visual designs and developing advanced interaction functions. However, the log files of user behaviors are still hard to analyze due to the complexity of sensemaking and our lack of knowledge on the related user behaviors. This work presents a study on a comprehensive data collection of user behaviors, and our analysis approach with time-series classification methods. We have chosen a classical visualization application, Covid-19 data analysis, with common analysis tasks covering geo-spatial, time-series and multi-attributes. Our user study collects user behaviors on a diverse set of visualization tasks with two comparable systems, desktop and immersive visualizations. We summarize the classification results with three time-series machine learning algorithms at two scales, and explore the influences of behavior features. Our results reveal that user behaviors can be distinguished during the process of visual analytics and there is a potentially strong association between the physical behaviors of users and the visualization tasks they perform. We also demonstrate the usage of our models by interpreting open sessions of visual analytics, which provides an automatic way to study sensemaking without tedious manual annotations.
Part Aware Contrastive Learning for Self-Supervised Action Recognition
May 11, 2023In recent years, remarkable results have been achieved in self-supervised action recognition using skeleton sequences with contrastive learning. It has been observed that the semantic distinction of human action features is often represented by local body parts, such as legs or hands, which are advantageous for skeleton-based action recognition. This paper proposes an attention-based contrastive learning framework for skeleton representation learning, called SkeAttnCLR, which integrates local similarity and global features for skeleton-based action representations. To achieve this, a multi-head attention mask module is employed to learn the soft attention mask features from the skeletons, suppressing non-salient local features while accentuating local salient features, thereby bringing similar local features closer in the feature space. Additionally, ample contrastive pairs are generated by expanding contrastive pairs based on salient and non-salient features with global features, which guide the network to learn the semantic representations of the entire skeleton. Therefore, with the attention mask mechanism, SkeAttnCLR learns local features under different data augmentation views. The experiment results demonstrate that the inclusion of local feature similarity significantly enhances skeleton-based action representation. Our proposed SkeAttnCLR outperforms state-of-the-art methods on NTURGB+D, NTU120-RGB+D, and PKU-MMD datasets.
SkeletonMAE: Spatial-Temporal Masked Autoencoders for Self-supervised Skeleton Action Recognition
