 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOLion: Approaching the Hadamard Ideal by Intersecting Spectral and $\ell_{\infty}$ Implicit Biases
Feb 01, 2026Many optimizers can be interpreted as steepest-descent methods under norm-induced geometries, and thus inherit corresponding implicit biases. We introduce \nameA{} (\fullname{}), which combines spectral control from orthogonalized update directions with $\ell_\infty$-style coordinate control from sign updates. \nameA{} forms a Lion-style momentum direction, approximately orthogonalizes it via a few Newton--Schulz iterations, and then applies an entrywise sign, providing an efficient approximation to taking a maximal step over the intersection of the spectral and $\ell_\infty$ constraint sets (a scaled Hadamard-like set for matrix parameters). Despite the strong nonlinearity of orthogonalization and sign, we prove convergence under a mild, empirically verified diagonal-isotropy assumption. Across large-scale language and vision training, including GPT-2 and Llama pretraining, SiT image pretraining, and supervised fine-tuning, \nameA{} matches or outperforms AdamW and Muon under comparable tuning while using only momentum-level optimizer state, and it mitigates optimizer mismatch when fine-tuning AdamW-pretrained checkpoints.
RoboBrain 2.5: Depth in Sight, Time in Mind
Jan 20, 2026We introduce RoboBrain 2.5, a next-generation embodied AI foundation model that advances general perception, spatial reasoning, and temporal modeling through extensive training on high-quality spatiotemporal supervision. Building upon its predecessor, RoboBrain 2.5 introduces two major capability upgrades. Specifically, it unlocks Precise 3D Spatial Reasoning by shifting from 2D pixel-relative grounding to depth-aware coordinate prediction and absolute metric constraint comprehension, generating complete 3D manipulation traces as ordered keypoint sequences under physical constraints. Complementing this spatial precision, the model establishes Dense Temporal Value Estimation that provides dense, step-aware progress prediction and execution state understanding across varying viewpoints, producing stable feedback signals for downstream learning. Together, these upgrades extend the framework toward more physically grounded and execution-aware embodied intelligence for complex, fine-grained manipulation. The code and checkpoints are available at project website: https://superrobobrain.github.io
Robo-Dopamine: General Process Reward Modeling for High-Precision Robotic Manipulation
Dec 29, 2025The primary obstacle for applying reinforcement learning (RL) to real-world robotics is the design of effective reward functions. While recently learning-based Process Reward Models (PRMs) are a promising direction, they are often hindered by two fundamental limitations: their reward models lack step-aware understanding and rely on single-view perception, leading to unreliable assessments of fine-grained manipulation progress; and their reward shaping procedures are theoretically unsound, often inducing a semantic trap that misguides policy optimization. To address these, we introduce Dopamine-Reward, a novel reward modeling method for learning a general-purpose, step-aware process reward model from multi-view inputs. At its core is our General Reward Model (GRM), trained on a vast 3,400+ hour dataset, which leverages Step-wise Reward Discretization for structural understanding and Multi-Perspective Reward Fusion to overcome