 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLens Privacy Sealing: A New Benchmark and Method for Physical Privacy-Preserving Action Recognition
May 21, 2026RGB camera-based surveillance systems enable human action recognition for public safety and healthcare, yet raise serious privacy concerns. Existing methods rely on post-capture algorithms, which fail to protect privacy during data acquisition. We propose Lens Privacy Sealing (LPS), a simple hardware solution that physically obscures camera lenses with adjustable laminating film, providing pre-sensor privacy protection at minimal cost. Unlike software methods or expensive engineered optics, LPS achieves strong privacy through stochastic multi-layer scattering that is physically irreversible. We introduce the P$^3$AR dataset for privacy-preserving action recognition, featuring both large-scale replay-captured (P$^3$AR-NTU, 114K videos) and real-world collected (P$^3$AR-PKU) subsets with privacy attribute annotations. To handle video degradation from LPS, we propose MSPNet, a single-stage framework incorporating Inter-Frame Noise Suppressor (IFNS) and Cross-Frame Semantic Aggregator (CFSA), enhanced by contrastive language-image pre-training for robust semantic extraction. Extensive experiments demonstrate that MSPNet with IFNS and CFSA nearly doubles action recognition accuracy compared to baseline methods while suppressing identity recognition to low levels. Comprehensive validation shows LPS achieves a superior privacy-utility trade-off compared to state-of-the-art hardware methods, resists reconstruction attacks including PSF inversion and data-driven recovery, and generalizes robustly across optical configurations and challenging environments. Code is available at https://github.com/wangzy01/MSPNet.
DAP: Doppler-aware Point Network for Heterogeneous mmWave Action Recognition
May 10, 2026Millimeter-wave (mmWave) radar provides privacy-preserving sensing and is valuable for human action recognition (HAR). Existing mmWave point cloud datasets are limited in scale and mostly collected under homogeneous single-source settings, preventing current methods from handling real-world distribution shifts caused by heterogeneous radar sources, such as different devices and frequency bands. To address this, we introduce UniMM-HAR, the largest and first mmWave point cloud HAR dataset for heterogeneous multi-source scenarios, standardizing three distinct radar configurations to realistically evaluate cross-source generalization. We further propose the Doppler-aware Point Cloud Network (DAP-Net) to tackle heterogeneity challenges. DAP-Net enhances intra-modal representations and performs cross-modal alignment to learn source-invariant action semantics. Leveraging action-consistent spatio-temporal Doppler patterns as anchors, the Dual-space Doppler Reparameterization (D2R) module performs sample-adaptive geometric densification and Doppler-guided feature recalibration, while the Text Alignment Module (TAM) provides stable semantic anchors via a pretrained textual space. Experiments show that DAP-Net significantly outperforms existing methods under heterogeneous radar settings, achieving state-of-the-art accuracy and strong cross-source robustness.
UniMotion: A Unified Framework for Motion-Text-Vision Understanding and Generation
Mar 23, 2026We present UniMotion, to our knowledge the first unified framework for simultaneous understanding and generation of human motion, natural language, and RGB images within a single architecture. Existing unified models handle only restricted modality subsets (e.g., Motion-Text or static Pose-Image) and predominantly rely on discrete tokenization, which introduces quantization errors and disrupts temporal continuity. UniMotion overcomes both limitations through a core principle: treating motion as a first-class continuous modality on equal footing with RGB. A novel Cross-Modal Aligned Motion VAE (CMA-VAE) and symmetric dual-path embedders construct parallel continuous pathways for Motion and RGB within a shared LLM backbone. To inject visual-semantic priors into motion representations without requiring images at inference, we propose Dual-Posterior KL Alignment (DPA), which distills a vision-fused encoder's richer posterior into the motion-only encoder. To address the cold-start problem -- where text supervision alone is too sparse to calibrate the newly introduced motion pathway -- we further propose Latent Reconstruction Alignment (LRA), a self-supervised pre-training strategy that uses dense motion latents as unambiguous conditions to co-calibrate the embedder, backbone, and flow head, establishing a stable motion-aware foundation for all downstream tasks. UniMotion achieves state-of-the-art performance across seven tasks spanning any-to-any understanding, generation, and editing among the three modalities, with especially strong advantages on cross-modal compositional tasks.