Sep 01, 2022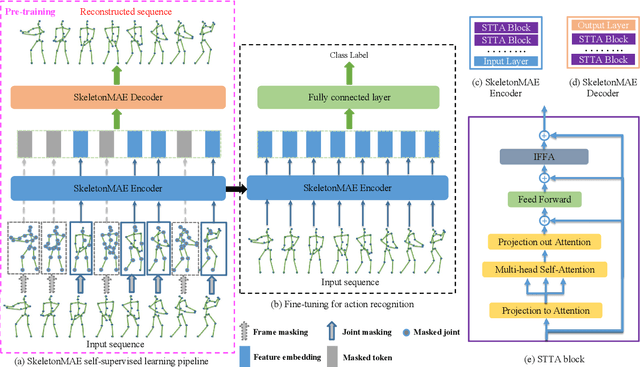
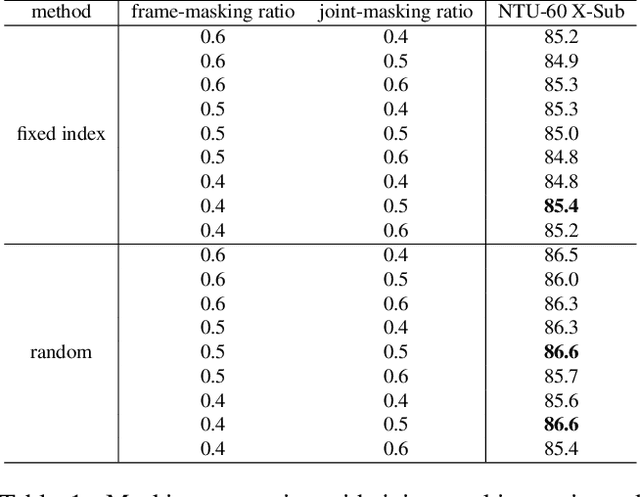
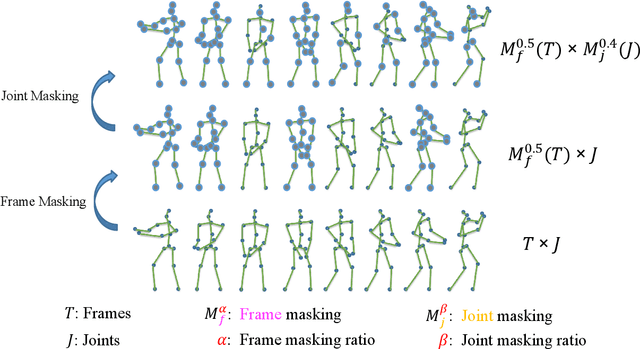
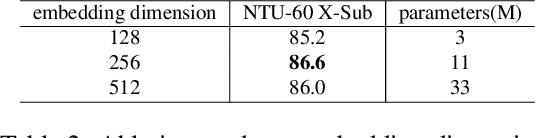
Fully supervised skeleton-based action recognition has achieved great progress with the blooming of deep learning techniques. However, these methods require sufficient labeled data which is not easy to obtain. In contrast, self-supervised skeleton-based action recognition has attracted more attention. With utilizing the unlabeled data, more generalizable features can be learned to alleviate the overfitting problem and reduce the demand of massive labeled training data. Inspired by the MAE, we propose a spatial-temporal masked autoencoder framework for self-supervised 3D skeleton-based action recognition (SkeletonMAE). Following MAE's masking and reconstruction pipeline, we utilize a skeleton based encoder-decoder transformer architecture to reconstruct the masked skeleton sequences. A novel masking strategy, named Spatial-Temporal Masking, is introduced in terms of both joint-level and frame-level for the skeleton sequence. This pre-training strategy makes the encoder output generalizable skeleton features with spatial and temporal dependencies. Given the unmasked skeleton sequence, the encoder is fine-tuned for the action recognition task. Extensive experiments show that our SkeletonMAE achieves remarkable performance and outperforms the state-of-the-art methods on both NTU RGB+D and NTU RGB+D 120 datasets.
A Lightweight Graph Transformer Network for Human Mesh Reconstruction from 2D Human Pose
Nov 24, 2021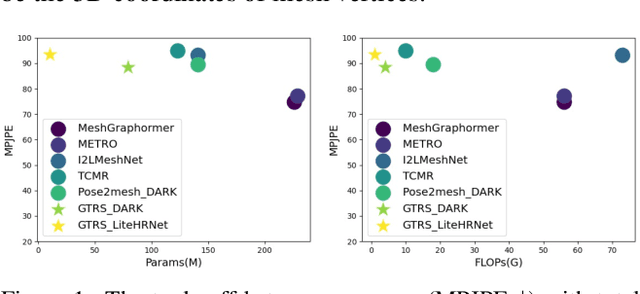
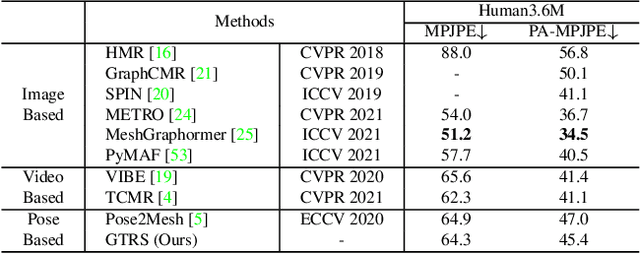
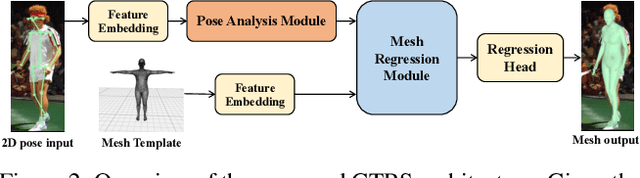
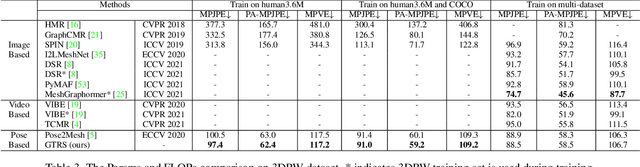
Existing deep learning-based human mesh reconstruction approaches have a tendency to build larger networks in order to achieve higher accuracy. Computational complexity and model size are often neglected, despite being key characteristics for practical use of human mesh reconstruction models (e.g. virtual try-on systems). In this paper, we present GTRS, a lightweight pose-based method that can reconstruct human mesh from 2D human pose. We propose a pose analysis module that uses graph transformers to exploit structured and implicit joint correlations, and a mesh regression module that combines the extracted pose feature with the mesh template to reconstruct the final human mesh. We demonstrate the efficiency and generalization of GTRS by extensive evaluations on the Human3.6M and 3DPW datasets. In particular, GTRS achieves better accuracy than the SOTA pose-based method Pose2Mesh while only using 10.2% of the parameters (Params) and 2.5% of the FLOPs on the challenging in-the-wild 3DPW dataset. Code will be publicly available.