perceptual limitations. Building upon Dopamine-Reward, we propose Dopamine-RL, a robust policy learning framework that employs a theoretically-sound Policy-Invariant Reward Shaping method, which enables the agent to leverage dense rewards for efficient self-improvement without altering the optimal policy, thereby fundamentally avoiding the semantic trap. Extensive experiments across diverse simulated and real-world tasks validate our approach. GRM achieves state-of-the-art accuracy in reward assessment, and Dopamine-RL built on GRM significantly improves policy learning efficiency. For instance, after GRM is adapted to a new task in a one-shot manner from a single expert trajectory, the resulting reward model enables Dopamine-RL to improve the policy from near-zero to 95% success with only 150 online rollouts (approximately 1 hour of real robot interaction), while retaining strong generalization across tasks. Project website: https://robo-dopamine.github.io
MedKGent: A Large Language Model Agent Framework for Constructing Temporally Evolving Medical Knowledge Graph
Aug 17, 2025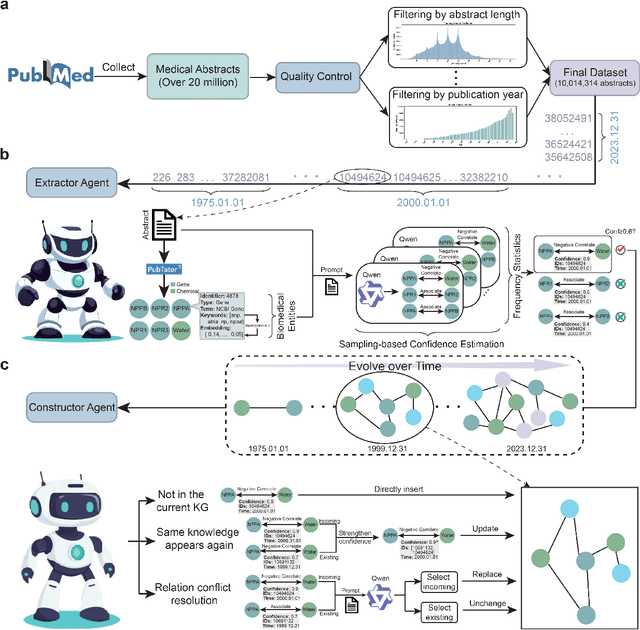
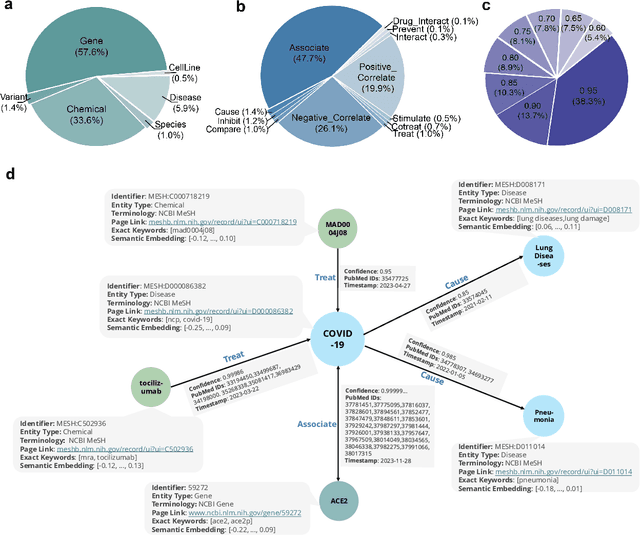
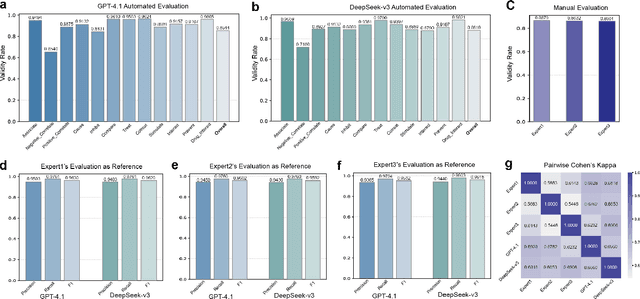
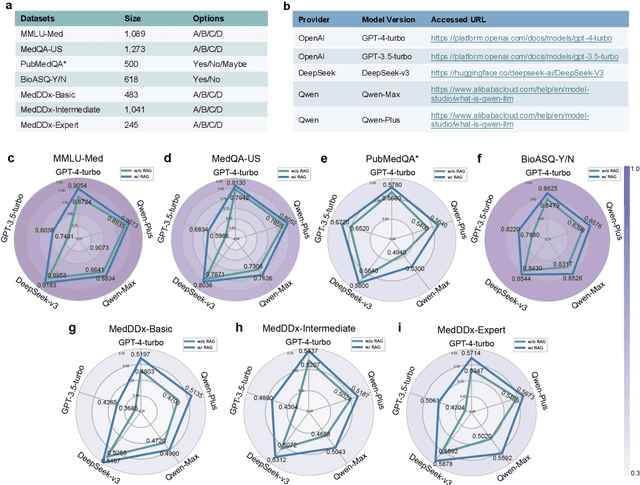
The rapid expansion of medical literature presents growing challenges for structuring and integrating domain knowledge at scale. Knowledge Graphs (KGs) offer a promising solution by enabling efficient retrieval, automated reasoning, and knowledge discovery. However, current KG construction methods often rely on supervised pipelines with limited generalizability or naively aggregate outputs from Large Language Models (LLMs), treating biomedical corpora as static and ignoring the temporal dynamics and contextual uncertainty of evolving knowledge. To address these limitations, we introduce MedKGent, a LLM agent framework for constructing temporally evolving medical KGs. Leveraging over 10 million PubMed abstracts published between 1975 and 2023, we simulate the emergence of biomedical knowledge via a fine-grained daily time series. MedKGent incrementally builds the KG in a day-by-day manner using two specialized agents powered by the Qwen2.5-32B-Instruct model. The Extractor Agent identifies knowledge triples and assigns confidence scores via sampling-based estimation, which are used to filter low-confidence extractions and inform downstream processing. The Constructor Agent incrementally integrates the retained triples into a temporally evolving graph, guided by confidence scores and timestamps to reinforce recurring knowledge and resolve conflicts. The resulting KG contains 156,275 entities and 2,971,384 relational triples. Quality assessments by two SOTA LLMs and three domain experts demonstrate an accuracy approaching 90\%, with strong inter-rater agreement. To evaluate downstream utility, we conduct RAG across seven medical question answering benchmarks using five leading LLMs, consistently observing significant improvements over non-augmented baselines. Case studies further demonstrate the KG's value in literature-based drug repurposing via confidence-aware causal inference.
Test-Time Scaling with Reflective Generative Model