Universal Skeleton Understanding via Differentiable Rendering and MLLMs
Mar 18, 2026Multimodal large language models (MLLMs) exhibit strong visual-language reasoning, yet remain confined to their native modalities and cannot directly process structured, non-visual data such as human skeletons. Existing methods either compress skeleton dynamics into lossy feature vectors for text alignment, or quantize motion into discrete tokens that generalize poorly across heterogeneous skeleton formats. We present SkeletonLLM, which achieves universal skeleton understanding by translating arbitrary skeleton sequences into the MLLM's native visual modality. At its core is DrAction, a differentiable, format-agnostic renderer that converts skeletal kinematics into compact image sequences. Because the pipeline is end-to-end differentiable, MLLM gradients can directly guide the rendering to produce task-informative visual tokens. To further enhance reasoning capabilities, we introduce a cooperative training strategy: Causal Reasoning Distillation transfers structured, step-by-step reasoning from a teacher model, while Discriminative Finetuning sharpens decision boundaries between confusable actions. SkeletonLLM demonstrates strong generalization on diverse tasks including recognition, captioning, reasoning, and cross-format transfer -- suggesting a viable path for applying MLLMs to non-native modalities. Code will be released upon acceptance.
Language-Guided Transformer Tokenizer for Human Motion Generation
Feb 09, 2026In this paper, we focus on motion discrete tokenization, which converts raw motion into compact discrete tokens--a process proven crucial for efficient motion generation. In this paradigm, increasing the number of tokens is a common approach to improving motion reconstruction quality, but more tokens make it more difficult for generative models to learn. To maintain high reconstruction quality while reducing generation complexity, we propose leveraging language to achieve efficient motion tokenization, which we term Language-Guided Tokenization (LG-Tok). LG-Tok aligns natural language with motion at the tokenization stage, yielding compact, high-level semantic representations. This approach not only strengthens both tokenization and detokenization but also simplifies the learning of generative models. Furthermore, existing tokenizers predominantly adopt convolutional architectures, whose local receptive fields struggle to support global language guidance. To this end, we propose a Transformer-based Tokenizer that leverages attention mechanisms to enable effective alignment between language and motion. Additionally, we design a language-drop scheme, in which language conditions are randomly removed during training, enabling the detokenizer to support language-free guidance during generation. On the HumanML3D and Motion-X generation benchmarks, LG-Tok achieves Top-1 scores of 0.542 and 0.582, outperforming state-of-the-art methods (MARDM: 0.500 and 0.528), and with FID scores of 0.057 and 0.088, respectively, versus 0.114 and 0.147. LG-Tok-mini uses only half the tokens while maintaining competitive performance (Top-1: 0.521/0.588, FID: 0.085/0.071), validating the efficiency of our semantic representations.
Human Identification at a Distance: Challenges, Methods and Results on the Competition HID 2025
Feb 07, 2026Human identification at a distance (HID) is challenging because traditional biometric modalities such as face and fingerprints are often difficult to acquire in real-world scenarios. Gait recognition provides a practical alternative, as it can be captured reliably at a distance. To promote progress in gait recognition and provide a fair evaluation platform, the International Competition on Human Identification at a Distance (HID) has been organized annually since 2020. Since 2023, the competition has adopted the challenging SUSTech-Competition dataset, which features substantial variations in clothing, carried objects, and view angles. No dedicated training data are provided, requiring participants to train their models using external datasets. Each year, the competition applies a different random seed to generate distinct evaluation splits, which reduces the risk of overfitting and supports a fair assessment of cross-domain generalization. While HID 2023 and HID 2024 already used this dataset, HID 2025 explicitly examined whether algorithmic advances could surpass the accuracy limits observed previously. Despite the heightened difficulty, participants achieved further improvements, and the best-performing method reached 94.2% accuracy, setting a new benchmark on this dataset. We also analyze key technical trends and outline potential directions for future research in gait recognition.