Poisoning Attacks on Fair Machine Learning
Oct 17, 2021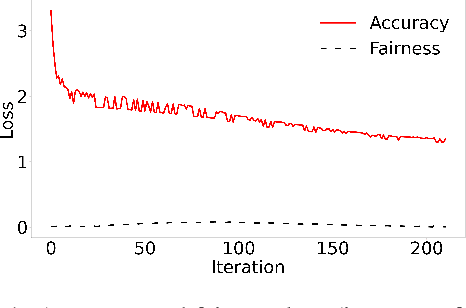
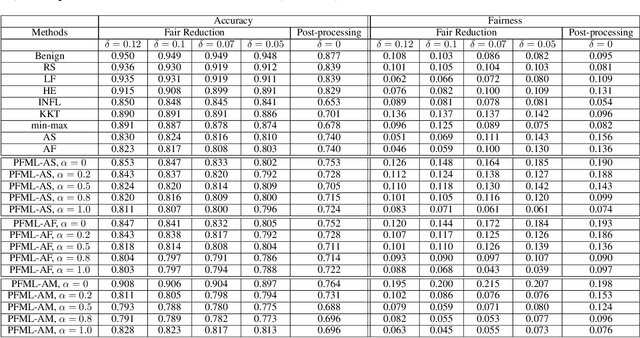
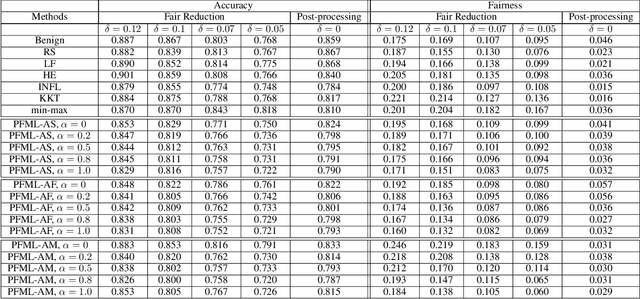
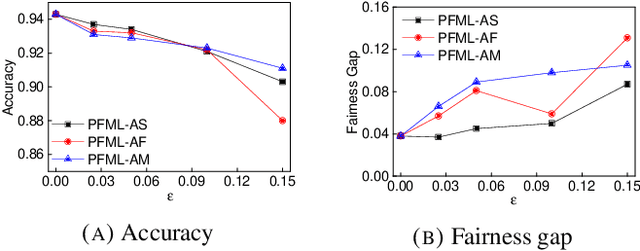
Both fair machine learning and adversarial learning have been extensively studied. However, attacking fair machine learning models has received less attention. In this paper, we present a framework that seeks to effectively generate poisoning samples to attack both model accuracy and algorithmic fairness. Our attacking framework can target fair machine learning models trained with a variety of group based fairness notions such as demographic parity and equalized odds. We develop three online attacks, adversarial sampling , adversarial labeling, and adversarial feature modification. All three attacks effectively and efficiently produce poisoning samples via sampling, labeling, or modifying a fraction of training data in order to reduce the test accuracy. Our framework enables attackers to flexibly adjust the attack's focus on prediction accuracy or fairness and accurately quantify the impact of each candidate point to both accuracy loss and fairness violation, thus producing effective poisoning samples. Experiments on two real datasets demonstrate the effectiveness and efficiency of our framework.