Jul 02, 2025We introduce our first reflective generative model MetaStone-S1, which obtains OpenAI o3's performance via the self-supervised process reward model (SPRM). Through sharing the backbone network and using task-specific heads for next token prediction and process scoring respectively, SPRM successfully integrates the policy model and process reward model(PRM) into a unified interface without extra process annotation, reducing over 99% PRM parameters for efficient reasoning. Equipped with SPRM, MetaStone-S1 is naturally suitable for test time scaling (TTS), and we provide three reasoning effort modes (low, medium, and high), based on the controllable thinking length. Moreover, we empirically establish a scaling law that reveals the relationship between total thinking computation and TTS performance. Experiments demonstrate that our MetaStone-S1 achieves comparable performance to OpenAI-o3-mini's series with only 32B parameter size. To support the research community, we have open-sourced MetaStone-S1 at https://github.com/MetaStone-AI/MetaStone-S1.
DiffPattern-Flex: Efficient Layout Pattern Generation via Discrete Diffusion
May 07, 2025Recent advancements in layout pattern generation have been dominated by deep generative models. However, relying solely on neural networks for legality guarantees raises concerns in many practical applications. In this paper, we present \tool{DiffPattern}-Flex, a novel approach designed to generate reliable layout patterns efficiently. \tool{DiffPattern}-Flex incorporates a new method for generating diverse topologies using a discrete diffusion model while maintaining a lossless and compute-efficient layout representation. To ensure legal pattern generation, we employ {an} optimization-based, white-box pattern assessment process based on specific design rules. Furthermore, fast sampling and efficient legalization technologies are employed to accelerate the generation process. Experimental results across various benchmarks demonstrate that \tool{DiffPattern}-Flex significantly outperforms existing methods and excels at producing reliable layout patterns.
Can A Society of Generative Agents Simulate Human Behavior and Inform Public Health Policy? A Case Study on Vaccine Hesitancy
Mar 12, 2025Can we simulate a sandbox society with generative agents to model human behavior, thereby reducing the over-reliance on real human trials for assessing public policies? In this work, we investigate the feasibility of simulating health-related decision-making, using vaccine hesitancy, defined as the delay in acceptance or refusal of vaccines despite the availability of vaccination services (MacDonald, 2015), as a case study. To this end, we introduce the VacSim framework with 100 generative agents powered by Large Language Models (LLMs). VacSim simulates vaccine policy outcomes with the following steps: 1) instantiate a population of agents with demographics based on census data; 2) connect the agents via a social network and model vaccine attitudes as a function of social dynamics and disease-related information; 3) design and evaluate various public health interventions aimed at mitigating vaccine hesitancy. To align with real-world results, we also introduce simulation warmup and attitude modulation to adjust agents' attitudes. We propose a series of evaluations to assess the reliability of various LLM simulations. Experiments indicate that models like Llama and Qwen can simulate aspects of human behavior but also highlight real-world alignment challenges, such as inconsistent responses with demographic profiles. This early exploration of LLM-driven simulations is not meant to serve as definitive policy guidance; instead, it serves as a call for action to examine social simulation for policy development.