Superman: Unifying Skeleton and Vision for Human Motion Perception and Generation
Feb 02, 2026Human motion analysis tasks, such as temporal 3D pose estimation, motion prediction, and motion in-betweening, play an essential role in computer vision. However, current paradigms suffer from severe fragmentation. First, the field is split between ``perception'' models that understand motion from video but only output text, and ``generation'' models that cannot perceive from raw visual input. Second, generative MLLMs are often limited to single-frame, static poses using dense, parametric SMPL models, failing to handle temporal motion. Third, existing motion vocabularies are built from skeleton data alone, severing the link to the visual domain. To address these challenges, we introduce Superman, a unified framework that bridges visual perception with temporal, skeleton-based motion generation. Our solution is twofold. First, to overcome the modality disconnect, we propose a Vision-Guided Motion Tokenizer. Leveraging the natural geometric alignment between 3D skeletons and visual data, this module pioneers robust joint learning from both modalities, creating a unified, cross-modal motion vocabulary. Second, grounded in this motion language, a single, unified MLLM architecture is trained to handle all tasks. This module flexibly processes diverse, temporal inputs, unifying 3D skeleton pose estimation from video (perception) with skeleton-based motion prediction and in-betweening (generation). Extensive experiments on standard benchmarks, including Human3.6M, demonstrate that our unified method achieves state-of-the-art or competitive performance across all motion tasks. This showcases a more efficient and scalable path for generative motion analysis using skeletons.
Trustworthy Evaluation of Robotic Manipulation: A New Benchmark and AutoEval Methods
Jan 26, 2026Driven by the rapid evolution of Vision-Action and Vision-Language-Action models, imitation learning has significantly advanced robotic manipulation capabilities. However, evaluation methodologies have lagged behind, hindering the establishment of Trustworthy Evaluation for these behaviors. Current paradigms rely on binary success rates, failing to address the critical dimensions of trust: Source Authenticity (i.e., distinguishing genuine policy behaviors from human teleoperation) and Execution Quality (e.g., smoothness and safety). To bridge these gaps, we propose a solution that combines the Eval-Actions benchmark and the AutoEval architecture. First, we construct the Eval-Actions benchmark to support trustworthiness analysis. Distinct from existing datasets restricted to successful human demonstrations, Eval-Actions integrates VA and VLA policy execution trajectories alongside human teleoperation data, explicitly including failure scenarios. This dataset is structured around three core supervision signals: Expert Grading (EG), Rank-Guided preferences (RG), and Chain-of-Thought (CoT). Building on this, we propose the AutoEval architecture: AutoEval leverages Spatio-Temporal Aggregation for semantic assessment, augmented by an auxiliary Kinematic Calibration Signal to refine motion smoothness; AutoEval Plus (AutoEval-P) incorporates the Group Relative Policy Optimization (GRPO) paradigm to enhance logical reasoning capabilities. Experiments show AutoEval achieves Spearman's Rank Correlation Coefficients (SRCC) of 0.81 and 0.84 under the EG and RG protocols, respectively. Crucially, the framework possesses robust source discrimination capabilities, distinguishing between policy-generated and teleoperated videos with 99.6% accuracy, thereby establishing a rigorous standard for trustworthy robotic evaluation. Our project and code are available at https://term-bench.github.io/.
PoseMoE: Mixture-of-Experts Network for Monocular 3D Human Pose Estimation
Dec 18, 2025The lifting-based methods have dominated monocular 3D human pose estimation by leveraging detected 2D poses as intermediate representations. The 2D component of the final 3D human pose benefits from the detected 2D poses, whereas its depth counterpart must be estimated from scratch. The lifting-based methods encode the detected 2D pose and unknown depth in an entangled feature space, explicitly introducing depth uncertainty to the detected 2D pose, thereby limiting overall estimation accuracy. This work reveals that the depth representation is pivotal for the estimation process. Specifically, when depth is in an initial, completely unknown state, jointly encoding depth features with 2D pose features is detrimental to the estimation process. In contrast, when depth is initially refined to a more dependable state via network-based estimation, encoding it together with 2D pose information is beneficial. To address this limitation, we present a Mixture-of-Experts network for monocular 3D pose estimation named PoseMoE. Our approach introduces: (1) A mixture-of-experts network where specialized expert modules refine the well-detected 2D pose features and learn the depth features. This mixture-of-experts design disentangles the feature encoding process for 2D pose and depth, therefore reducing the explicit influence of uncertain depth features on 2D pose features. (2) A cross-expert knowledge aggregation module is proposed to aggregate cross-expert spatio-temporal contextual information. This step enhances features through bidirectional mapping between 2D pose and depth. Extensive experiments show that our proposed PoseMoE outperforms the conventional lifting-based methods on three widely used datasets: Human3.6M, MPI-INF-3DHP, and 3DPW.
KLO-Net: A Dynamic K-NN Attention U-Net with CSP Encoder for Efficient Prostate Gland Segmentation from MRI
Dec 15, 2025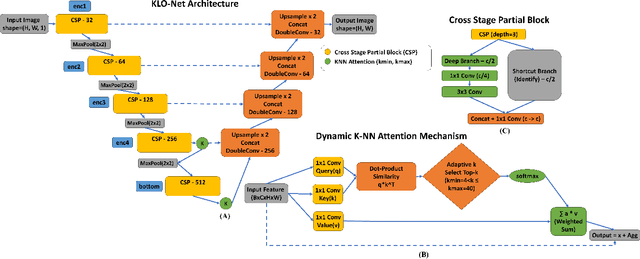

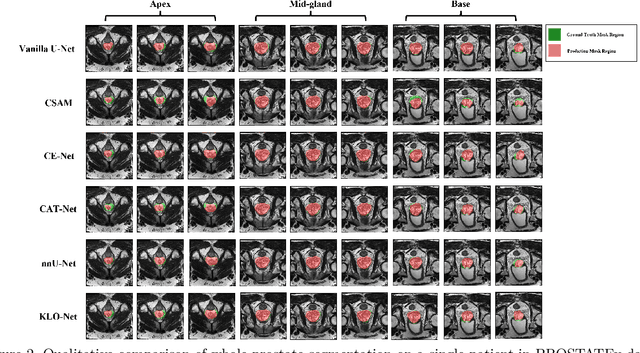
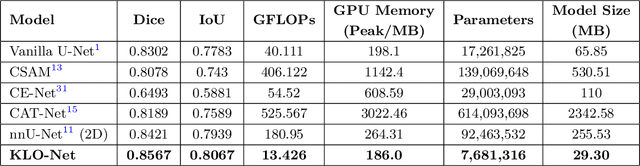
Real-time deployment of prostate MRI segmentation on clinical workstations is often bottlenecked by computational load and memory footprint. Deep learning-based prostate gland segmentation approaches remain challenging due to anatomical variability. To bridge this efficiency gap while still maintaining reliable segmentation accuracy, we propose KLO-Net, a dynamic K-Nearest Neighbor attention U-Net with Cross Stage Partial, i.e., CSP, encoder for efficient prostate gland segmentation from MRI scan. Unlike the regular K-NN attention mechanism, the proposed dynamic K-NN attention mechanism allows the model to adaptively determine the number of attention connections for each spatial location within a slice. In addition, CSP blocks address the computational load to reduce memory consumption. To evaluate the model's performance, comprehensive experiments and ablation studies are conducted on two public datasets, i.e., PROMISE12 and PROSTATEx, to validate the proposed architecture. The detailed comparative analysis demonstrates the model's advantage in computational efficiency and segmentation quality.