Beyond Profile: From Surface-Level Facts to Deep Persona Simulation in LLMs
Feb 18, 2025Previous approaches to persona simulation large language models (LLMs) have typically relied on learning basic biographical information, or using limited role-play dialogue datasets to capture a character's responses. However, a holistic representation of an individual goes beyond surface-level facts or conversations to deeper thoughts and thinking. In this work, we introduce CharacterBot, a model designed to replicate both the linguistic patterns and distinctive thought processes of a character. Using Lu Xun, a renowned Chinese writer, as a case study, we propose four training tasks derived from his 17 essay collections. These include a pre-training task focused on mastering external linguistic structures and knowledge, as well as three fine-tuning tasks: multiple-choice question answering, generative question answering, and style transfer, each aligning the LLM with Lu Xun's internal ideation and writing style. To optimize learning across these tasks, we introduce a CharLoRA parameter updating mechanism, where a general linguistic style expert collaborates with other task-specific experts to better study both the language style and the understanding of deeper thoughts. We evaluate CharacterBot on three tasks for linguistic accuracy and opinion comprehension, demonstrating that it significantly outperforms the baselines on our adapted metrics. We hope that this work inspires future research on deep character persona simulation LLM.
Refining Positive and Toxic Samples for Dual Safety Self-Alignment of LLMs with Minimal Human Interventions
Feb 08, 2025Recent AI agents, such as ChatGPT and LLaMA, primarily rely on instruction tuning and reinforcement learning to calibrate the output of large language models (LLMs) with human intentions, ensuring the outputs are harmless and helpful. Existing methods heavily depend on the manual annotation of high-quality positive samples, while contending with issues such as noisy labels and minimal distinctions between preferred and dispreferred response data. However, readily available toxic samples with clear safety distinctions are often filtered out, removing valuable negative references that could aid LLMs in safety alignment. In response, we propose PT-ALIGN, a novel safety self-alignment approach that minimizes human supervision by automatically refining positive and toxic samples and performing fine-grained dual instruction tuning. Positive samples are harmless responses, while toxic samples deliberately contain extremely harmful content, serving as a new supervisory signals. Specifically, we utilize LLM itself to iteratively generate and refine training instances by only exploring fewer than 50 human annotations. We then employ two losses, i.e., maximum likelihood estimation (MLE) and fine-grained unlikelihood training (UT), to jointly learn to enhance the LLM's safety. The MLE loss encourages an LLM to maximize the generation of harmless content based on positive samples. Conversely, the fine-grained UT loss guides the LLM to minimize the output of harmful words based on negative samples at the token-level, thereby guiding the model to decouple safety from effectiveness, directing it toward safer fine-tuning objectives, and increasing the likelihood of generating helpful and reliable content. Experiments on 9 popular open-source LLMs demonstrate the effectiveness of our PT-ALIGN for safety alignment, while maintaining comparable levels of helpfulness and usefulness.
FlexPose: Pose Distribution Adaptation with Limited Guidance
Dec 18, 2024



Numerous well-annotated human key-point datasets are publicly available to date. However, annotating human poses for newly collected images is still a costly and time-consuming progress. Pose distributions from different datasets share similar pose hinge-structure priors with different geometric transformations, such as pivot orientation, joint rotation, and bone length ratio. The difference between Pose distributions is essentially the difference between the transformation distributions. Inspired by this fact, we propose a method to calibrate a pre-trained pose generator in which the pose prior has already been learned to an adapted one following a new pose distribution. We treat the representation of human pose joint coordinates as skeleton image and transfer a pre-trained pose annotation generator with only a few annotation guidance. By fine-tuning a limited number of linear layers that closely related to the pose transformation, the adapted generator is able to produce any number of pose annotations that are similar to the target poses. We evaluate our proposed method, FlexPose, on several cross-dataset settings both qualitatively and quantitatively, which demonstrates that our approach achieves state-of-the-art performance compared to the existing generative-model-based transfer learning methods when given limited annotation guidance.